I have built cloud segmentation pipelines using fastai if you are interested.
4 Likes
Ciao amigos!
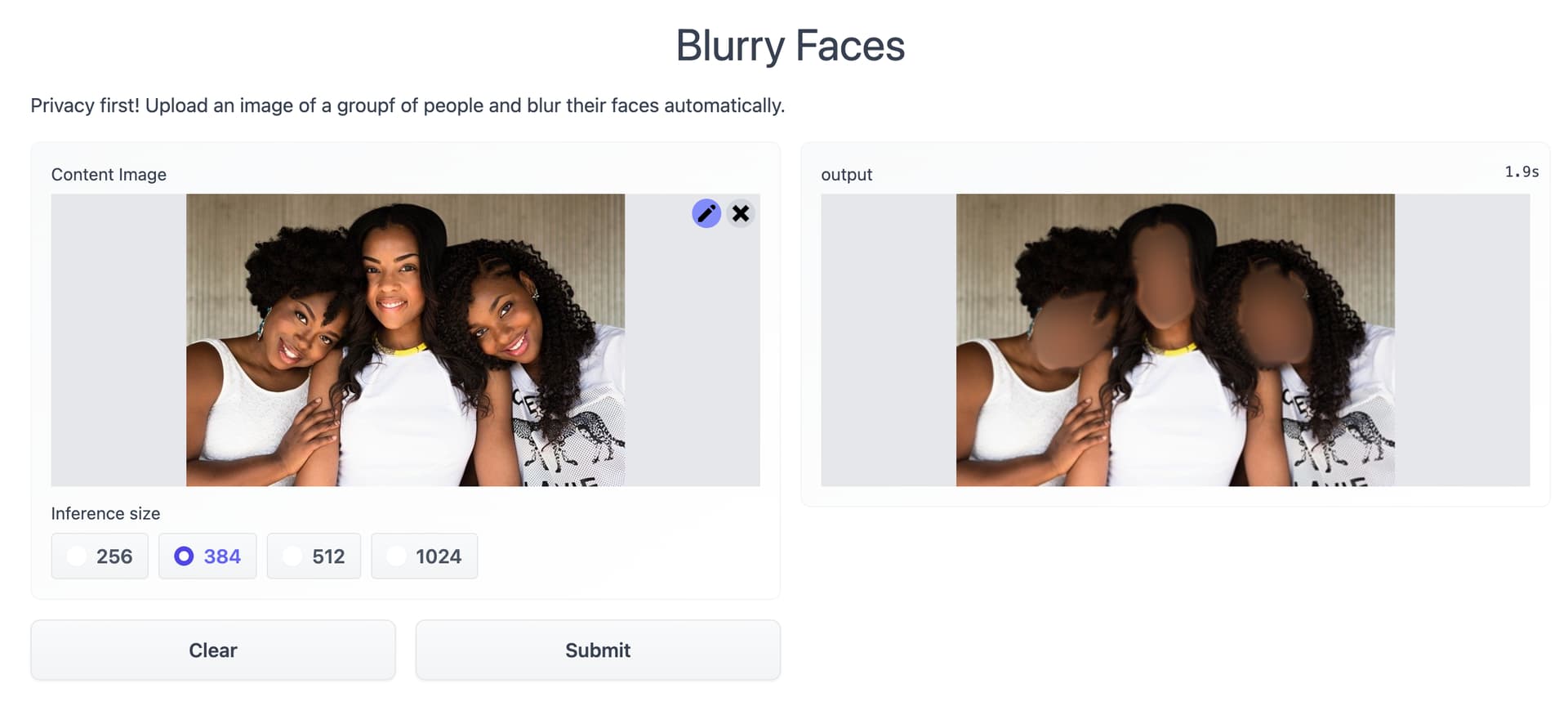
I have been working on my face-blurring app lately.
I published the latest version to HuggingFace over the weekend.
Torchscripted UNET trained with IceVision ![]()
Post coming about how to deploy it on Amazon SageMaker using NVIDIA Triton as an inference server and TensoRT.
15 Likes
Fantastic - thanks for sharing @tcapelle, I’ll definitely check it out.
The fastai community is so open and supportive, I am loving checking the forums each day to see what people have shared and posted. Thanks again!
1 Like
Thanks a lot, Wayde! That’s one of the nice things about using Weights and Biases for visual content, you can save your results and then create nice reports with them. You can also save your training runs and compare plots, but there was no training or fine-tuning in this prototype ![]()
5 Likes
Can you open source the code also @pcuenq ?
This was my favourite demo and I was mind-blown when Pedro first showcased it during delft-fastai study group ![]()
Hello again Fastai friends,
I really enjoyed Jeremy’s excel workbook explanation of neural networks, but I felt I needed to spend some time rewriting it with some data I’m familiar with if I was to truly understand what was going on in there, therefore I re-wrote the excel workbook using weather observation data from the Sydney Airport automatic weather station.
I set up a model to predict the temperature value 30mins ahead of the current observation. As a baseline I used what is called ‘persistence’ – basically, the temperature 30mins ahead of now will be the same as now – and used that to compare the performance of my new more complex models. I have pushed my excel workbook here for those interested but the results were as follows:
- Total Loss (mse) Baseline (Persistence): -0.00196
- Total Loss (mse) Linear Model: 0.259
- Total Loss (mse) Neural Net Model: 0.259
Turns out that persistence baseline is best at this time scale, which is not surprising really.
But getting an accurate model wasn’t the goal it was just an exercise to allow me to implement this from scratch with some new data.
Thanks to everyone who’s sharing their work here on the forums - it’s really inspiring and motivating to see what you’re all doing!
7 Likes
HI ![]() all,
all,
Published my next video on Fastai vision_learner, where I shared my learnings on
- Setup and use an IDE to explore
fastaicode base. -
vision_learnerwalkthrough - how
fine_tuneworks - how
create_timm_modelworks
Thanks to @mike.moloch @strickvl @suvash @pcuenq and Jeremy Howard for sharing feedback and tips on improving the audio quality. Hope you find the audio better this time ![]() .
.
Hope you like the video, please share your suggestions/feedback ![]()
15 Likes
Thanks for another great video @VishnuSubramanian ! The sound is great! and I also learned that I can run VSCode right in a jarvislab instance. I’m going to try this soon! I’m probably not the intended audience for these videos as these are probably for advanced users of the Fast.ai framework, but they’re really helping me understand the general layout of the framework (for when I start digging into it.)
Amazing work!
1 Like
Fantastic! And I appreciated how you explained how to navigate vscode.
Have you considered including the vscode server stuff in the base image, so people don’t have to install it manually? Paperspace have a nifty feature where they provide a button you can click to quickly open vscode attached to the running kernel, which is cool.
4 Likes
Thank you so much. Keeping mike close to the mouth did the trick and saved me money, I was able to use the mike that I already had ![]() .
.
Yes, I was actually thinking the same, to add VsCode to the base image and also have it as an additional option to the existing JupyterLab by default. TBH I figured about code_server when one of our users was asking for it a few days back. I will be adding it in the next few days ![]() .
.
8 Likes
Heya FastAI fam!
I am, admittedly, behind in working through the course. I’ve just finished working through Lesson 1 and thought I’d share my (late) homework. I saw a post on LinkedIn several months ago suggesting that computer vision models can’t distinguish between fried chicken and tan, fluffy poodles. It turns out that this has been a bit of a meme, predating that LinkedIn post.

It rang a bit false in my mind at the time, and I’ve tucked it away for just this sort of project! I built 2 separate models using resnet18 architecture on 2 different sets of training data. I then snipped each of these 9 images and ran them through both models. Both models correctly classified all 9 images as either fried chicken or a dog, which was close to what I had expected. What was interesting to me is that the training sets for each model didn’t really look a lot like these visually similar images in the meme, yet the models performed superbly! For example:

Perhaps this meme was based in truth at some time in the past 5 years, but deep learning has advanced significantly since then? Regardless, this was a neat thing to play with so quickly using the great FastAI library! Here’s the notebook.
Cheers!
14 Likes
Someone specifically asked me to do this when I shared my ‘beard detector’ with them. I just never got around to it. Please do share your HF space when/if you make one for your project.
This was a great walkthrough of some of the parts that I’ve never really peeked into. ![]() Thanks for making these videos. The audio sounds great.
Thanks for making these videos. The audio sounds great. ![]()
3 Likes
The audio is clear, the video is great!
Maybe you could split it in sections for easier fruition & navigation ![]()
2 Likes
Something I’d like to see if I can achieve is converting a photo of a terminal strip (left)
into a digital representation (right). An MVP would produce a text table rather than the design drawing shown. Each table row would include:
- the text identifying each terminal number, e.g. 24V, 0V, M1, M2
- which terminals are wired
- the ferrule text identifying each wire e.g. 24V-281, C2-241
- which wires are missing ferrules, or ferrule can’t be read
Also the text of the terminal group lable would be captured, e.g. MODULE 6F-06 C2
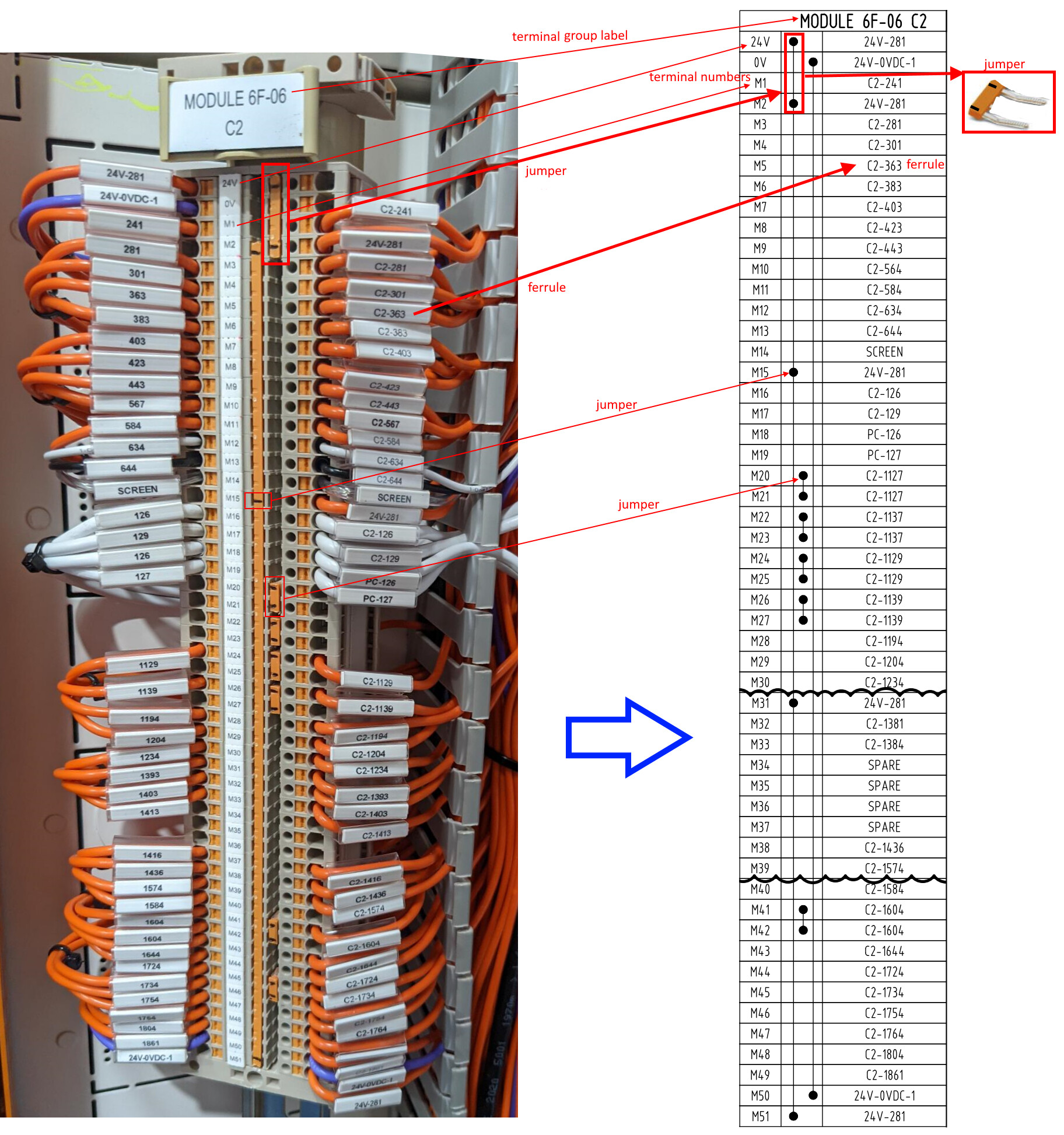
The application is that after all terminal strips in a Motor Control Centre are wired according to the design drawing, “as-build” checking needs to be done to validate the wiring, and any changes made during wiring need to be updated into the “as-built drawing”. An MCC could have a dozen such terminal strips.
I might approach it as follows:
- Starting with a more distant picture, showing several such terminal strips, segement into sections: left-ferrules, right-ferrules, terminal-numbers, group label.
- From (1.), segment those sections into individual cells and pass those pixels to a MNIST/CHAR recogniser.
- Since most of the ferrules on the left can be inferred from the ferrules on the right, maybe do data augmentation by blanking out a ferrule such that the NN needs to determine the missing ferrule by referencing the opposite side.
- Similar to previous, but during training give NN design drawing plus photo with ferrules blanked out, and it needs to determine missing from the design drawing.
- Down at terminal M48 the text of the right-side-ferrule is not clear from this angle. The system would smart-stitch a numbre of photos taken from different angles, and/or process video so that it can observe ferrules from different angles.
What sort of approach, architectures, pretrained models would it be useful to consider?
4 Likes
The other thing I’d love to do, inspired by Ellee - An AI (GPT3) Powered Talking Robotic Teddy Bear, is to produce an office mascot that:
- MVP: sits in reception and greets employees by name as they arrive in the morning.
- Later: since our reception is often unattended, non-employees get greeted and asked who they are here to visit. That person is then notified over Microsoft Teams, who can communicate a message back to the visitor that they are on their way.
Are there pretrained models for human faces that might be good to start with, and be able to distinguish people from a really low number of sample images? Ideally I would not have to invasively take lots of photos of each staff member - although a teddy bear that is handed around could gather its own dataset, and each morning in reception would be a chance to gather more samples.
2 Likes
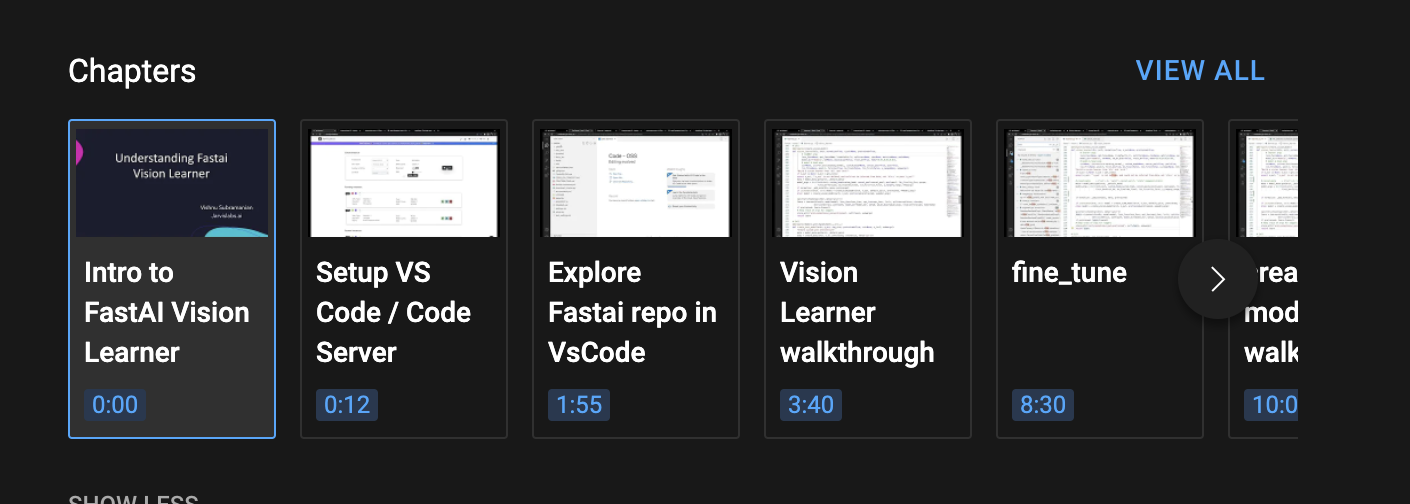
Thanks for the suggestion, I Added chapters to the recent videos. I hope it will be easier to navigate.
4 Likes
This week I fine-tuned a language model as per the shift in the domain we’re working on in the course. I struggled quite a bit trying to think of interesting yet self-contained / small uses of NLP that I could try out. A lot of the common uses for simple NLP modelling seem to be in the area of things like ‘sentiment analysis’ where I couldn’t really see something I could build. Also there are a lot of NLP uses cases which feel unethical or creepy (perhaps more so than in the computer vision, it felt to me).
I emerged at the end of this thought process with the idea to try to pit image classification and text classification against one another: could I train an NLP model that would outperform my image classifier (trained in previous weeks) in detecting whether a specific document or page contains a redaction or not?
My blog contains all the details on how I did it and the problems I ran into along the way.
I was most struck by:
- how much memory training these language models can potentially require
- the limitations of short sequence lengths when using transformer models
I’m looking forward to the longer break after next week since it might give me the opportunity to dig into something a bit more involved / challenging on the NLP front.
9 Likes
This is wonderful!! Now I am really curious how an RNN model would perform on this task. Did you try any approach other than transformers on this?
I didn’t so far. I could perhaps replicate how chapter 10 of the fastbook handles things. I’ll see if I can find time to do so before Tuesday.
2 Likes