Hi everyone, I am currently on lesson 5 where Jeremy taught us building a N.N for mnist dataset from scratch using fastai library and pytorch. Here, I am sharing link to my .ipynb file which contains the code for N.N from scratch just using python and numpy. Hope, you’ll find it useful. This notebook is inspired by the 'Neural Networks and Deep Learning" course taught by Andrew NG. You can tap on the link and click “Open with collaboratory” to see the code
https://drive.google.com/file/d/1Sk9XC6OdC5gsIaYlTXPM5crTtGPqC2Ij/view?usp=sharing
In what form are you trying to deploy? I had a lot of trouble getting mine to work as a web app, since I wanted to use free services only. One I put on Zeit v1, though I believe that since they moved to version 2 the approach I used won’t work anymore. The other one I deployed using the Google App Engine, which was also a huge headache. I used GCP to train, and I built a docker image on my GCP instance and then deployed that, but it took multiple attempts before one succeeded and I think I was doing the same thing each time (I’m also super inexperienced when it comes to docker, so others might be able to deal with this better). But then some time later it just randomly stopped working, and I just haven’t gone through the steps again.
Sorry I don’t have anything more helpful to share! But broadly, I’d recommend going through the steps in the ‘production’ sections (e.g. https://course.fast.ai/deployment_google_app_engine.html) and dealing with specific problems as they arise. The process was definitely not smooth for me, but after a lot of googling and multiple tries, I got things to work… at least for a while!
Very interesting use case!
Bears, Beets, Battlestar Galactica
Unfortunately I took it down a while back. It’s not that hard to setup though, you can leverage the Lesson 1/2 (teddy bear?) notebooks.
Thanks,
I also deployed the image classifier in the past in GCP but I hardly remember how. Only that I found maaaaany errors that I fixed painfully one by one.
I will review the production sections. I don’t mind paying a small price if it makes things easier… so anyone reading this: recommendations (or better, examples!) are welcome 
Thanks a lot
You might want to have a look at this , in case you haven’t seen before. Might be useful for what you are asking. thanks
https://forums.fast.ai/t/image-segmentation-understanding-inference/45855/13
Who is the artist?
For lesson 1 assignment, I used kaggle artwork dataset of paintings by 50 artists and tried to classify the artist.
Results summary:
Resnet34 with 4 epochs on top layers gets 33.8% error rate.
4 epochs of fine tuning reduces the error to 21.5%
Resnet50 with 8 epochs on the top layer (no unfreeze) achieves 20% error rate
10 more on all layers (unfreeze) results in 15.5% error rate
Further training would probably continue reducing the error rate but I am not sure whether it is over fitting.

Interesting to see the error analysis
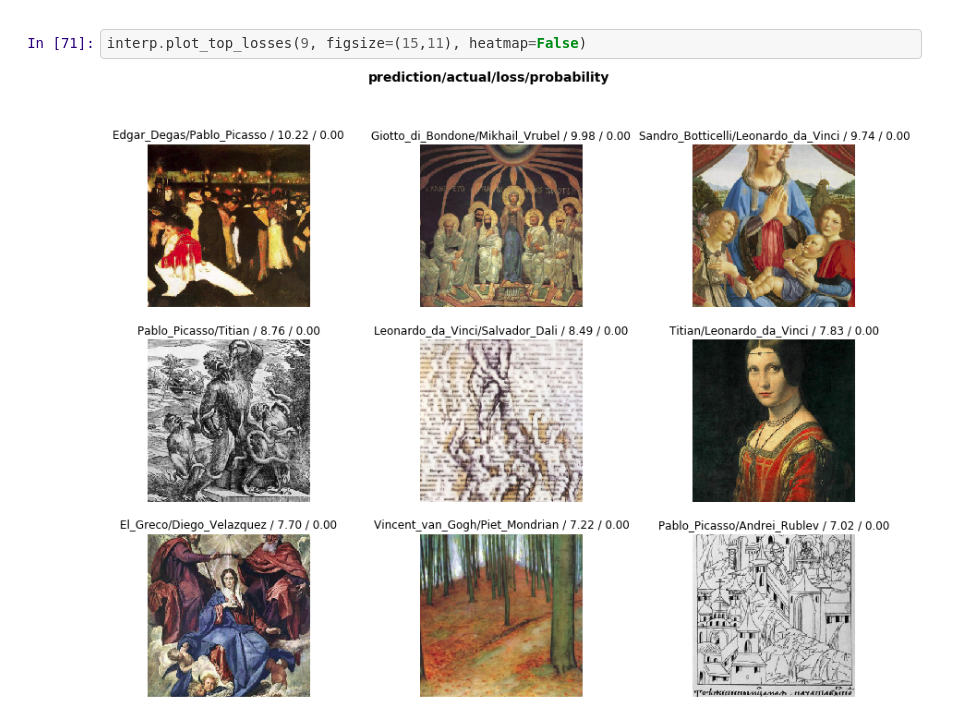
3 Likes
For some reason, it says i do not have access to this topic 
This is because it was posted in the Part 2 forums. Here is the URL of the the notebook that was linked in that post:
I made a Penguin Classifier, based on the bears example from lesson 2 of the course.
https://www.patagoniapenguins.org/which-penguin/
It’s deployed as an AWS Lambda function, with a client-side website using knockout.js.
If you’re interested the code is in my github repository:
server side: https://github.com/LauraBromley/penguin-inference-api
client side: https://github.com/LauraBromley/penguin-inference-static-site
I downloaded my images using google image search, and I had about 130-170 in each category. I used a resnet34 and the defaults for training (as per the lesson), and found that my error rate was quite a bit higher than the examples in the lessons - the best I got after running a few cycles was 0.08.
So I was wondering why my accuracy is not so good… these are my initial thoughts:
-
There are 17 species of penguins, but quite a few of the species are very similar and even from a human perspective it’s difficult to tell the difference between them.
-
Penguins hang out in colonies and so it is difficult to find photographs of individuals. I wonder if this is a problem since the images used for inference will probably also contain multiple penguins?
-
The distinguishing features for penguins are normally in the head (beak colour, crest etc), and their bodies are pretty similar (white front, black back) so I thought maybe when the images get cropped, parts of the head are missing? I did try changing some of the image transforms (resize_method etc) but I wasn’t able to improve my error rate.
Does anyone have any thoughts on what I could try?
2 Likes
You can give mixed precision training a go. As you go through more lessons, you will get more things to try. I was in your place when I started the course. Later, I often found myself wanting to go back to older projects and try things out. I did that or tried both the things on a new data set because I love exploring data sets as well. Cheers.
1 Like
I’ve posted some more articles on medium:
Sound classification using spectograms
Momentum, Adam’s optimizer and more
Dropout and an overview of other regularization techniques
I’ve learnt a lot in this course and I am really excited for the last lecture and the kind of things you can do with U-Net. I would suggest anyone doing this course to stick to it. It is easy to keep switching courses, but fast.ai is the real deal.
1 Like
That looks awesome! I couldn’t find the notebook you used to train your model but it’s usually good to plot_top_losses and plot_confusion_matrix when things aren’t as you expect. You might find that some pictures are mislabeled or the learner is looking in the wrong place or 2 particular types of penguins are similar. You seemed to have cleaned your data well, though. You could try and adjust your transforms: larger images, no warping, and lower contrast, but you’ll just have to try things and see how well it works.
1 Like
Thanks! Yes I should probably put my notebook on my github page, I haven’t done that yet.
I have been using the plot_confusion_matrix, and I know that some of the penguin species do look alike, but it is also getting species confused that have quite different features. I am currently trying some experiments with changing the transforms to see what helps.
Thanks, I will definitely try mixed precision training
1 Like
Hello!
I made an environmental sound classifer called WHISP that classifies sounds from 50 categories, trained on the ESC-50 dataset.
You can try it out here! https://whisp.onrender.com/
The code is up here on Github: https://github.com/aquietlife/whisp
I also wrote at length about WHISP, the ESC-50 dataset, training an environmental sound classifier, and some insights i had along the way while testing it in the field on my blog: http://aquiet.life/
Please let me know what you think! I’d love to get connected to other people using ML/AI in the sound/audio field 
4 Likes
Hi @dipam7,
I’ve take a look at you post: It’s not a good idea to use default image data augmentation on spectrograms (especially big rotations and vertical translations):

If you want some suggestion on sound data augmentation on see: Deep Learning with Audio Thread .
5 Likes
Hey, thank you for the feedback I’ll change that, I knew it but maybe I did not incorporate it while coding it. I was actually having trouble with generating spectograms on Kaggle. If I generated more than 500 output files I couldn’t commit my kernel. Switching to colab now. Yes I’ve referred to the thread as well. Thanks again.
I made a classifier that recognizes images among 3 sports: rugby, wrestling and American Football.
To make the challenge interesting, I purposefully took images in the tackling motion in each of the three sports. Learned couple of things: a) CNNs are awesome. Got 90% prediction success rate within first try. b) errors were due to bad data, meaning when searching for rugby, some images of American football were also picked up by Google Images. So the algorithm correctly identified as football but since it was labeled rugby to begin with, it was counted as incorrect 
wrote a medium blog post about it… looking to explore another use case using different sets of images.
https://medium.com/@parth.bme/deep-learning-with-fast-ai-engine-makes-it-speed-learning-52ab8564d184
1 Like