Whats the difference between tabular data + NLP (title) vs Full deep learning model in your sections?
Fastai is just amazing! I used it on the Kaggle Competition: Facial Keypoints Detection and got a score which I believe places me in the top 30%. Check out the competition here:
I made a custom loss function for this and I learned how to detect multiple image points starting from the fastai course example which demonstrated single point image regression. If you are interested, here is the kernel that produced my best submission:
https://www.kaggle.com/nitron/facial-keypoints-fastai-image-regression?scriptVersionId=14145733
4 Likes
Hey @joshfp!
Thanks a lot for sharing this. I have had some good results with your approach at my job with reply.ai. The task is to classify customer support tickets and combining text and tabular metadata is absolutely crucial here.
With the current implementation a lot of the fast.ai functionality does not work. Most importantly it is hard to put the model in production because getting a prediction on a single datapoint is not supported. Also get_predictions with the order=True flag fails. Would you be interested to collaborate on a better integration? I think @quan.tran might be interested , too.
2 Likes
Real Time Handwritten recognition CHALLENGE
(Recognizing digits in the wild)
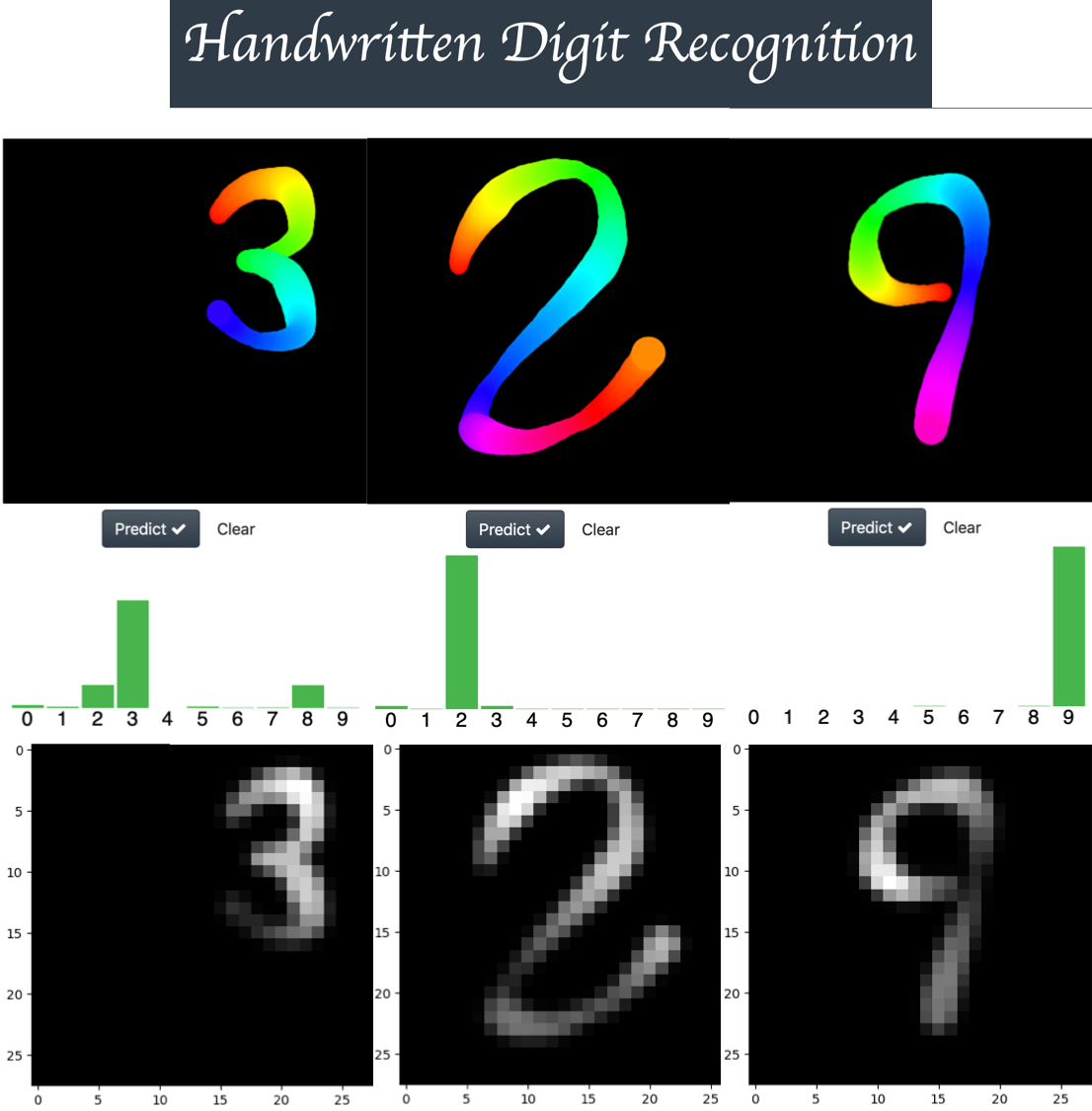
Hello everybody I have been reading this thread since I joined this wonderful course a month ago and I think this thread is amazing, so many high quality projects in one place.
Now, I want to share a little project that I have been developing this week. My intent was to build a reliable app for handwritten digit recognition under adverse conditions (with a pen tip that changes its size and color during the drawing process) using the MNIST dataset. If you want, you can play with the app using the following link (EDIT – SUPPORT ADDED FOR TOUCH SCREEN DEVICES)
As shown in the figure above, the width and color changes as a digit is drawn and cold colors (like blue) generate low intensity strokes, (you can see this when the images are converted into an MNIST format image). So I think this app is a good way to challenge the true performance of any neural network architecture.
Interesting results
As humans we tend to associate abstract ideas to familiar concepts, for example you can see an smiling face just here ( = ) ). So I tested if the networks that I trained share this ability of recognizing abstract representations of a digit, but at difference with the pathological cases of the MNIST set (where some digits are unrecognizable for any human being), I used representations which are easily recognizable for any of us. In the image below I shown examples for the following numbers:
row1: 4 8 5
row2: 6 7 4
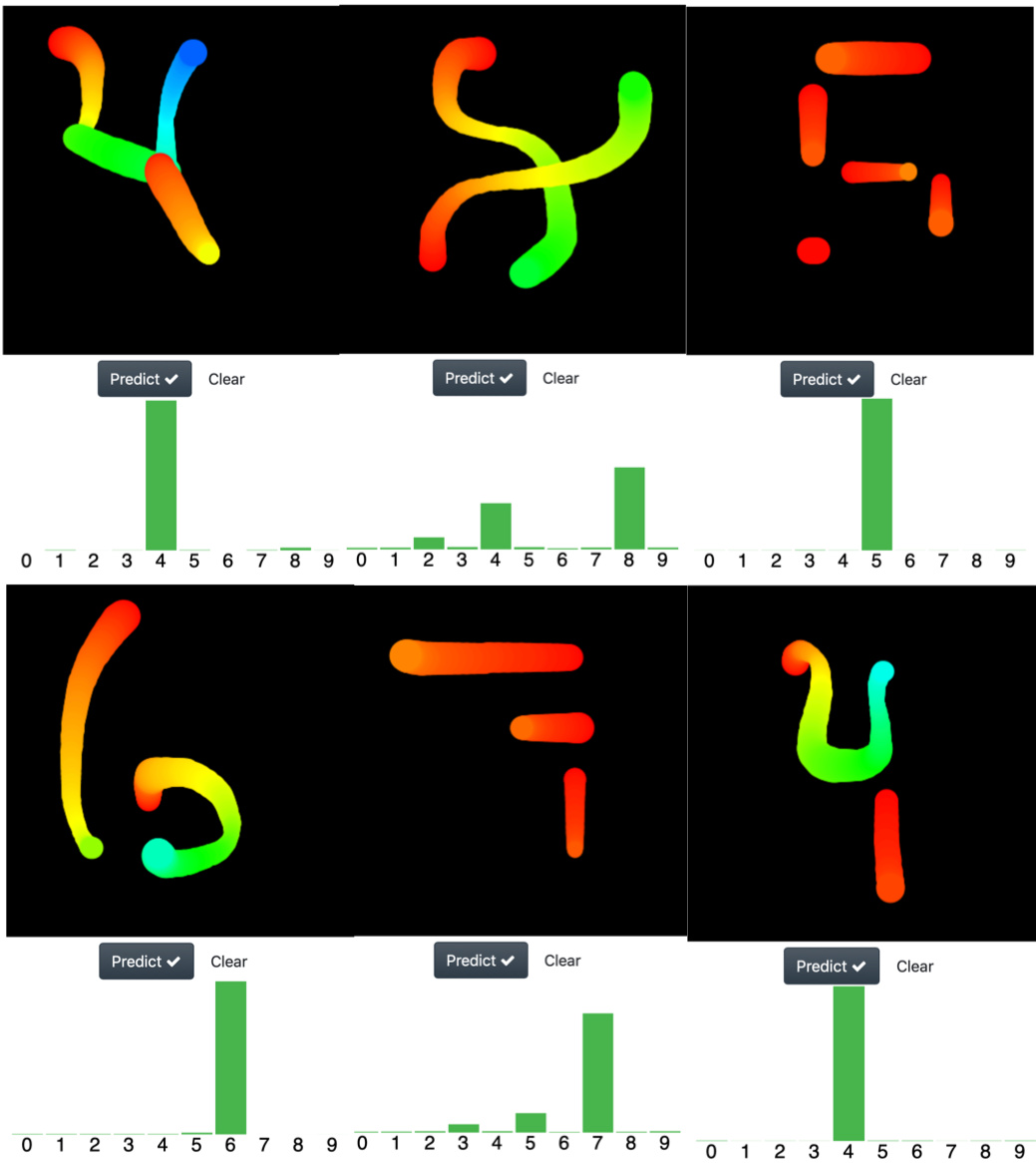
I was amazed with the performance of the nets, so I pushed them a bit further in its ability to recognize abstract representation of digits with the following images.
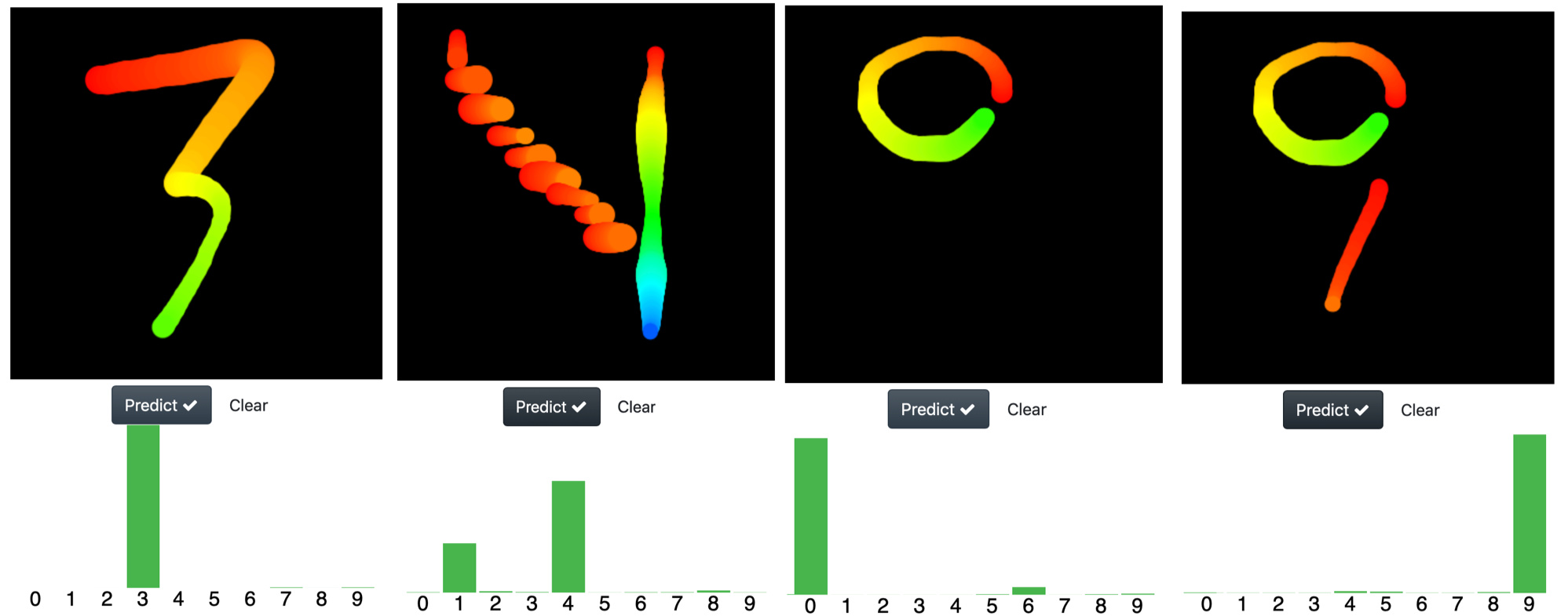
Particularly a challenging one was the digit “4”. I drew it as descending stairs from heaven with a rainbow waterfall at the background (yeah all that is there, you can see it? 

 ) and the net can do it very well, it chooses the number 4 but it also get doubts and give it a chance (a probability) to the number 1 (a very reasonable choice).
) and the net can do it very well, it chooses the number 4 but it also get doubts and give it a chance (a probability) to the number 1 (a very reasonable choice).
Who are those neural nets?
To make the things fun I decided to test three different neural networks architectures to see which one generalized better on unseen samples, the architectures are:
-
The “resent-ish” CNN coded by Jeremy in this notebook
-
The “lenet-like” CNN based on this kaggle kernel , (I code only one of the fifteen CNNs that are originally proposed)
-
The “Capsule net”, the capsule net is a very cool and clever idea which make used of spatial information contained inside the image to improve its performance. Indeed I found the capsule net amazing because for me the idea behind the routing agreement algorithm looks very similar to the idea behind the determination of eigenstates in quantum physics. I use this GitHub repo to build the network
Which one performed better?
I didn’t make any rigorous statistical analysis to answer this question, so all I can to say is subjective to my experience testing each network while I was playing around with the app. At the begging the best one was the resnet-ish cnn, because I trained the other two using pure pytorch but I found hard setting the right hyperparameters. Letter on I trained the “lenet-like” using fastai and its performance increase considerably. So right now I can say both, the “resnet-ish” and the “lenet-like” architectures performed equally well under the conditions of my app.
With respect to the capsule net, I tried trained it using fastai but I can’t achieve good results at all, (the net made very obvious mistakes and always show a very high training and validation losses for all the learning rates I tried ). Indeed this is an interesting result and I will try to review why is this happening.
So I trained capsule net using pure Pytorch (following the condition stated in the paper, using Adam and without schedulers). After my training with Pytorch, the capsule network performs almost as well as the other two, but not as well. It has troubles in recognizing digits written at the corners of the drawing area. Also I have to include the same random affine transformations I used for the other two networks during the training process to improve its performance (scaling (0.5, 1.3) , rotations (15º), and translation (0.1)). That is interesting because in theory this networks doesn’t required of this kind of data augmentation to generalize on unseen rotated or shifted samples of the same kind of images used during training.
The capsule network works as an inverse decoder. How do the reconstructed images look like?
Yeah, another cool feature of the capsule net, is that it works as an inverse image decoder, so it’s possible extract the image that the neural net “think” it is seen. Below I show interesting examples of this.
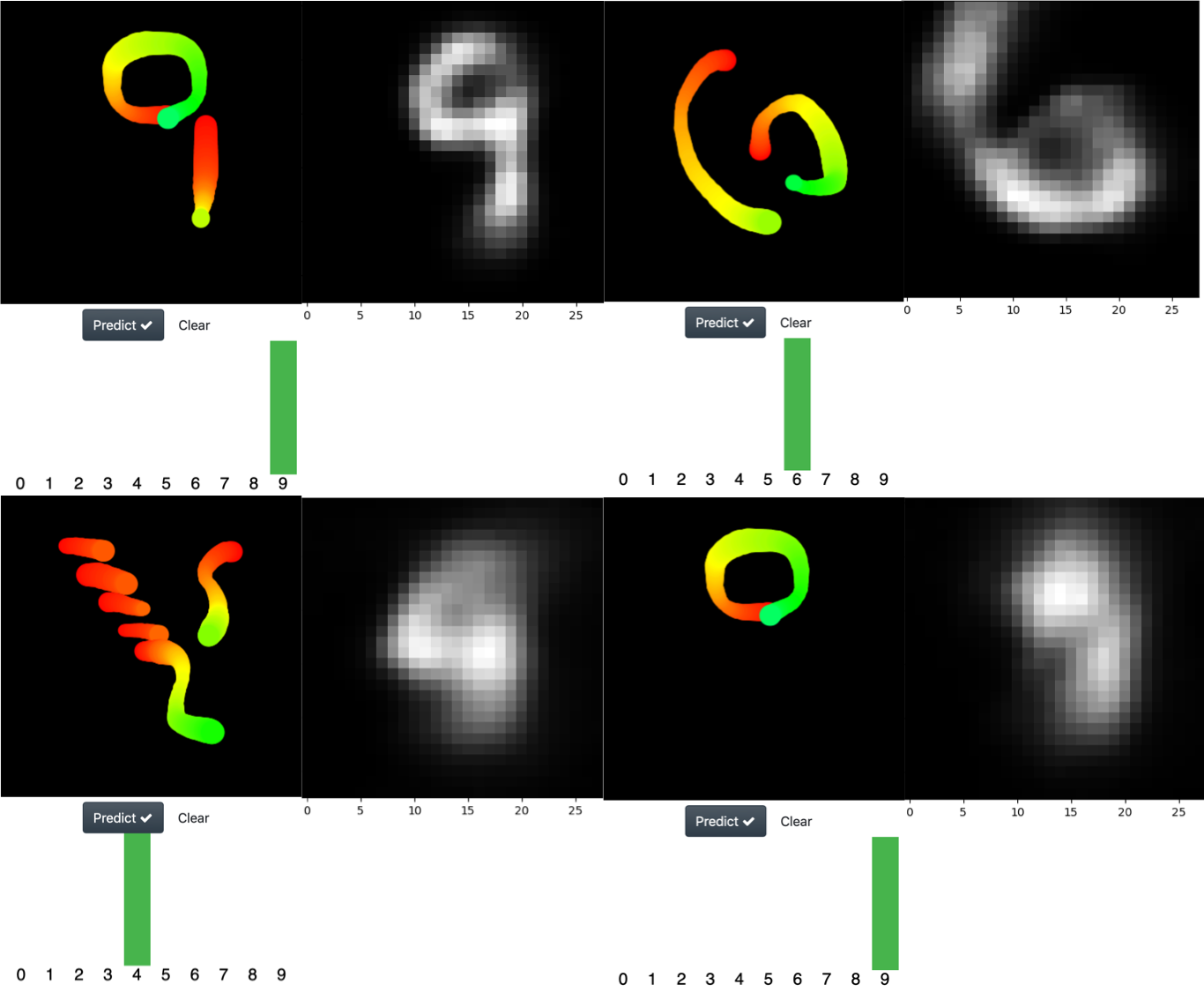
At the left is the drew digit and at the right is the reconstruction performed by the network. As you can see, in the last image the net confused a zero with a nine
Why the capsule network wasn’t the best performer?
Quoting the original paper
There are many possible ways to implement the general idea of capsules. The aim of this paper is not
to explore this whole space but simply to show that one fairly straightforward implementation works
well and that dynamic routing helps
So, maybe the current architecture isn’t the best one possible to implement the idea. That was also one of my motivation for this project.
Is the code available?
Yeah, you can get the code from my GitHub repo. There, I wrote an easy to follow guide (I think) explaining how you can easily add your own architectures to the app or how you can use the ones that are already available (resnet-ish, lenet-like and caps-net). So you don’t need to waste your time understanding my code, you only need to named your net architecture trained with fastai or pytorch (saved them as a .pkl or .pth), put them inside a folder and that’s all, you can have some fun drawing abstract representations of digits in your screen and “test” how good your nets performs under this hard conditions.
15 Likes
Awesome!
I’m into week 2 and loving the course so far! I made a web app to classify fashion clothing items. The models were trained on DeepFashion dataset using Pytorch and do category classification. I have been using pytorch for some months now but fast.ai gives a lot of cool things out of the box. Inspired by grad cam visualizations shown in fastai’s top_losses function, I tried to depict the class activation mappings in the subject images. Here is a link to my github repo )
Any feedback is welcome.
Keep learning
5 Likes
Hi Everyone
I trained a resnet 34 to classify between oneplus6 and oneplus6t mobile models. The model performed above my expectations considering these two sets of devices have a very minor difference between them and that is their notch
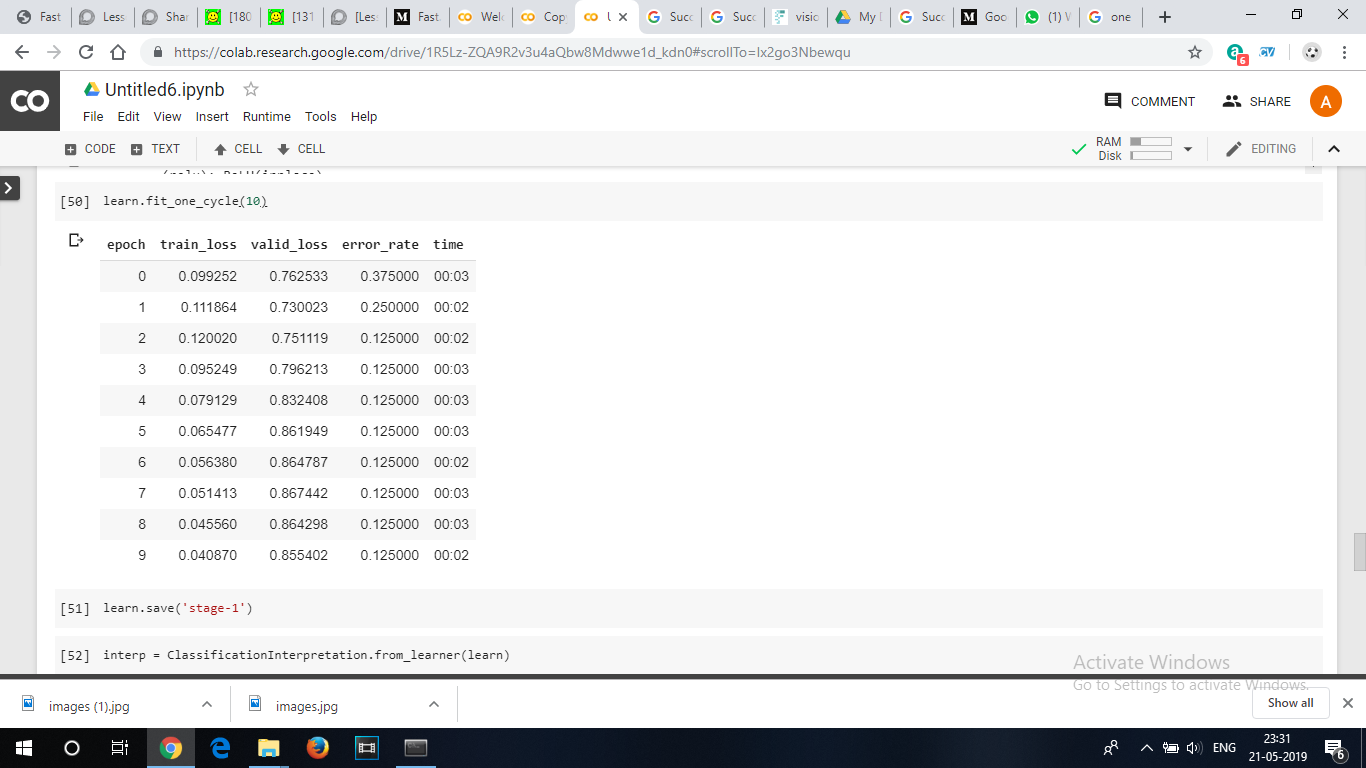
the training data set had just 20 images of each model and validation set had 4 images of each and the model’s error rate was 0.125 which stopped reducing after certain number of epochs.
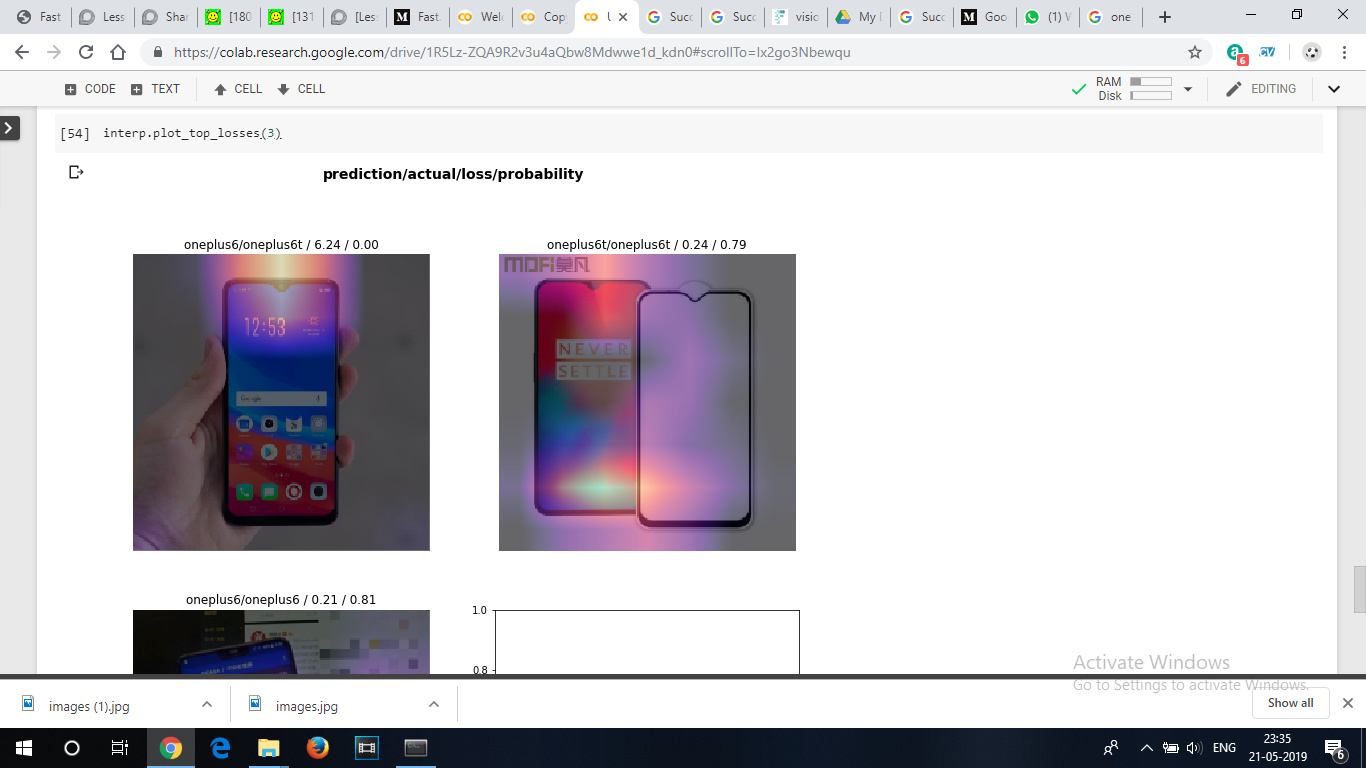
1 Like
Hi everyone,
I’m currently in lesson 2 and wondering how to make a real-time object detection model. If anybody has worked on the above stated kindly help me out.
Thank you
I completed lesson 1 and used the lesson 2 download notebook.
I downloaded images of different types of racing car;
- Formula 1
- Formula E
- Indycar

These cars look very similar and so I thought it would be a good challenge for resnet34 to classify.
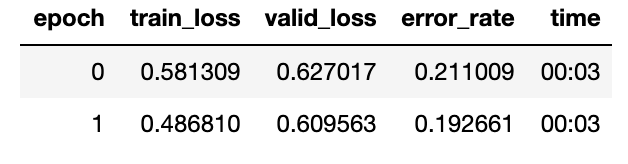
After around an hour of work I got to around 80%
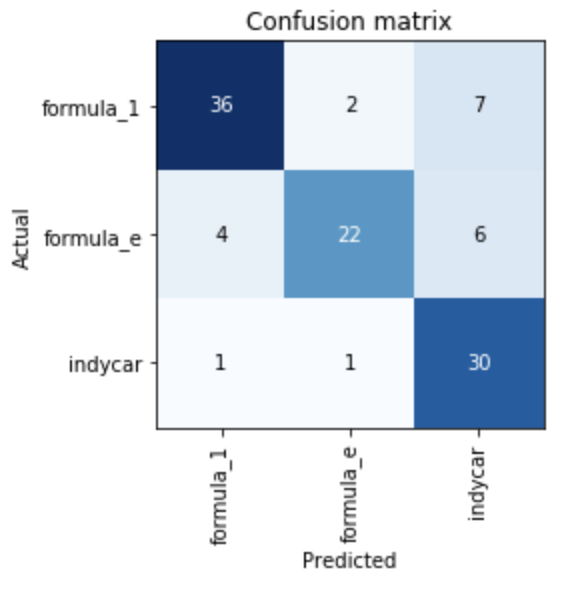
The result is not bad, but the data could be a lot cleaner. I also suspect that increasing size of dataset would help.
I did all the work on my custom built linux machine at home with a threadripper CPU and an Nvidia 1080.
I used a batchsize of 32.
2 Likes
I created a model which takes photographs of diseased eyes and categorizes them by disease. Error rate is still 25%, which is too high, but perhaps due to the fact that many diseases overlap i.e conjunctivitis will be present in orbital cellulitis almost always.
Looking forward to taking lessons 2+ to see how I can train with multiple labels per image.
The link now shows a 404 error. Can you please reshare?
Presenting “Wall Doctor”; an image classifier to identify common issues in wall painting such as blistering, patchiness and microbial growth.
The idea is for consumers to post images to a painting/home service solution and give the service provider a better understanding of the issue. Please go through the notebook and let me know what ive got right/wrong.
A question related to implementation : Supposing someone posts an image of their wall with some objects in the room, how do I seperate these seperate objects during training and classifying as my main object of concern is the wall in the room itself and no the chair/table/dresser in front of it?

3 Likes
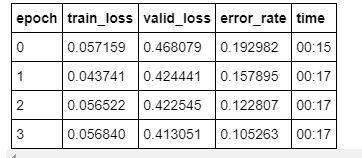
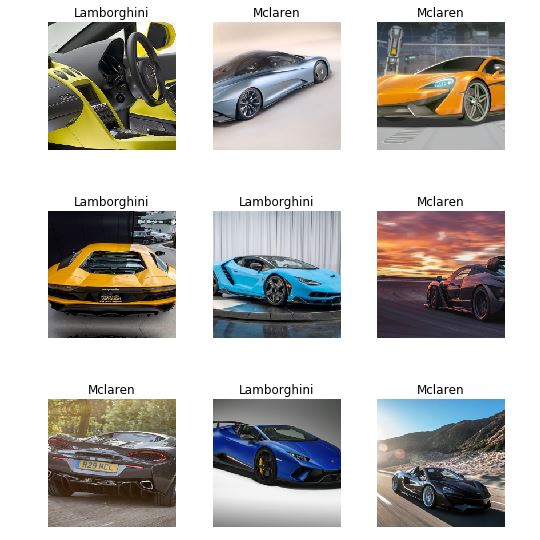
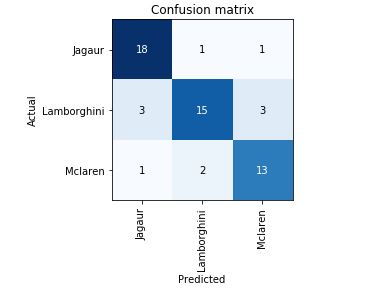
After watching Lesson 1, started building resnet34 for classifying Lamborghini, McLaren, and Jaguar Cars in google collab by creating a custom dataset from google images. Achieved quite low 50% accuracy without doing any changes.
Going through the forums helped resolve several issues. Tried resnet50 with bs=64, cleaned the dataset, run 8 epochs to achieve 80% accuracy. Further working with LR Finder to obtain the optimal learning rate and 4 epochs helped achieve 90% accuracy.
These are the Links in the fast.ai forums
which helped me to fix the errors and move on from 50 to 90% accuracy. Github link
Quite excited to build a deep learning model on my own in a week’s time with 90% accuracy  Thank you for the vast info in the forums which are very much helpful for self-learning!!
Thank you for the vast info in the forums which are very much helpful for self-learning!!
Moving on to lesson 2
3 Likes
For lesson 3’s homework had a go at segmentation using the data from the current iMaterialist (Fashion) 2019 at FGVC6 on Kaggle.
I thought I’d have a go at using a Kaggle kernel - here, with more detail, for anyone interested.
Time, compute and skill limitations meant I had to simplify the task. I used a smaller set of categories, smaller images and just 10% of the training set. Still got what I thought were pretty good results regardless - 88% accuracy (excluding background pixels) and in many cases very reasonable looking results (actual on left, predicted on right).

Really enjoying the practical side of the course, so I’m trying to keep up with doing a personal project for each week.
6 Likes
And how did you ended up with evaluating tabular model on a new dataset?
I’ve encountered with a similar problem and I’ve ended up writing my own bunch of functions to do that (you can see in this post Some useful functions for tabular models and in this Rosmanns’s data notebook https://github.com/Pak911/fastai-shared-notebooks )
2 Likes
Hey everyone ,
Please refer to the quoted post for my implementation of “Wall Doctor” a hypothetical consumer app on which users can upload images of their room walls to identify common issues such as microbial growth, patchiness,blistering etc. and get suggestions for solutions/remedies/products accordingly.
I am currently trying to setup an image segmentation model to ‘segment’ different objects in the room such as furniture, paintings, and the wall itself.
My question is : How do you use the output of an image segmentation model?
In the lecture Jeremy uses show_results to display the ground truth vs predictions but how would you use this output in an actual application? Can i get the pixel values of my different identified objects and return them accordingly?
1 Like
 Love it
Love it
1 Like
@alvisanovari Love it - wish it were still up in production. https://cold-or-canker.now.sh/
link down?
1 Like
Hi @tank13
I am struggling to deploy my text generator.
Can you give me some advice on what service is easiest and maybe some example that I can re-use?
Thanks a lot in advance!
Hi everyone, I am currently on lesson 5 where Jeremy taught us building a N.N for mnist dataset from scratch using fastai library and pytorch. Here, I am sharing link to my .ipynb file which contains the code for N.N from scratch just using python and numpy. Hope, you’ll find it useful. This notebook is inspired by the 'Neural Networks and Deep Learning" course taught by Andrew NG. You can tap on the link and click “Open with collaboratory” to see the code
https://drive.google.com/file/d/1Sk9XC6OdC5gsIaYlTXPM5crTtGPqC2Ij/view?usp=sharing