In this writeup, I documented the steps I went through to get my first HuggingFace space loaded with my first FastAI model. These steps may help others get the first UI demo at Hugging Face spaces without spending many hours on the various 404, 403 and other weird errors! Audio files are converted to an image (spectrogram) before prediction. In the process got the HuggingFaces UI to work correctly across iOS, Safari and Windows.
3 Likes
Got something I can retweet?
2 Likes
Thanks Jeremy!
Will have it tomorrow.
Is it ok if I reach out again in <24h?
Actually, here it is ![]()
6 Likes
One of our users published a blog explaining the various components of HuggingFace. I really enjoyed reading it. Hope you find it useful.
7 Likes
Hi all, I’m Nival from Sri Lanka. I’m a bit behind in the course, but trying to catch up, and this break to the official course is a blessing! I tried going thru Jeremy’s beginner guide to NLP, and applying the same approach to a Abortion stance tweet classification problem. The dataset was available already in Huggingface. I thought starting with a simple problem will get me somewhere. I don’t yet understand transformers fully(not even close), but I was able to classify those tweets into ‘for’, ‘against’, and ‘neutral’ on abortion, with an accuracy/F1 score of 77% by fine-tuing “DistilBert” language model, which is similar to Bert, but smaller.
I also used a lot of help from Chapter two of the NLP with transformers book
I guess for a noob like me, it’s a decent result. So all the credit to Jeremy and the authors of the book.
I think I could definitely improve the result. It was amazing to see that a similar dataset was used as part of a competition called SemEval-2016, in 2016, and the winning model, called ‘DeepStance’ was only 63.23% accurate in the same task.
Confusion matrix:

My learnings:
- Getting started and successfully solving a simple NLP task
- Little bit about how transformers work
- Experimenting with different learning rates
- Logging my results on W&B and sharing my model via huggingface hub
Future plans
- To experiment with different language models
- Creating an inference API to my model on hugginface, which will give it a GUI interface
Kaggle Notebook: Abortion Tweet Classification with 🤗 & FastAI | Kaggle
Github repo: nival-aiblog/2022-05-31-Abortion.ipynb at master · truthdead/nival-aiblog · GitHub
8 Likes
Attending the lesson where we went through NLP for absolute-beginners made me decide to take on NLP as homework, and revive some work on lithology analysis (lithology: “the science of describing the physical characteristics of the stuff under your feet”).
I have a first blog post on this, powered by fastpages of course. No machine learning so far by the way, “only” discovering the data…
Jeremy shared his opinion at some point that there is a lot of value that could be created from NLP, and this comment stayed with me over the past weeks. There is still a lot of information out there captured perhaps like this, and a lot of knowledge and insights (as well as ethical questions by the way) to gain from this data.

edit: external images rendering in preview but not rendering in the final post
7 Likes
I need some help - I’m working on a NLP model, and the dataset has 172 distinct values for a column (not target variable). So its a ‘Drug Name’ column - what is the best way or best practice for handling it, please?
Thanks in advance. Much appreciated.
You’ll need to use an embedding. You can learn about that in the book, or in the next two lessons we’ll cover it.
1 Like
I need some help.
- In a first project, I could segment a really small structure of the inner ear, based on one MR sequence and got decent results with a DCS of 0.76 on the validation set.
- Now I would like to segment adenomas of the parathyroid glands, where I have to first label the pathology in more than one MR Sequences, one sequence will be a dynamic one(the most important one). The sequences will have different orientations, resolution etc.
Now I feel a little bit lost where to start, how to handle the different sequences etc. A little guidance is more than welcome;-).
It’s been a long time coming but with the help of the daily fastai walk thrus I have submitted my first entries into a kaggle competition from my Paperspace notebook.
You can find out how to do this yourself by following Radek’s post Practice walk-thru 6 / chp1 on Kaggle! and the official walk thrus Official course walk-thrus ✅ - #108. Walk thru 8 was Jeremy giving the demo from his own GPU but the same process works for Paperspace notebooks as well. I highly recommend the walk thrus for beginners.
Third Entry after walk-thru 9:

13 Likes
Submitted my first kaggle entry following Jeremy’s code on today’s Official Walkthru (Week 8) from Radek’s recommendation from this thread.

8 Likes
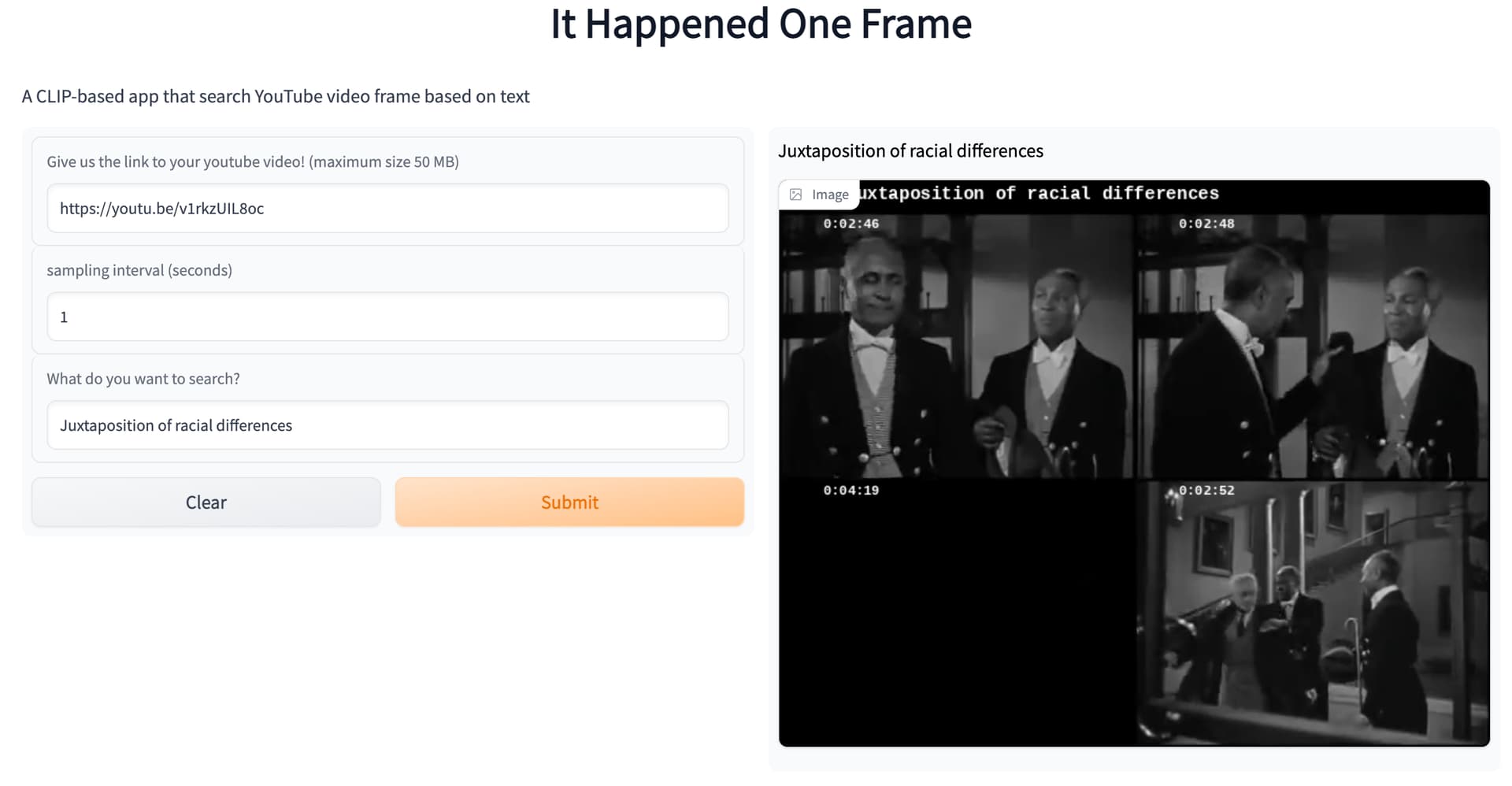
Inspired by @pcuenq 's project that uses CLIP to search photos. I created an app to search for frames from YouTube videos based on the text you type in. To use the app, all you need is the link to a Youtube video. You can use very intuitive queries - for example, you can use “Macaulay Culkin screams with hands on his cheeks” to get the iconic scream face from a Home Alone movie clip.
One super interesting property when we apply CLIP on movie clips is that we can leverage the subtitles. Subtitles are essentially images of text. Because the CLIP model is multimodal, it is able to read subtitles and develop a much more comprehensive understanding of images based on semantic information from both the frame itself and the subtitles. It means we can include the content of the dialog in our search. For example, you can search “Vizzini says inconceivable” in The Princess Bride to get all the frames when Vizzini says inconceivable.
I had a lot of fun building this app, as well as playing with it. Thanks @ilovescience for the awesome tutorial about Gradio and Hugging face. That’s all you need to launch an app on Hugging face space
I wrote a blogpost here: It Happened One Frame: incredibly accurate video content search using the OpenAI CLIP model
The app is hosted here: It Happened One Frame
17 Likes
Got a tweet I can share?
Great and intriguing work. Addictive indeed. I was reminded of a scene of The Hurt Locker today. “James’ face standing in front with cereals boxes in the background”. Not quite the frame I pedantically wanted, but certainly picked the “cereal aisle” frames in the overall supermarket scene. Impressive. I’ll read the post.
{kind=link}
That’s amazing! I loved reading the blog post too.
2 Likes
![]() managed to work with a couple of researchers to create a cell explorer. It is able to identify the causative agents of diseases Trypanosomiasis, Leishmaniasis and Malaria with extensions for inference. In addition, help with counting using a couple of widgets. Hopefully this will be start to using Machine learning models to aid us in the diagnostic laboratory and making other related tools. In case you want to check it out and the source code, reach out via email and I’ll send you using the link here.
managed to work with a couple of researchers to create a cell explorer. It is able to identify the causative agents of diseases Trypanosomiasis, Leishmaniasis and Malaria with extensions for inference. In addition, help with counting using a couple of widgets. Hopefully this will be start to using Machine learning models to aid us in the diagnostic laboratory and making other related tools. In case you want to check it out and the source code, reach out via email and I’ll send you using the link here.
The fastbook was also immensely helpful in helping me understand how to use some functionality in fastai library. Thanks for checking out and helping to the review the manuscript @poppingtonic.
3 Likes