This week I wanted to really make sure I grasped what was going on with everything in chapter 4 of the book, so I put my study hat on. Writing helps me understand, so I split the things I learned from the chapter into several separate blog posts. I used the Fashion MNIST dataset to switch things up and chose to compare pullovers and dresses as I figured they were at least partly similar somehow in appearance:
- “A dress is not a pullover: learning about PyTorch Tensors and pixel similarity using the Fashion MNIST dataset” (link) — where I replicate the pixel similarity approach taken at the start of the chapter
- “Some foundations for machine learning with PyTorch” (link) — in which I summarise the seven steps needed for model training with this update-the-gradients approach.
- “Stochastic Gradient Descent: a mini-example of the whole game” (link) — I replicate the mini-example of optimising a very simple function.
- “Using the seven-step SGD process for Fashion MNIST” (link) — I cover the ways that we need to add some extra functionality to make things work for the many parameters of our Fashion MNIST image data.
- “A neural network for Fashion MNIST data” (link) — I show how we can extend the previous linear function so that we emerge with a neural network by the end.
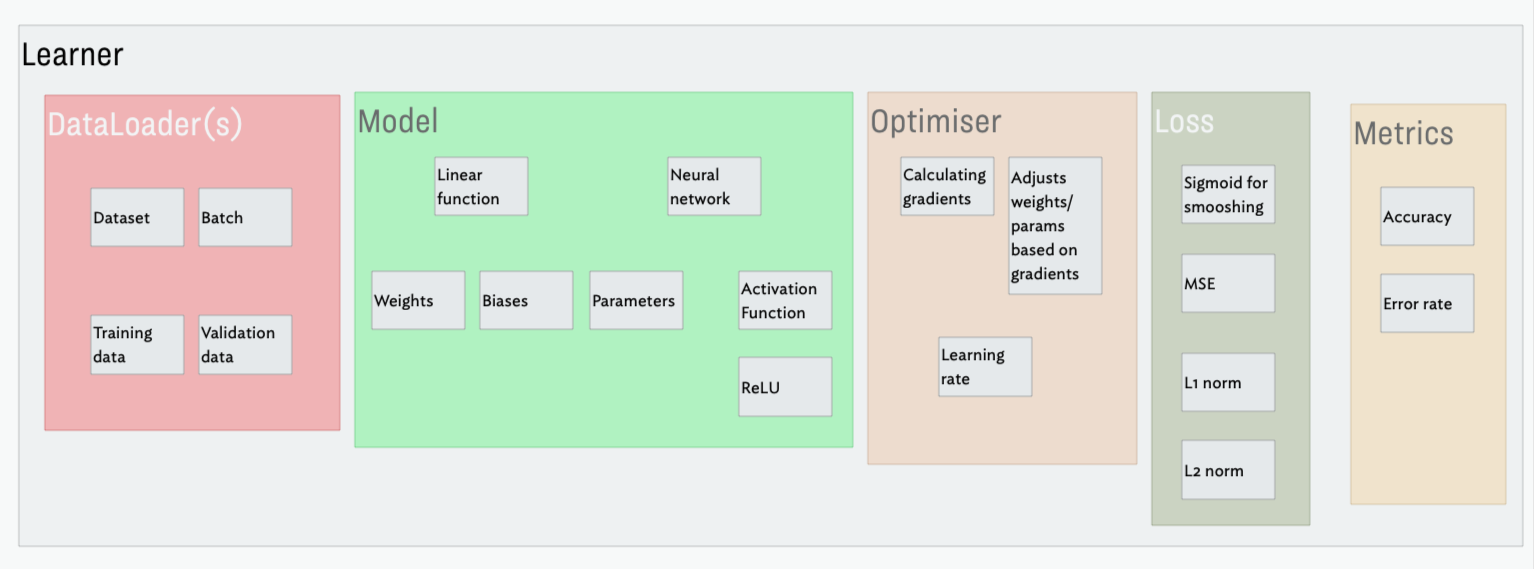
Obviously this closely follows the material taught in the book, so no prizes for originality. At the very end, I made a diagram to try to summarise some of the things I’d learned from this chapter and how they all fit together as part of the abstractions.
I’m really looking forward to the upcoming class. We had a little taster of the power of embeddings in our meetup group today thanks to an amazing show-and-tell from @pcuenq!