Nice job @strickvl ! Got a tweet I can share?
2 Likes
re:1
There are some tricks you can apply to make things a bit more manageable when you have limited compute (e.g., smaller batch sizes, gradient accumulation, using distilled models, training only the last layer rather than whole model).
re:2
Check out Longformer and Reformer for transformer architectures that allow for bigger sequences, and also consider breaking long sequences into multiple examples (requires some post processing but nothing too crazy)
Cool work btw. I love seeing how computer vision models can be applied to non image datasets.
3 Likes
1 Like
Possibly something I’m doing wrong again with the sequence length here, and also possibly I just don’t have enough data to make this work well, but when I follow through with the RNN style of training a language model (as shown in chapter 10 of the book) it is MUCH faster + needs less RAM but only modestly ok results. Not really sure how to interpret what I did or achieved here, either. ![]()
As you can imagine, my texts are derived from an OCR process and thus are super unclean, so I would think it’s highly likely that a pre-trained model that has seen lots of ‘real’ texts will have trouble with this OCR garble that often even I have trouble understanding…
I think I’ll transition to trying to find a more ‘sensible’ NLP task instead of trying to beat this example to death. Seems like maybe it’s the wrong problem / text length and I’m reluctant to go too much down the Longformer rabbit hole etc for a problem that I’ve already ‘solved’ with the computer vision approach and that I am not super motivated to finding creative solutions for.
4 Likes
Thanks for sharing. Personally, I think 87% accuracy is not bad at all! But then again, it all depends on what your business case demands. Maybe it can get by just fine with anything above 85% accuracy? Or is there a baseline accuracy above which it would be ‘usable’ in its intended ‘end use scenario’?
Also , this gave me an idea, that since transformers are good at picking out missing words/tokens, would it make sense to run a spell check on the OCR text , identify the ‘badly’ OCR’d tokens and just turn them into blanks, then feed that text to a transformer and let it guess what the missing token/word should be?
Yeah 87% isn’t bad but I had 96% accuracy with a computer vision model on the same task / problem.
My gut feeling was that removing the raw OCR gunk might be equivalent to removing the signal from the text data completely.
1 Like
Hi fastai team,
I am behind working through stuff from sessions 1 & 2. I got a fast pages blog setup, and my first model deployed to Hugging Face that converts an audio wav file to Mel spectrograms and achieves ~95% accuracy on a 10 class Urban Sounds dataset.
My hugging face link is here, and my hello world on fastpages with a jupyter notebook.
Research with this dataset as of 2019 and optimized ML approaches as of late 2019 had classification accuracy at 74% with a k-nearest neighbours (KNN) algorithm. A Resnet34 with three epochs gets this accuracy much higher.
All code associated in repos all public.
Thanks,
Joe
8 Likes
It’s a good idea to get a “human baseline”. Try classifying a few yourself manually. See what accuracy you get using the exact same information the model has available.
5 Likes
Added VS Code as a default option along with JupyterLab with no setup required in Jarvislabs.ai instances.

Just click on the VS code logo and start exploring the code ![]() .
.
I am also wondering about the right place for placing the VS Code button, would love to hear any recommendations.
10 Likes
I’ve been working through Chapter 4 using the Fashion MNIST dataset, just like in @strickvl’s excellent blog posts; except I’m trying to classify all 10 types of image (using the ideas from chapter 5)

I used fastai to train a simple neural network 3 times; first using the tabular_learner from Chapter 1, then using only the fastai Learner and SGD optimizer, and finally just using PyTorch.
Interestingly each time I rewrote the model its performance at 5 epochs got worse, so there’s something that fastai is doing that I’m missing in my implementation each time. Even the best model I could train doesn’t beat a K Nearest Neighbours baseline (similar to the baseline from chapter 4) of 86%. Next I want to see if I can get the handwritten code to perform as well as fastai, and looking into Convolutional Neural Networks to see if I can get a better result.
4 Likes
Love to see it being helpful already ![]() .
.
1 Like
I thought of sharing my notes, while I attend the lectures. It covers, some of the things which I felt were highlights of the lesson 4.
Also I tried out working on a different dataset quickly with transformers library and I have shared code and output in the below blog post:
I would like to thank everyone in #delft-fastai meetup and especially @strickvl for being so inspiring.
4 Likes
After spending numerous hours scraping data and otherwise tinkering, I’m sharing a rough prototype of simple Resnet34 models that can be used to help during the recycling process. These are not perfect, but serve as proof of concept. There are two early stages in the recycling process: presort to remove all objects that can damage the recycling equipment and then sort the recyclables. The idea is to build a computer vision model for each of the stages. Perhaps Stage 1 model could make the staff’s work safer by first having robots remove all objects about which they are reasonably certain. The main step for making the model better is getting better data, and other steps are in the README file on Github. If you look at it, please let me know what else can be done so that I can use these suggestions on future projects. Also, I had problems deploying a Tabbed Gradio Interface (one tab for each stage) on Huggingface, so in terms of visual presentation, figuring this out would lead to an improvement.
stage 1 recycling
stage 2 recycling
12 Likes
You might find this interesting:
I have played around with these models for similar reasons. The issue usually is that the data used is not from ‘real world’ , so when a vision model encounters an item on a conveyor, it’s in terrible shape as it’s been through the wringer (literally sometimes) and therefore it doesn’t look as nice as most of the data available. This is the reason I like the taco dataset. One thing I think could be really helpful is if the recycling facilities shared video streams of their materials to projects like tacodataset.org because this stuff needs to be recognized in its ‘natural habitate’ as it were.
3 Likes
I’ve seen a great notebook about Random Forests created by Jeremy, and it reminded my some old post of mine on a similar topic. Not sure if it adds any additional value to what is presented during lessons, but could be one additional point of view on the problem. The post is about building a simplistic Random Forest classifier in NumPy and applying it to UCL Wine and Wrist-worn Accelerometer datasets. Some illustrations and code included.
TL;DR Also, if you prefer to jump straight to the code, there is a repo. You can also find this link in the post.
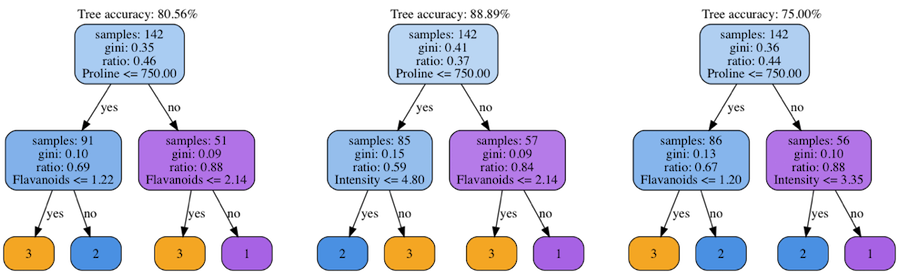
An ensemble of wine classification forests testing the implementation’s correctness.
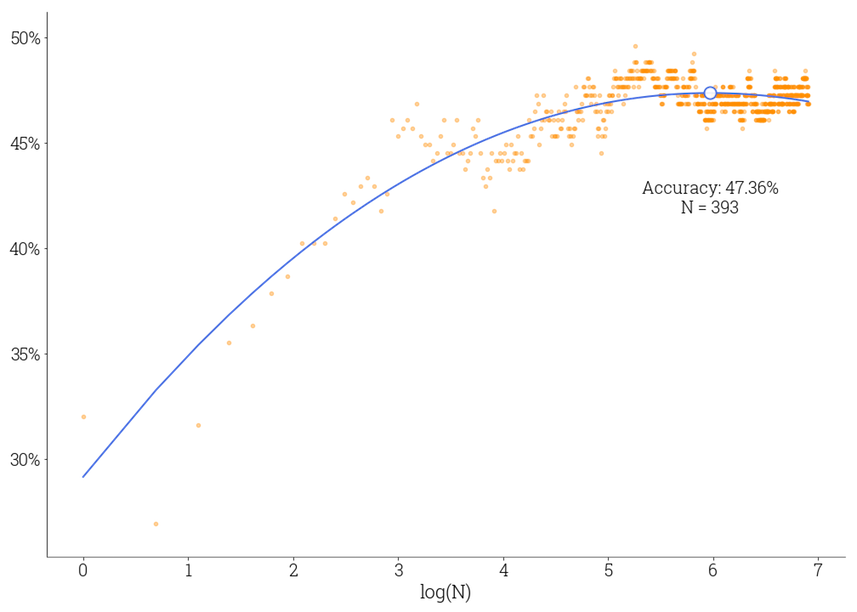
Picking the best ensemble’s size when trained on the accelerometer dataset.
As an outcome, you’ll be able to run the following snippet.
Note that we don’t use
scikit-learnfor any ML-related logic but solely for the purpose of train/test split which is easily replacable as well. All other modules likedecision_treeandensembleincluded into the repo.
from os.path import join
import numpy as np
from sklearn.model_selection import train_test_split
from quantization import quantize
from decision_tree import learn_tree
from decision_tree import predict_tree
from ensemble import RandomForestClassifier
from utils import train_test_split, encode_labels
def main():
n_clusters = 5
dataset_path = join('datasets', 'adl')
X, labels = quantize(dataset_path, n_clusters)
y, encoder, classes = encode_labels(labels)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7)
random_forest = RandomForestClassifier(
tree_funcs=(learn_tree, predict_tree),
n_trees=50, max_depth=3, min_leaf_size=5,
min_split_size=10, feature_subset_size='sqrt')
preds = random_forest.fit(X_train, y_train).predict(X_test)
acc = np.mean(preds == y_test)
print(f'Accelerometer dataset accuracy: {acc:2.2%}')
It is not a full-featured implementation, of course. Also, not sure if it is completely bug-free or not. (I tried to compare it with the “real” implementation from scikit-learn and it seemed to be reasonable in terms of accuracy.)
5 Likes
Thank you, Mike! You are right about the data scraped from the internet being a bit too neat, and TACO looks like a great dataset for experiments I would like to do in near future!
1 Like
Another Kaggle NLP competition has launched! If you want to practice your NLP skills, this is the best time ![]()
This new competition is focused on providing quality score for different “discourse elements” in student essays in hopes of developing an automated feedback tool for 6-12th grade students.
Inspired by Jeremy’s amazing NLP notebooks, I have put together an exploratory data analysis and DeBERTa baseline notebook. Currently, the baseline is the top of the leaderboard, but I suspect that won’t be the case for too long ![]() . Hope to see some fastai folks up there soon
. Hope to see some fastai folks up there soon ![]()
Check it out, and give it an upvote if you find it helpful ![]()
I have also shared on Twitter:
9 Likes
If only one could compete with twenty teams…
3 Likes
![]() New post alert!
New post alert! ![]()
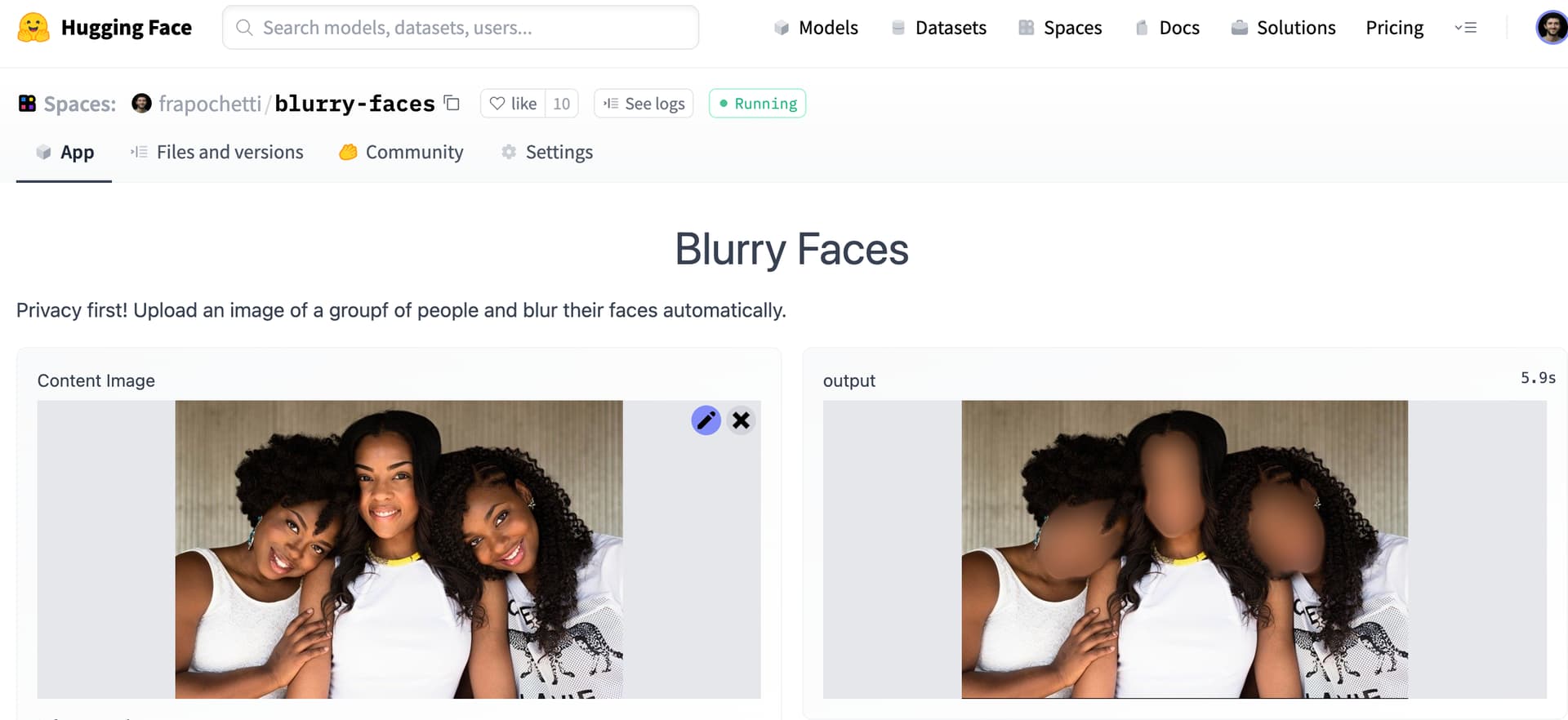
How about a UNET segmentation model converted to TensorRT and running at 16ms latency on NVIDIA Triton and Amazon SageMaker?
That was a mouthful. You better keep reading.
This one has been in the making for some time.
It all started with Clement Delangue’s tweet about automatically blurring faces when posting a picture of a crowd. Lots of progress since then.
I got going with off-the-shelf face detection algos but visuals were far from being appealing. Hence I shifted gears and trained a face mask segmentation model from scratch. Way better results!
In this post you’ll learn:
- Train an image segmentation model (UNET) using IceVision and a sample of the FaceSynthetics dataset from Microsoft.
- Convert UNET to TorchScript.
- Deploy TorchScript to HuggingFace Spaces.
- Deploy TorchScript to an Amazon SageMaker real-time endpoint. This will be the model we’ll benchmark latency against.
- Convert UNET to ONNX and then to TensorRT (TRT).
- Deploy the TRT model to SageMaker on top of NVIDIA’s Triton inference server.
- Check the performance improvements of TorchScript compared to TRT.
14 Likes