Hi @JoshVarty thanks for your reply and that was a good insight, never would have thought to have done that. After going through some of the Kaggle discussions it seems like there are some specific pre-processing being done to the images which some of the top submissions went through. I’ll try and re-compose my validation set in this way and see the difference that makes. That link in your post (and also your post : ) to the Kaggle solution was useful.
Brilliant, you should be nominated for an IgNobel award.
1 Like
For Lesson 3 I made a segmentation model using the MultiMNIST dataset !
Available here : http://thomasdargent.com/projects/fastai2/
An easy project overall. The preprocessing steps were indeed the “hardest”.
Simply super , congrats. What annotation tool were you using ? Can you share a bit about pre-processing / post-processing done . thanks.
ha, right on! 
Sure. Whenever faced with a single channel input and able to use pre-trained models, see if you can feed in extra pre-processed data alongside it. Thats generally my approach to all challenges - spend time getting the input data sorted out over making a cleverer network.
I fed in the simple Euclidean distance transform- where pixel intensities are mapped as the Euclidian distance from the pixel being evaluated to the closest border pixel.
I also fed in the “isotropic diffusion of the gradient vector field of the euclidean distance transform” described here. What a mouthful! The effect is to cause calculated pixel intensities to fall off more rapidly away from medial axes.
I enjoyed learning about the Chamfer Distance which was being used as a metric. This basically measures contour differences point by point. I reckon this might have some legs in image segmentation especially if somehow I can create a loss function in future. Seems more intuitive than Jaccard/IOU to me.
3 Likes
Thanks guys for providing all these amazing resources!
In Lesson 1 I struggled a bit with pre-processing the dataset and getting to grips with the API’s though finally got the monkey classifier working. I changed all the label directories to the monkey names and compressed and uploaded the file to google drive.

Using the code in Lesson 1 nb the accuracy was 96.8% and after unfreezing the layers and re-training the accuracy increased to 97.5%. The best entry on Kaggle achieved 98%+ using resnet34.
2 Likes
Hello everyone,
First of all, I want to thank fast.ai and the users for the amazing course and forum posts! Second, I would like to share a web application I made based on the second lecture. This is actually my first self-made project, and this course is the first in which I learn about machine learning. So I would like to receive some feedback.
The application I made is a melanoma classifier, which you can visit here: https://melanoma-classifier.herokuapp.com/. As you see from the url, I used Heroku to deploy the app. And you can find the source code here (including the Jupiter notebook with which I trained the model): GitHub - Mees-Molenaar/melanoma-classifier: A web application to classify possible melanomas using the Flask and fastai library..
In the notebook I have made lists of problems that occurred and possible improvements that can be made, which I will copy here:
Improvements
This is my second project (I am still finishing the first project). I already felt more comfortable using the fast.ai library. However, there is still room for improvement.
- Making sure the training data is trustworthy since I am no dermatologist
- Maybe using resnet50 instead of resnet34
- Using other transforms (maybe just like the satellite in lesson 3, for this problem I can use vertical flips?)
- And in lesson 3 there was a part about picture sizes, maybe that also can help this model. However, I didn’t fully understand it yet.
- Improving the learning rate
- Change the number of epochs.
Difficulties
During this project, I had several difficulties challenges that I would like to share with you.
-
Finding a trustworthy dataset (I was not able to find the source of these pictures)
-
I am no dermatologist so it is hard for me to verify the data.
-
Making the web-application. My only experience is using Flask in the cs50 course I followed online via Edx. However, the most problematic part was deploying the model on a hosting site. After a lot of tries, I was finally able to launch the app on Heroku.
-
I am not able to run the code locally yet, so I had to upload it to Heroku to check if it worked. This takes quite some time, so honestly, I should try to install the necessary programs locally. Since I don’t have NVIDIA graphics card, so don’t have CUDA, I for some reason was not able to install the fastai library (even using the pytorch CPU only library)
-
First time using Heroku: needed to change the Procfile, but I didn’t know how. I found out that for the web application you need this line of code:
web: gunicorn application:app
- And you should rename application to your filename that creates the Flask instance, and app to the name you gives this Flask instance in your application file.
- Lastly, I got a problem: Unexpected key(s) in state_dict. This seems to be a problem with different fastai library versions you use for learning the model and making predictions in your web app. So you have to make sure you use the same fastai library versions.
Thanks a lot for your time reading about this project, and I would be glad to answer any questions.
Cheers,
Mees
3 Likes
Congrats on your project! Just had a play with the app and it correctly predicted two examples (benign and not benign images).
I’ve been experimenting with creating image classifiers without requiring any code or data for that matter… I know it might be somewhat controversial, but I wanted to see how far I’d get…
I wrote down some context: https://www.zerotosingularity.com/blog/seeme-intro/ which also includes a video demo…
3 Likes
Hi, I create and put into Github two simple examples of monitors for fast.ai, one for Neptune.ml, and one for TensorBoard when you can use both in the Google Colab notebook. I hope that it’ll help use these two great tools.
The example of the Colab Notebook: https://colab.research.google.com/drive/1HEVbnOyKSLSIkMhpYLWO83Wut3hJrP42
List of saved parameters that are saved in the TensorBoard:
-
Scalarswith all metrics and training loss for each batch -
Imagesfor top losses images -
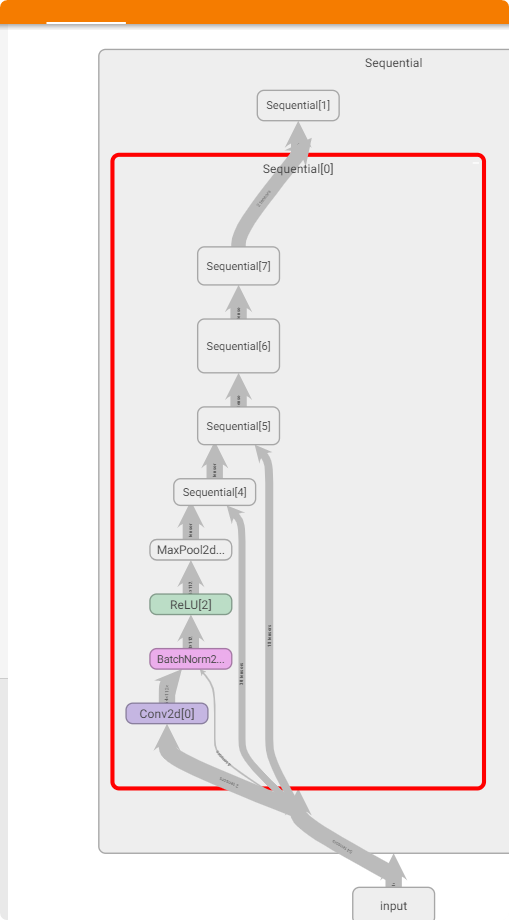
Graphfor the model -
DistributionandHistogramsfor each parameters in layers -
Hyperparameter Textforlearning rate (lr),momentum (mom),weight decay (wd), andbeta (beta) -
TextforModel,Summary,Model save path, andTotal Epochs
List of parameters that are saved in the Neptune.ml:
- all
metrics -
last_lossbatch -
model.txt- info about the model -
opt.txt- OptiWrapper -
Propertiesforlearning rate (lr),momentum (mom),weight decay (wd), andbeta (beta) - Use of
CPU/GPU,RAM
Couple screenshots:

These files are straightforward, and you can modify for your purpose as you wish.
7 Likes
Hi all, I just completed the first week. I had a go at classifying painting styles using the dataset from the Painter by Numbers Kaggle competition (https://www.kaggle.com/c/painter-by-numbers/data).
I took the 20 most common styles from the training set (62k images) and ran them through the lesson notebook.

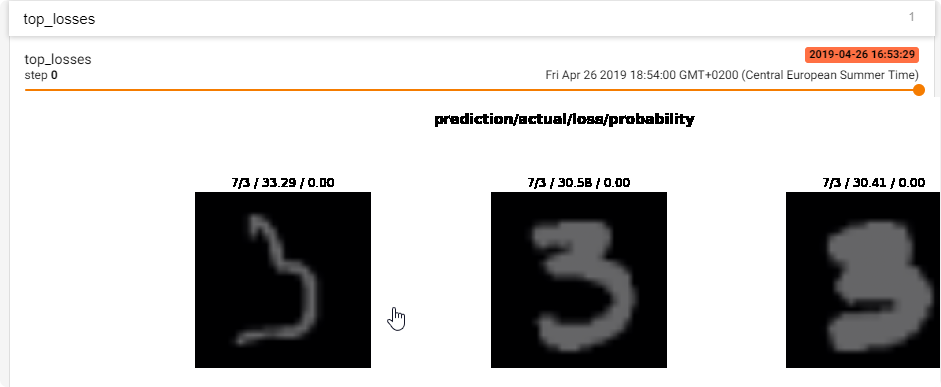
The loss seemed to stop improving after about 10 epochs (unfrozen), with accuracy just over the 60% mark, although it varied quite a lot by the style. The below is the confusion matrix, I used normalize = True since there were unequal numbers for each style.
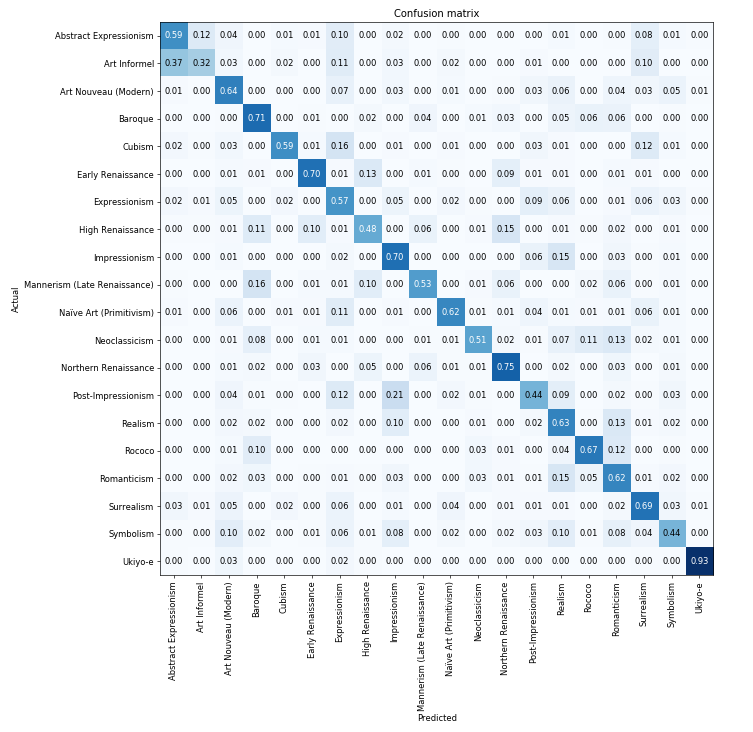
Worst performing was ‘Art Informel’, which got very confused with ‘Abstract Expressionism’ - this made sense since Wikipedia says that they were developed in parallel, the main difference being one was from Europe and the other from America. The best performing was ‘Ukiyo-e’ (92% accuracy) which is paintings from the Japanese Edo period (1603 and 1868) - the isolationism of the age reflected by a particularly distinctive style perhaps.
Really enjoying the course, onwards to week 2…
4 Likes
Hi Guys
I just finished Lesson 1. Using the techniques taught in the lesson 1, I wrote 4 medium articles:
-
Devanagari Handwritten Digits Classifier - In this challenge, I got an accuracy of 98.99%
-
Malaria Blood Cell Images - In this challenge, I got an accuracy of 97.3%
-
Pneumonia Chest X-ray images - In this challenge, I got an accuracy of 95.8%
-
Histopathological Cancer Images - In this challenge, I got an accuracy of 98.12%
Comments and feedback shall be most welcome and appreciated.
I am simply amazed by mainly two things:
a. In few lines of codes and short span of training time, the level of accuracy is mind-boggling. Never knew that Deep Learning could be so much easier to implement on real-world challenges. A big thanks to Jeremy and Rachel for this wonderful course.
b. I used in all above different challenges same CNN architecture ResNet50 and just blown away by the fact that a model trained on a completely different dataset (ImageNet) is so accurate in classifying different types of unseen images.
Really looking forward to Lesson 2 now.
5 Likes
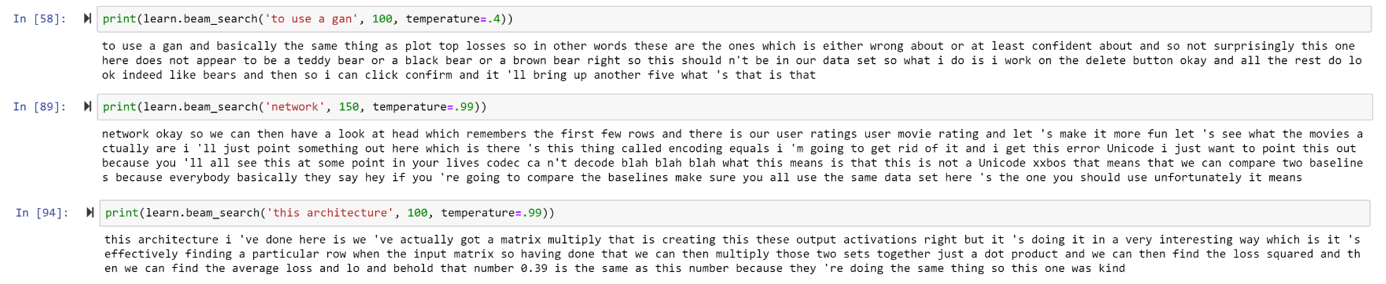
In an attempt to show my appreciation for Jeremy and also be able to hear him talk about whatever I wanted whenever I wanted, I made a Jeremy Howard language model I’ve been calling MiniJereme. I trained a couple different models because it kind of became too good so I tried making it worse to get some funnier responses. Here are some of its predictions:

I also thought this would be a good time to share a little about me since I don’t have to worry about Jeremy kicking me out of the course/ SF study group for lying about having one year of “coding” experience 
I grew up playing baseball, played in college, majored in business management, and minored in philosophy and psychology. After I graduated I knew I didn’t want to play baseball anymore, ended up studying to go to law school for a while, then last April decided to look up how to program. Somehow I stumbled on fastai and found myself taking part 1 v3 in person and going to the SF study group everyday (when I got there I didn’t know how to do comprehensions).
Since then I’ve been able to apply the lessons to things like coloring a photo of my grandmas husband (who passed away before I was born) and giving it to her for Christmas, an app for my cousin (who plays professional baseball) that analyzes his swings for him, and speech recognition for my sister who has autism. It makes me so happy that I’ve been able to give my grandma memories she might not have thought of, or maybe make my sister’s or cousin’s lives better by designing things specifically for them!
I will always be thankful to Jeremy, Rachel, and Sylvain for everything I’ve learned and how you all have changed my life. Learning programming and fastai has let me get ideas out of my head that would otherwise be stuck and it’s an amazing feeling. I hope one day I can give back to you three what you have given to me  and a
and a  for Sylvain
for Sylvain
18 Likes
firstly, i would like to say a very big thank you to Jeremy Howard and all the members of fastai for giving me the opportunity to pursue my dream. thank you.
secondly, i am currently offering the DL course by Jeremy lesson 2 to be precise, i can confidently build a state of the art vision model now but am having issues creating a model to solve the kaggle digit recognizer challenge. i believe the reason is because kaggle dataset is a tabular dataset not image. how can i go about it.
this is a great idea
2 Likes
All -
I wanted to share with you all an Art Project I have been working on: https://www.9gans.com/

9 GANS is An AI Generated Art Gallery that is refreshed every hour to create a completely new and unique collection of 9 images. Hence the (bad) name. Let me know what you think. 
17 Likes
After watching Jeremy’s examples of model interpretation in machine learning course (lesson 3 and lesson 4) I’ve wondered if something similar exists in tabular models. And looks like it didn’t, even though it seems to be very tempting to understand data through it’s model interpretation.
So I’ve implemented these functions and made an example for the Rossmann data.
There you can find functions for:
- feature importance calculations
- partial dependence calculation
- plotting dendrograms (for data inself)
- plotting embeddings
- also there is an example of using trained embeddings for another models (using only, not retraining), like to compare NN with Random Forest+embeddings
The notebook is here
4 Likes
I am also doing the similar project on Age Prediction but used instead 7GB IMDB-Wiki dataset.
By just looking at the data, it looks like a noisy dataset. Few of the celebs I know of have their ages completely way-off.
Not surprisingly, when I am using metric as “accuracy”, its not very great.
Do you have any idea if some other better alternative dataset available in public domain?
Best Regards
Abhik
Nice work! Have you seen the ELI5 library? It is somewhat similar to what you are doing, except it seems that it’s more focused on certain ML algorithms like XGBoost and LightGBM.