Show us what you’ve made using the things you’re learning in the course!
I love seeing stuff made by folks new to deep learning, so please share your work even if you’re a beginner. Sharing your work helps inspire others on their deep learning journey!
Here are two great ways to share your work, both free and based on Jupyter Notebooks:
fastpages, which lets you create a blog using markdown and jupyter
Kaggle Code, just like you saw me use in the lessons – create your own notebook, then click “Share” and set it to “Public”. You’ll get a URL you can share here.
Last night I attended the first session of the fast.ai course being hosted live at the University of Queensland. This morning I trained a model that does a surprisingly decent job of differentiating between damaged and undamaged cars within a couple of hours. It took a few iterations to find search strings specific enough to return images that could be used to fine tune a model with a reasonable error rate.
My first attempt using “photos of normal traffic” and “photos of traffic accidents” was too generic.
It feels a little uncomfortable to run so much code that I don’t fully understand yet but I am taking Jeremy’s advice and building first.
Here’s my car damage classifier notebook!
The performance is highly dependent on the set of images that are downloaded with each search string. When I re-ran the notebook from the shared public link above the ‘photo of a damaged car’ returned a Mercedes driving through a flooded road. Not exactly a damaged car, unless you include water damage.
One question I have is house-keeping of the image files on kaggle. I was creating folders and paths to the image files. How do you delete the folders you don’t want anymore?
For those new to the course and perhaps unawares, I built a library called ohmeow-blurr based primarily on things I’ve learned from the course and book. It’s a fastai developer first library for developers who want to use fastai to train Hugging Face transformers.
It also illustrates something Jeremy mentioned in the first class …
It’s weird because its academically atypical, and yet, as I think about how I’ve learned to build or do anything … this is how it starts. In fact I would argue that your insights about getting quality data for your task are a result of “just running the code.”
By week 3 or 4, you’ll know quite a bit about what is going on underneath it all
It feels like forever since I was last looking into the fast.ai library. So, I’m resorting to start over my understanding from scratch, building a multi class classification model.
I also saw some Huggingface spaces demos a while ago, and thought that was pretty neat. Earlier this week when looking into it, I found out that it was definitely possible to use fast.ai models on huggingface spaces via gradio, so I figured why not try that.
So, what I’ve done is built a Food image classifier (Food-101 dataset) and hosted it as a live interactive demo on HF spaces. I find it more fun to be able to play around with the model with real images.
Let me know what you think. If there’s enough interest, I can share the notebook as well. It’s very similar to the classifying breeds tutorial on fastai docs.
Overall, this was fun to build.
EDIT : I’ve now also added the notebooks used for training (and testing out gradio inference) in the same HF repo (notebooks folder) if anybody wants to take a look at it.
This is my beginner post about converting images into tensors and back. This is my way to document my study in a searchable environment (Fastpages) mainly for me but maybe for others too. I’m exploring the fastAi ToTensor class, then torchvisions’s ToTensor class, and lastly just passing image(s) into a tensor method (I guess). The last part is about reverting a tensor back to an image. Convert image files into a tensor and back with FastAi, PIL, Torchvision and Vanilla Pytorch
Thanks for asking I haven’t written about it yet, maybe something I can work on the coming days once I understand the libs better. In the meantime, I think @ilovescience has already written a pretty good post on the topic that I followed through.
It’s available at : Gradio + HuggingFace Spaces: A Tutorial | Tanishq Abraham’s blog
The thing about HF spaces (that i’ve learnt so far) is that all the code+models+etc. is contained in the git repo for the project, it builds/runs the gradio app via some internally defined Dockerfile, proxies it to another url & then embeds that url into the main page via iframes.
I’m still curious about the operational aspect of spaces(for eg. when is the container(process) spawn/shutdown/restarted, processes per space, build-deploy flow seems really quick etc.), but I’m getting a bit carried away and that’s for some another discussion thread.
Hey everyone, I thought I would share my project from when I took the 2020 course. It’s probably much larger than it should have been, but anyway here is a project on classifying 1000 species of mushrooms from over 200k images I think this might be the largest mushroom classifier around…?
It might give some insight into preparing data for a model, training models, and using callbacks (commands that trigger during training to do something helpful, e.g. save the model weights).
I’m please to present my Kaggle Code (Which is a copy of Jeremy )
Elon has been in the news a lot lately
I created a model to see if a photo is Elon Musk or not
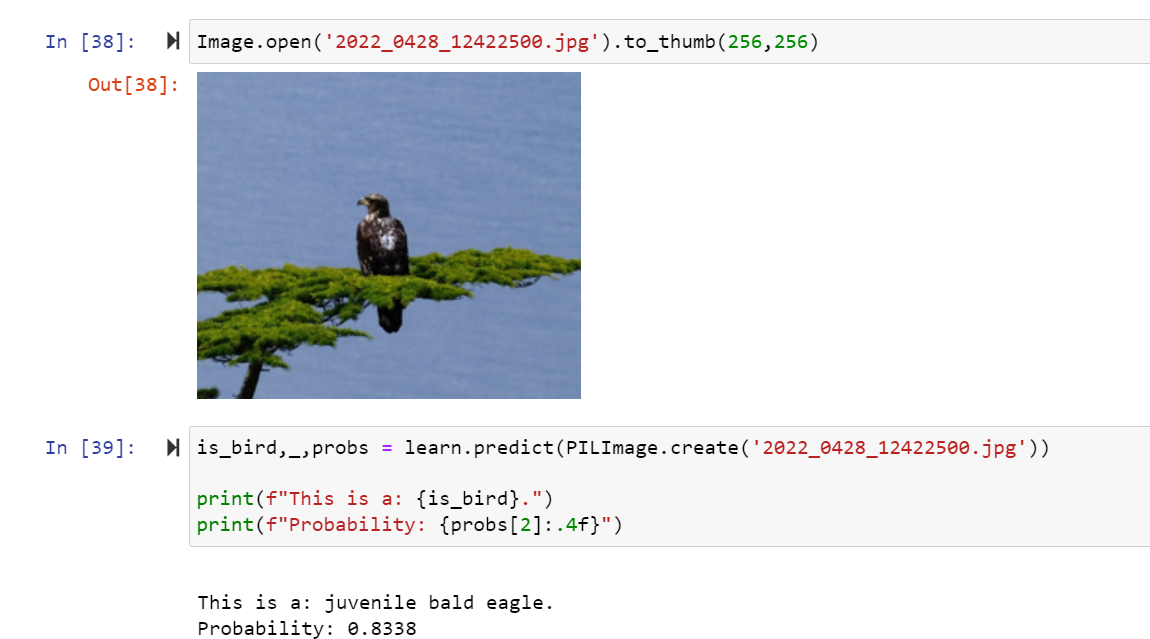
To make the Bird v Forest a little trickier I used much the same code as Jeremy had but used 4 classes of birds that can be hard to tell apart. Bald Eagles, Juvenile Bald Eagles, Golden Eagles and Osprey. One lesson learned - an Osprey is also a “tiltrotor military aircraft” - so searching for ‘Osprey Bird’ gets a better result. Anyway, with 300 pictures of each, and just 15 seconds of training (5 epochs of 0.03) on my WSL2 Ubuntu running on my Win11 Surface Book 3, it identified this picture from my lunchtime walk today. I thought 83% was pretty good (and correct!)
. I’ve been through earlier fastai courses and so excited to see so much of the hard work is hidden away, allowing more focus on the problem - and of course the data. My image set could do with some cleaning…

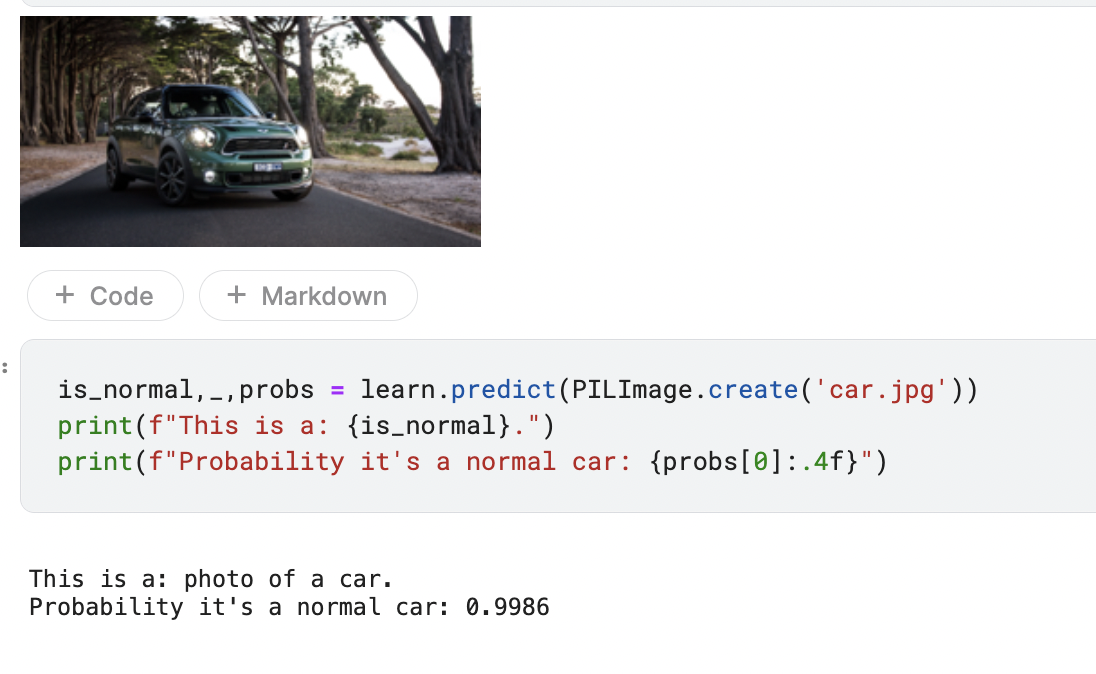








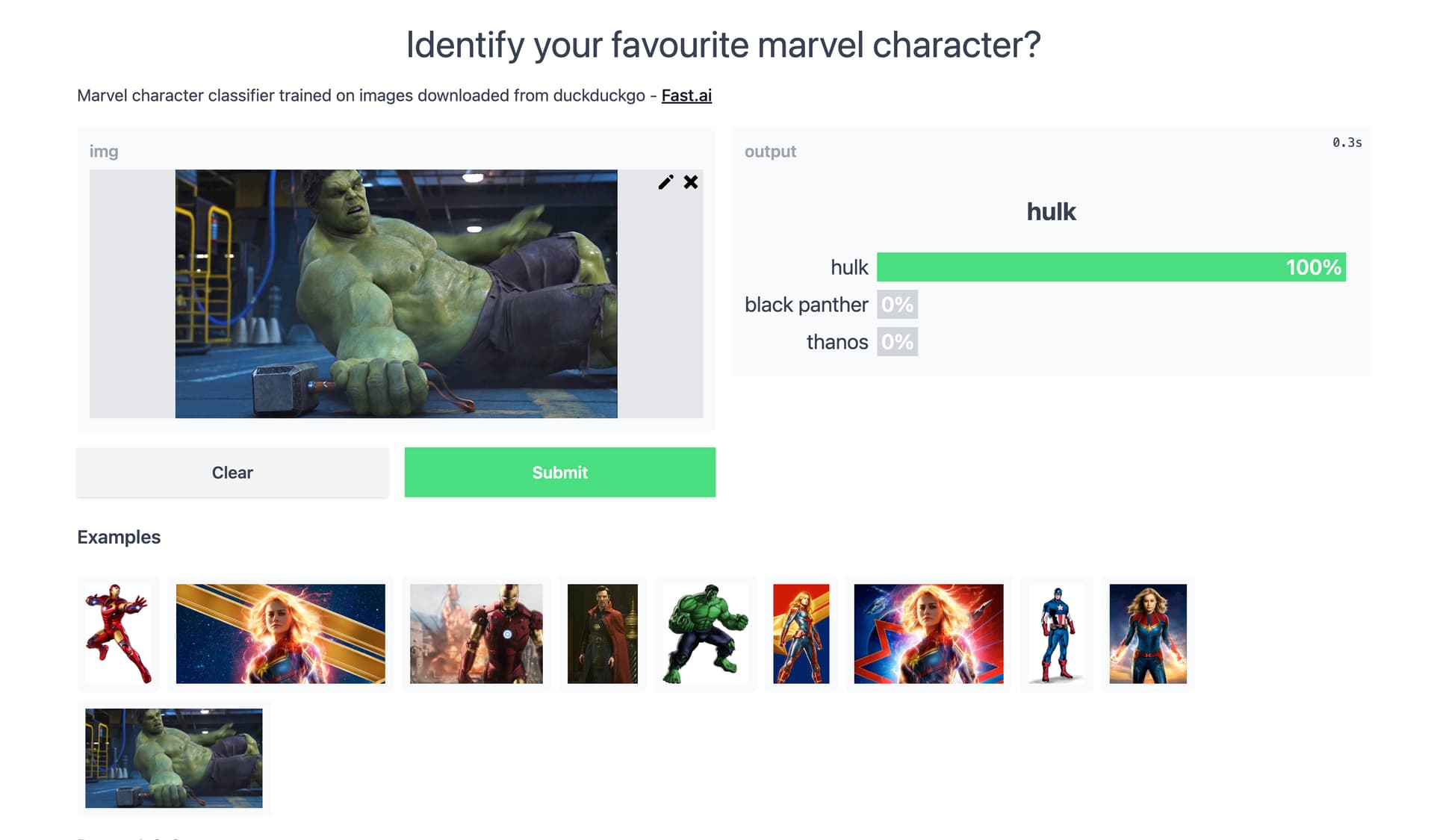
 , I wanted to build a classifier that identifies
, I wanted to build a classifier that identifies  , I deployed the Gradio app on the Jarvislabs.ai CPU instance. You can play with the demo
, I deployed the Gradio app on the Jarvislabs.ai CPU instance. You can play with the demo