Hi all,
I reimplemented the DARTS algorithm (Differentiable Architecture Search). This helps to search for rnn cell. I use fastai callbacks to make the code clearer so it is also useful if anyone is interested to learn more about callbacks.
Hi all,
I reimplemented the DARTS algorithm (Differentiable Architecture Search). This helps to search for rnn cell. I use fastai callbacks to make the code clearer so it is also useful if anyone is interested to learn more about callbacks.
Hi. If you want, is very easy to put your model out in the world for other people to test.
Just follow this tutorial for a Render.com deploy. It’s the easiest, just a few clicks.
Congrats!
Thank you for your feedback and questions.
Of course, not only for segmentation, but also for regression, classification, and even, perhaps, GAN. Segmentation is only an example. It is planned to prepare an example of regression.
Roughly speaking, SparseConvNets realizes the same types of layers (Convolution, Pool, etc) as the classic CNN for 2D, but it exploits the fact that the voxels (3D pixels) occupy only a small part of the spatial space.
However, according to the tests, the Multi-View 2D CNN approach works more precisely for the classification problem.
A link with a description of the details: Submanifold Sparse Convolutional Networks, 2017 Introduces deep ‘submanifold’ SparseConvNets.
The author of SparseConvNet (repo) has detailed articles. The purpose of fastai_sparse is to make use of fastai’s capabilities and simplify the development of transformations.
Great job James
Please I checked your code on Github and want to run it. Any guide as to how to run it would be well appreciated especially setting up the environment, library dependencies etc…
Thanks
Yes, I did that Welton, thanks - It was indeed very easy and satisfying also.
Hi Ebenneutz,
I see this is your first post here, so I would suggest 4 (rather lengthy) steps.
Install Fastai- Everything was done with fastai. There are several good guides on this site depending on the platform you are using.
To make sure everything is running properly, I would test by going through the “tabular” notebook under examples.
Then look through Rossman. It has a “data cleaner” file and then the file that does training. My code does something similar.
Once you have done that you should have everything to run my code. Start with the dataloader so that you are able to save the information and then go back and run through the main notebook.
As long as you have a big enough GPU (8gb), you should be able to run everything. If your GPU is smaller, you need to go back through and remove some features.
Hi there! 
I finally got around working on the notebooks. Following lesson 3, I managed to easily get a classifier for emotion classification on text. Then I deployed it using Flask + nginx + uWSGI  on a server provided by https://www.bw-cloud.org.
on a server provided by https://www.bw-cloud.org.
You can check it out here: http://ims-seat.de
I’ll write soon a longer post about the whole process and put the whole code on github. This was lots of fun!
I’m still trying to improve the classifier… emotions are difficult. 
I have done a test run of Lesson 2 , using images of eczema patients ( I am trying to create an eczema classifier .
The below are my results of the Lr_fit_one_cycle .
Total time: 00:15
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 10.023257 | 462.080811 | 0.781250 | 00:07 |
| 1 | 9.761022 | 45.259087 | 0.867188 | 00:07 |
I feel my error is just too high .
What can i do to improve it ?
Completed my lesson 2 homework yesterday. Today I present to you the wonderful “Lois Lane AI” !
Nothing really new, just trained the second lesson notebook on my own dataset and put it on the web. And now the algorithm will allow you to decide if a picture is of Superman or just a random journalist. I had a good time making it, that makes me excited for what’s next !
Have you cleaned the dataset ? An error rate this high seem to indicate that the algorithms have trouble making sense of it.
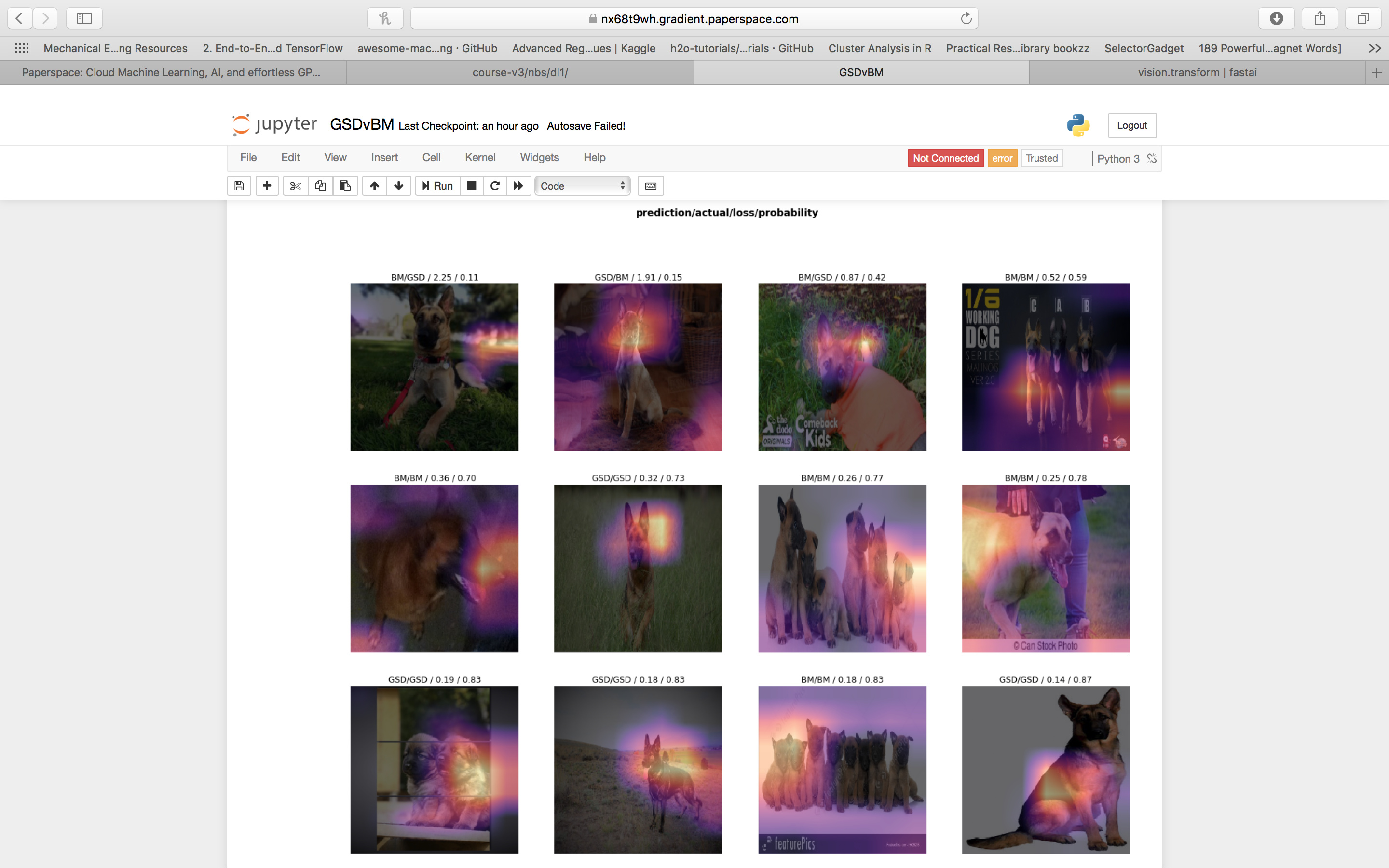
Hi all, finished watching the first lesson last week. Made a few trial projects so far. This is my German Shepherd Dog (GSD) and Belgian Malinois (BM) image recognition project. Many people find these two breeds visually similar. While I was going through the downloaded images off Google Images, I couldn’t tell the difference between the two sometimes (and I own a GSD).
This ended up achieving a 98.3% accuracy on a dataset size of 616 GSD photographs and 227 BM photographs, using a 80/20 train/valid split. I believe my results would have been similar using even less images, and I will try with a 50/50 train/valid split to find out if this hypothesis is correct.
The whole project took about 30min in total.
Here is a screenshot and some notes.
Here we can see the model generally look at faces/snouts and coat colours.
Note: Out of the 168 validation images only 3 were incorrectly classified
See for yourself the similarities between the two breeds.
This is the ResNet50 model after 4 frozen epochs and 8 unfrozen epochs, which is where I stopped as the train_loss went below the valid_loss and the valid_loss stopped decreasing. The error went down to 4.16% after the first stage and 1.79% after the second stage.
I added cutout as an extra transformation which I have found in other projects to help increase accuracy when using multiple epochs to stop from overfitting.
The images were compressed to 65kb size before uploading to Paperspace Gradient
These results are better than I was expecting, but not too surprising given the results of the Cats and Dogs model shown in lesson 1.
If you have any questions or remarks, please go ahead.
Thank you for this post.
This helps to install fastai.
Do you have the code for your web app open sourced? Looks really nice.
One other catch with this contest is the way in which you create your validation set. The dataset is made up of slides that are taken from larger composite images that have been split into smaller 96x96 images. The test set for the competition was created by withholding a set of the larger composite images (not just randomly selecting some of the smaller images). This is an important distinction because it means that the test set consists of images that come from slides your model has never seen before, and in general that means your model will do worse on them.
I wrote up a little bit more about this if you’re interested: https://joshvarty.com/2019/03/25/validation-sets-matter/
I recently competed in a CVPR 2019 Workshop challenge, segmenting skeletons from 2 dimensional binary shapes. Using an image distance transform from a 2007 paper combined with “out of the box” fast.ai U-Nets, I managed 1st and 2nd places respectively in 2 of the 3 challenge tracks. Thanks to fast.ai for the tools to compete in professional computer vision conference challenges! 14 months ago I’d never done any ML/DL/python or maths beyond high school. Awesome fast.ai.
It was interesting to participate in an academic challenge where a paper also had to be submitted. In my non-ML/DL/DS day job the pursuit is to combine cheap, supportable, proven, flexible building blocks most effectively. Isn’t that the goal in most jobs? But in paper review terms that is known as “reject - no significant novelty is introduced”. No wonder when I’m looking for a solution I avoid the deluge of dubious academic papers but instead turn to blog/forum posts of practical implementations and spend my time trying to understand the dataset, not implement last week’s networks.
I really like your confidence chart, great idea 
Wow that’s an inspiring result! Congrats.
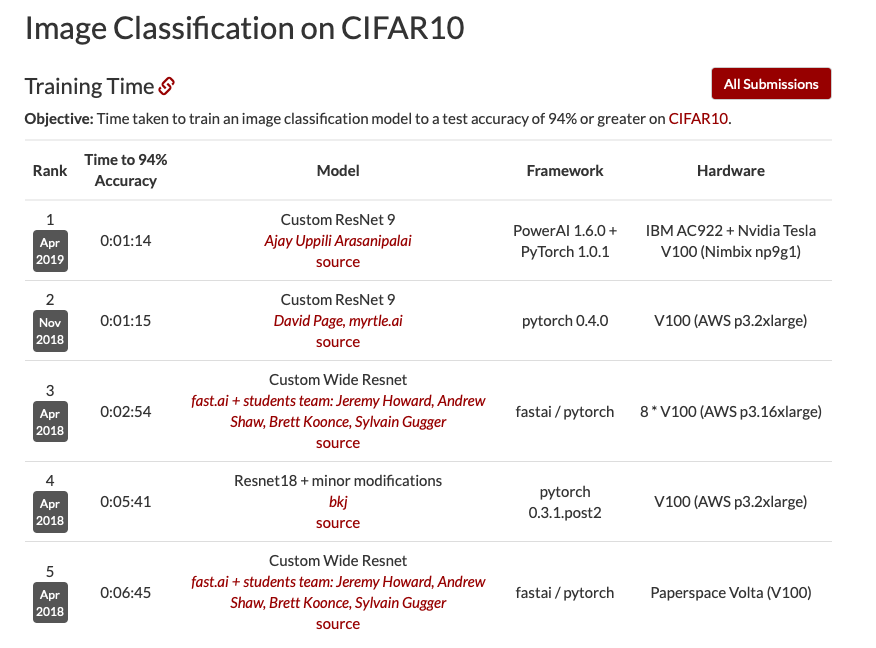
I set a new DAWNBench record for CIFAR10 training time! It’s only about one-second slower than David Page’s submission (and used the exact same code), but I still found it pretty satisfying. The only difference was the hardware.
I understand that one second means virtually nothing in practice, but I’m guessing that by using PowerAI and the AC922 chip, the percentage improvement might become more significant with larger models and datasets.
Though I haven’t had any formal CS education nor have I read about parallel processing in depth, so I’m not sure how this would scale. Can someone with more experience comment?
Hi all, would love to have feedback on this project/blog post. Not directly related to Part 1 of 2019 class, but it uses fastai v1 so hopefully appropriate to post here. The (custom, had to have fun creating a convnet called ZipNet) convnet didn’t perform as well as lgbm, curious if anyone had feedback on improvements. Thanks!