I didn’t go too deeply into this. You can try predicting buckets (5 year age bands) instead of exact ages to reduce some of the noise and get more ‘accurate labels’.
1 Like
Made a pokemon dataset and got 83% accuracy, guessing which pokemon there is on a picture. If you want to do something with pokemon images too please consider using my dataset: kaggle.com/mrgravelord/gen7-pokmon-image-dataset
It has more than 24k images and features almost every pokemon(except some forms like “Spiky-eared Pichu”).
I just launched Ask Roboflow, an AI trained to answer programming questions.
It’s the next step from my project last month, Stack Roboflow, which generated programming questions.
Give it a try, I’d love to hear your thoughts and feedback!
It’s learned lots of interesting things including how to insert HTML links and images into its replies, the syntax of several programming languages, and how to link to “relevant” documentation. And it even seems to be picking up a bit of a sense of humor; it replied “42” to one of my questions yesterday 
Unfortunately, one thing it hasn’t yet learned is the concept of “correctness” so most of the answers you’ll see won’t actually be helpful yet… I plan to continue to improve the model as time goes on. Hopefully one day it will actually be able to help new programmers get instant answers to their programming questions.
I’ve also published a Medium post about it. I’m thinking about following up with a post about the serverless architecture (Google Cloud Functions + Firebase) that I’m using if anyone is interested.
11 Likes
It will be helpful , if you could start a new thread for AI enabled question answering and post these there. Me too working on a similar task, will share details once i get respectable results.
1 Like
Great work Jason. Loved the way you used the learnings from fastai course to build all those apps. Keep going 
1 Like
Update on Crystal_Clear(My personnal project to upscale audio using image superresolution techniques). Since my last post 22 days ago, I had some time to make some progress on my project : https://github.com/StatisticDean/Crystal_Clear
-
Prediction is now parallelized and is 2-3 times faster. It takes around 0.5 sec to process a 30 sec audio on my GPU and around 60 sec if I use the slower processing method(Taking all overlapping windows instead of no overlapping windows).
-
I’ve created a Starter kit to process the data so you can do training yourself as well. At the moment processing the data is kinda slow(around 2-3 hours).
-
I’ve also worked with my brother to make a webapp.
The Back Office repo can be found here : https://github.com/StarAurryon/Crystal_Clear-BO
The webapp Link is the following : http://crystalclear.staraurryon.com
You can upload an audio file (mp3, ogg or wav) which will be taken through the upscaling algorithm and can then be downloaded.
Please keep in mind that this is a work in progress, and that the algorithm might do nothing significant or even deteriorate the audio. The algorithm has been trained with audio encoded in mp3 with a very low bitrate, so I would suggest feeding it low quality mp3 to see interesting results. If you perform some tests with the webapp and get outstanding results, please contact me 
7 Likes
It is great to see people make so many projects here. I’ve been working on them too. Two things I’ve learnt during this period are:
-
Execute code as much as possible
-
Write about it.
The second one has helped me learn things better. It has forced me to read more about topics to get a clear understanding of the concepts and put it in a cogent way. It has also given me visibility. I’d encourage everyone to write about their work. Here are some of my recent posts:
Lessons from my first deep learning hackathon
Collaborative filtering on song dataset
All kinds of feedback will be appreciated
2 Likes
I’ve been doing the course for a couple weeks and I’m at the halfway mark. I made a simple classifier that classified FIFA from real football and blogged about it on my blog.
However, looking at all the complicated things people are doing with this library, I wanted to take up a far simpler problem (for a human solve/code), and see if it was possible with NNs. Finding the maximum number in a list. Sadly, I was only able to get a 94% accuracy rate with 100,000 samples, which in my opinion is not great.
I’ve put up a gist on GitHub. I’m still new so I might be doing something wrong. Any inputs are helpful!
Dear all,
I have been going through the course since 2 weeks. I started my own image classifier to train the resnet34 model to differentiate between Pythons and Anacondas. Created a modest dataset (on kaggle) with roughly 40-50 pictures of pythons and anacondas. The dataset is not very clean(although I am not very sure the criterion to consider a dataset clean) and I get an error rate of around 10%.
Want to share this project here, and would love to hear your comments.
Thanks to the maintainers of the Kaggle notebooks whose work I forked, as the base kernel.
https://www.kaggle.com/pvaddina/pythons-vs-anacondas-using-fastai
Thanks
This is simply amazing. You put the information in such a lucid manner @daveluo. Thank you for much for such a clear and concise description of your decisions. Indeed an art
@swsaraf Was going through your Github repo for your nmslib implementation, and I had to comment that your notebooks are amazingly well thought out and constructed.
However, I am having trouble opening your resnet34 implementation on Github.
Thanks for sharing your work!
And i had to chuckle at this prediction

Just completed week 2. I present DeepThrones, a (very) basic Game of Thrones (some) character classifier. Identify the character in an image or, alternatively, upload a photo of yourself to discover your GoT alter ego.
I mainly used the lesson 2 script. 700 images each for six characters (Jon, Daenerys, Cersei, Jamie, Typrion, Arya) - 100 from each year from 2012 to 2018 (no spoilers!). I found that google image results for these searches became very poor after around 100 images. I deployed on Google App Engine using the guide (for others looking to do the same be aware that the guide is a bit out of date now and various fixes were required).
I needed to do extensive cleaning to delete duplicates and reclassify incorrectly labelled images. Ended up training on 2000 images, with 500 additional for validation, and achieved 90% accuracy, although the majority of incorrect classifications were on remaining poor images (usually misclassified or with no character present).
I found the heatmaps for images with losest loss particularly interesting (interp.plot_top_losses(9, figsize=(15,11), largest=False). The activations were clearly strongest around character faces, which makes sense:

Very enjoyable. Onwards to week 3.
5 Likes
Hi,
I’m working on a classifier using the resnet 50 model to distinguish between chicken pox, measles and scarlet fever spots based on Google search and download. Turns out measles is very likely to be misclassified as chicken pox or scarlet fever, but the other two are around 95% accurate. I’m working on improving the quality of data at the moment and use a bigger dataset. Will share as I progress, in the meantime anyone has a stronger dataset they can suggest for training, I’ll be happy to hear from you.
Just finished Lesson 1, and wanted to get my hands dirty. Used a gender classification dataset from Kaggle that has labelled images with their gender.
I got this setup on my notebook with the following results (ResNet50):
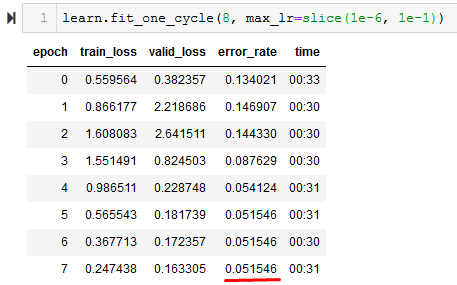
I noticed the image sizes that were used are not the same across the training set. Could that be the reason why the accuracy isn’t that great?
Here’s what the top losses look like:

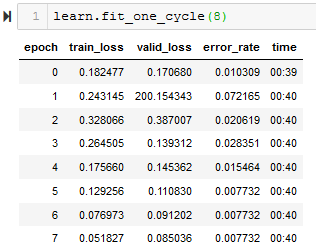
EDIT: Ran it again without learning rate optimization and got much better results:
2 Likes
Hi oguiza,
I have tried replicating your results from your gist without success, can you please let me know how you get the raw data that you are displaying in your graph to the left? When I convert the .text files to .csv from the OliveOil dataset, my graph of the TS is identical but does not have the spikes/outliers yours have:
Plot of all raw time series training data before normalization:
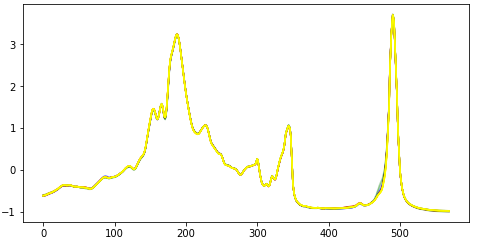
PS: If you have your CSV files with raw data, I’d really like to download them for comparison
Thank you,
Pal
Hi @sadaf
The encoding is described in the pyts package documentation: https://pyts.readthedocs.io/en/latest/auto_examples/image/plot_gaf.html
Note that their API have changed since @oguiza created his example, but they have examples on the documentation page on how to use it.
Thanks,
Pal
Hey ho.
I just did the exercise for Lesson 1 and wanted to share my notebook (cloned from Lesson2-download)
- I added some functions to dont repeat the image download and folder creation part , maybe this is helpful for anybody who has more than 5 categories
- I just decided to classify between five martial arts
So all in all I want to participate inside the forum and try to give sth back, if I can
Cheeers!
Hey, its me again:
Also I want to share my Blog Post “Learning Machine Learning Part 1” (written in German), so I hope some german friends want to check it out ! 
tldr;
Blogpost is about my motivation and plan on how to learn machine learning, starting with the basic machine learning course from AndrewNg and afterwards doing fast.ai for Coders Part 1 (so here I´m currently), some Kaggle Challenge and the Deep Learning Specialisation from Coursera (Andrew again.)
Does anyone have a possible way to evaluate the effectiveness of an encoder. That is if the Latent Space is a true representative of the images feature, and what should be optimum length of this vector.Should we treat the length of the Latent space vector as a hyper parameter. Is understanding the effectiveness of an encoder even possible and if yes, then is it relevant ? One possible way that I can think of is decoding the input from the Latent representation and getting the accuracy of that i.e how similar are are input and the decoded signal. On Second thought maybe we can use this to train the encoder ? I am basically training an Image based encoder followed by a sequential (LSTM) decoder. Is it possible to train the model as a single end to end system i.e. getting the model to back propogate even to the encoder layers. @jeremy
Hello guys, I had implemented a facial expression recognizer.I had created my own dataset by scraping the web and also some publicly available datasets.Check it out and share you opinion.
3 Likes