I have checked the github repo. it is really good work.
The data is huge, where did you find the data?
I gathered the data with the help of gi2ds tool from images.google.com.
For more information on downloading the data, you can check out this notebook of course.fast.ai.
2 Likes
During the last 2 weeks, I’ve been working on a project to upscale music using deep learning.
Here’s a link to the repo : https://github.com/StatisticDean/Crystal_Clear
I was very impressed by the results from lesson 7 of superresolution and I wanted to see if it was possible to get similar results in the musical field. So my idea was the following :
- Take the superres.ipynb notebook from lesson seven
- Find musical data
- Find a way to feed the musical data to the same model architecture
- Find a way to reconstruct musical data from the output of the model
- Enjoy?
To achieve that :
- I started looking for a good musical dataset. I stumbled upon https://github.com/mdeff/fma which had everything I wanted and more. 900 Go of free of right music with metada easy to download. At the moments, i only used the small version of the dataset which contains 9 Go of data in the form of around 8k mp3 files that last around 30 sec. This was perfect.
- To feed the data to the superres model, my idea was to interpret the spectrogram as an image and reconstruct that image. So for a given music, I took the stft using scipy with nperseg = 254 to generate a
n_channelsby128by thenumber of frames“image” where each point of the image corresponds to the amplitude of the frequency in a short window around the frame. The idea was to pass this image to the model, and then use the original phases from the music to reconstruct the music. Since the model eats square image with 3 channels, I did the following thing : create 1 or 2 extra channel(depending if the original audio was mono or stereo) and cut my long spectrogram in a sequence of square images. - To train the model, one needs to give it good quality data and bad quality data so it can learn to create the good quality data from the bad quality data. To “crappify” my musical data, i encoded in mp3 with a low bitrate(32k). At the moment, this is the only crappification I made, and I plan to test more varied crappifications.
- This is what it looks like


On the left, the crappified version is a much poorer spectrogram than the spectrogram of the original version. - 30 seconds of musics corresponds to roughly 82 windows of 128 frames which means I had a dataset of 600k images.
- The first thing I did with those image to have an intuition on if they could be used to realize my project was to perform a classification task. The music I had was split into 8 genres, so I trained a resnet to recognize the genre of a spectrogram. The result I had was around 50 % accuracy. This is pretty good considering with have 8 classes(much better than random guess), and each spectrogram corresponds to only around 0.4 sec of audio.
- Once this was done, I was confident that the project could work. In order to train the reconstructing network, I needed a feature loss. The one used in the superres.ipynb was based on a Vgg16 trained on imagenet. This was not very relevant for my kind of images so I retrained Vgg16 overnight on my classification task with my 600k images(- around 20% for validation), and I reached the same 50% accuracy I had with my first classification resnet. I did this directly in pytorch.
- At this point everything was in place, and I could start training the superresolution model. I used the featureloss from my new vgg16, and trained for a few epochs (4 epochs of around 3 hours on my personnal GPU). I havn’t had time to train more yet, or to unfreeze the network, so I think there is room for a lot of improvement here.
We can see that the model is filling in previously missing frequencies. - Now to apply the model on music, we take the music, generate its spectrogram, cut it in squares, feed it to the network, update the music spectrograms by using the old phase, and we’re good to go. It takes around 1 sec to deal with 70 windows on my GPU and 10 times longer on CPU.

TODO :
- A better reconstruction could be achieved by considering overlapping windows and for each frame, and average of the prediction of all the windows that contains this frame. We could also use overlapping windows to have a bigger training dataset.
- More training
- Use different kinds of crappification
- Use a bigger part of the dataset
- Make a web app to be able to use the model.
- Make my repo usable for training the models.
If you want to see(hear) for yourself, you can clone my repo and download the model from the link in the README. You just have to install the environment from the .yml file, and you should be able to use the model by launching the upscale.ipynb notebook. If you don’t want to download the model, you can just get the repo and use the 'sample.ipynb` notebook to listen to already processed samples.
I havn’t been over all the details of this project in this post, I’ll probably make a more detailed version later, this is to give you an overview of my project.
Please feel free to point out mistakes in this post or in the project, to make issues/PR on github, or to ask me any question about the project.
16 Likes
This is really great. Thanks for sharing
Hi,
Looks like the link to the notebook is broken. Can you please fix it?
Thanks
Very cool @anubhavmaity - I’ll have to revisit a similar project I did during part 1. I got to about 95% with resnet34 and 448x448 images - compared to your 299x299 and resnet50 that is better.
I made a classifier for Australian birds [https://github.com/Josh-Myers/Australian-birds-classifier/blob/master/birds.ipynb] - it’s really cool to be able to make something like this after only one lesson.
1 Like
I was interested in the fast.ai library and decided to watch the first lesson. I haven’t had so much fun with playing with a library in a while  In just an hour I understood how to use the library and get some results out of it*
In just an hour I understood how to use the library and get some results out of it*
My topic was of course cats: In what posture is a cat? Sitting, lounging, curled up or walking. The error rate was 17%, which is quite ok considering the bad figures and my own confusion on the definition of the poses 
There is a small writeup available on my own blog if you want to read the details:
https://www.vanderzwaan.dev/posts/2019/04/cature/
Given sufficient free time I’ll see if I can improve it. The final goal is to use a RaspberryPI and a camera to track my own cat and see how it actually spends it day.
*totally incomparable to the time it took me to get useful things out of other libraries and visualize it.
Hello everyone, I wanted to share work I did using FastAI library (0.7) at my company and this is also my first blog post! I am now working my way through 2019 version of part 1
TL;DR
- Area: AdTech
- Dataset: Tabular / Structured data
- Problem: Binary Classification
- Architecture: Two Layer Neural Network with Embedding for categorical data (with Negative Log Likelihood loss function)
2 Likes
Hi everyone,
I’ve made a blog post on creating a custom image dataset of African antelope and trained a classifier to distinguish each species. Learned some interesting things about antelope, and the intricacies of building your own dataset:
Any feedback is welcome!
1 Like
Hi,
I used fast.ai V1 with Retina-Net for cell detection on microscopy images and the COCO_SAMPLE dataset.
I have to thank @sgugger for his brilliant pascal VOC starter notebook.
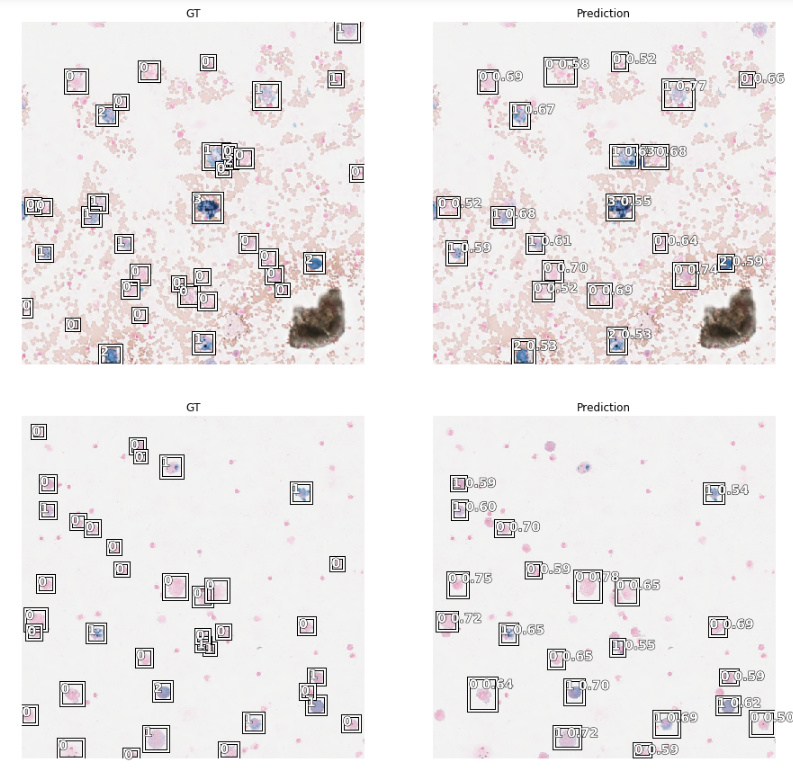
Feedback and likes are more than welcome
Repo:
With kind regards,
Christian
8 Likes
Thanks @StatisticDean for sharing your excellent work. do you think that’s its possible to perform real-time up-scaling of audio ?.
1 Like
Well, as I said on my post, if you take non overlapping windows, it takes around 1 second on GPU(Geforce 1070) to process a 30 sec audio file. So it depends of what you mean by real-time. It’s probably possible to do upscaling with less than 1 second delay, but I’m not sure of how fast we can get. This is a very intersting question though, and I would be happy to make some tests once everything runs smoothly
1 Like
Hi, dear @oguiza Would you please, share how did you encode time series in an image of a polar coordinate transformation called the Gramian Angular Field (GAF).
Hey @nialloh23 , I just read your post. I cannot access your colab files since I don’t have the permission to. But really nice work. Can you tell me how did you fine tune learning rates. Whenever I work on a project I use the tips Jeremy mentions in the videos like choosing the steepest downward slope and so on. Did you try learning rates before or after them? Or did you increase the size of your slices? What kinds of things did you do?
How i built an image classifier using Fast ai with small datasets - India is a diverse country with many different regional languages. During my recent visits to Hyderabad and Bengaluru, I was a bit surprised to see buses with name boards in regional languages alone . As a tourist, it is very hard to use public transport in these cities. I was interested in solving this particular problem using Deep Learning with fast ai. I wanted to build a mobile app which can identify the bus routes and give more information - source , destination, time etc.
I have built a webapp - https://bus-board-identifier.onrender.com/ . Working on the android app. Here is my blogpost on the same - Bus-nameboard-identifier
Link to my repo - https://github.com/bhuvanakundumani/busboard_blog
Thanks
4 Likes
Hi everyone,
Newcomer to fastai here. Just went through lesson 1 + 2 and thought I’d share what I have been working on recently. I’ve been working with the dataset on Kaggle to predict cancer from pathology scans in this competition: https://www.kaggle.com/c/histopathologic-cancer-detection/overview. It’s a playground competition, and I missed the deadline by a few weeks, but thought I’d finish the project anyway and blog about it. I’ve only gone through a few fastai lessons, but I found that I learnt a lot by just completing the project end to end.
I manage to get 98.6% accuracy which I think would have placed at about 10th place at the time so I was pretty happy about that even though I missed the actual competition.
I blogged about it here on my site which also happens to be my first blog post on machine learning, and also contains a link to download the notebook if anyone is interested : )
EDIT: just removing the line about placing 10th on Kaggle, thanks @stephenjohnson for pointing that out Kaggle’s calculating scores via the ROCAUC method so I need to do a late submission to find out what my actual Kaggle score would be.
1 Like
That’s very nice Alex!
Are sparse conv used only for segmentation?
Can you suggest a blog post or a link for more details about sparse convnets?
3 Likes
Hi Antonio,
Great work and nice write up. However, it looks like that Kaggle competition used “area under the ROC curve” as the evaluation method and not accuracy metric as you’ve used in your blog, so I’m not sure you can make the claim that your results would have finished in the top 10 of the competition. Have you done a late submission to the competition to see what your results would have actually obtained?
Submissions are evaluated on area under the ROC curve between the predicted probability and the observed target.
Hi @stephenjohnson thanks, and yep I don’t think I can make that claim, someone else pointed that out to me in another channel I was using the accuracy scores from fastai and assumed thats what Kaggle would use too. Working on submitting a late submission over to them and seeing what I get and updating my post. Thanks for your feedback and for checking it out!
1 Like