Hi, I just reviewed the Transformer-XL paper and architecture which is implemented in fastai. The improvement over Transformer is quite interesting and makes a lot of sense. You can find it here. Let me know what you think!
2 Likes
Hi @lesscomfortable I’m not familiar with Transformer architecture, will definitely take a look but I’m not doing text classification.
I’m trying to train a classifier that takes the poster of a movie and tries to predict the genre
Hey! That’s a computer vision problem, my post is on NLP.

 Thank U @hwasiti , great tip , definitely need to delve more into the Documentation.
Thank U @hwasiti , great tip , definitely need to delve more into the Documentation.
1 Like
I managed to get 98% accuracy classifying speakers from a small dataset! More details:
2 Likes
Hi all - happy to share my results in using FastAI and Resnet152 and a lot of differential learning rate cycles on a cellular histo-pathology dataset - up to 100% accuracy!
I saw two papers on this dataset and noticed that in both cases, the CNN’s they were using were pretty bland and in addition, very standard practice of a simple fixed learning rate, etc. One was from summer 2018, so while relatively recent, I could see the techniques we are learning here are way ahead of the curve.
I thus took it up as a challenge to apply FastAI to it. Interestingly, I started with Resnet50 and while it got to 98% and was very stable there, it became stuck on two very similar classes and could not move beyond it. I ultimately had to restart with ResNet152.
That still took a lot of cycles with the learning rate finder and differential learning rates, and a very steady train/check learning rate/ retrain process, but I did manage to tune it to repeated 100% results and thus outdo both of the papers in accuracy by a reasonable margin.
(91-95% was their best, and in one case they oddly only tested subsets of 4 classes to get that averaged 91%, not all 20 at once).
8 Likes
Hi everyone,
I’m glad to share my first computer vision project (Irish Gaelic Footballer Classifier!)

After completing lecture 1 of FastAI I decided to build a data set of Irish Gaelic football team players.
The goal of my computer vision classification model was to distinguish which players played for which team. Out of interest I built and trained my model using both Keras and FastAI.
*** FastAI Classification Model:** (Best Result: 92% Validation Accuracy) Link to Collab File
*** Keras Classification Model:** (Best Result: 91% Validation Accuracy) [Link to Colab File]
Some practical things which improved my model:
- Data augmentation seems to work very well for small data sets (+8% Acc Improvement)
- Fine tunining on learning rate seems to work well (this feels like a very important hyperparameter)
- Tracking the Train & Val error allowed me to diagnose under fitting issues. Adding more capacity to my custom CNN network in Keras gave me some big improvements (+12% Acc Improvement).
- While it was easier for debugging & experiments with lower epochs I found for my final models increasing the number of epochs gave me better results. I could see this trend from the training curves (+4% Acc Improvement)
- I completed a visual error analysis of the misslassified images with the biggest loss. I removed images from the validation set which were clearly misllabelled. (+12% Acc Improvement)
Some other takeaways from the project:
- I was suprised by how similar my results were between Keras and FastAI. I used a custom CNN network architecture using Keras while I used Resnet 50 architecture using FastAI (I didn’t do a like for like comparison).
- Building custom image datasets isn’t as hard as I thought it would be and it’s far more rewarding than using out of the box datasets
- Google Collab seems super useful for these quick hacky projects
10 Likes
Hi @tank13,
Did you finish running the file dl2/imdb.ipynb. can you share me the model output such as lm_last_ft, lm1, lm1_enc, clas_0, clas_1, clas_2 …
It took me a lot of days to run all of the fit() commands. Please help me if you have these model files, thanks.
Hi everyone,
I tried to create a milti-label classifier that takes a movie poster as its input and predicts the different genres of that movie.
I thought it was an interesting experiment regardless of the results and definitely learned a lot while doing it.
You can find my final version on this repo. Any tips or recommendation is welcome.
My final result is ~0.59 f2 score but I’m not sure how to evaluate that, I didn’t find other classifiers to compare my results so if anyone knows about other solutions I’d love to see them.
I found that ClassificationInterpretation was lacking some functionality for multi-label classifiers, I created some functions manually but if anyone knows about how to interpret results in multi-label problems better I’d appreciate it.
Great work @oguiza I am reading all the thread on the TS study group and I am going to try our your examples on my dataset. One concern: the paper looks to be a broken link:
https://aaai.org/ocs/index.php/WS/AAAIW15/paper/viewFile/10179/10251
gives
DB Error: Table ‘./aaaior5_ocs/sessions’ is marked as crashed and should be repaired
It’s only me?
Any other link to the paper?
I have trained a classifier with fine tuned embedding language model which assigns content labels to basic restaurant descriptions. So you have a text like:
The three star coffee shop, The Eagle, gives families a mid-priced dining experience featuring a variety of wines and cheeses. Find The Eagle near Burger King.
And the output are the following labels:
eatType[coffee shop],
food[French],
priceRange[moderate],
customerRating[3/5],
kidsFriendly[yes]
This is the dataset used for the e2e Natural Language Challenge which consists of 50k <text,content labels> pairs. It achieves an F-score of 92% thanks to the gradual unfreezing of the layers.
You can find out more in my kaggle kernel. Comments are welcome.
1 Like
Thanks @marcello_m! Could you please point me to the right reply where this link appear. I don’t have any context and don’t know which is the linked paper.
That is super impressive. Exploration in latent space is intuitive for explaining the network output results. The whale output in addition / subtraction gives you a fuzzy reassurance that the network indeed learned something. Congrats on the gold medal.
At some point I want to get back to the experiment and pretrain the loc2vec network based on multilabel classification. I have a strong hunch that it would be performing far better and easier to train as it would have seen relevant content and learned from it.
1 Like
Sure, sorry for being so vague!
In the post here Share your work here ✅ you refer to a paper about TS to image transformations.
I hope the link works!
I’ve tried to edit the link in my previous post, but for some reason I can’t.
Here’s a new link to the Encoding Time Series as Images for Visual Inspection and Classification Using Tiled Convolutional Neural Networks paper.
1 Like

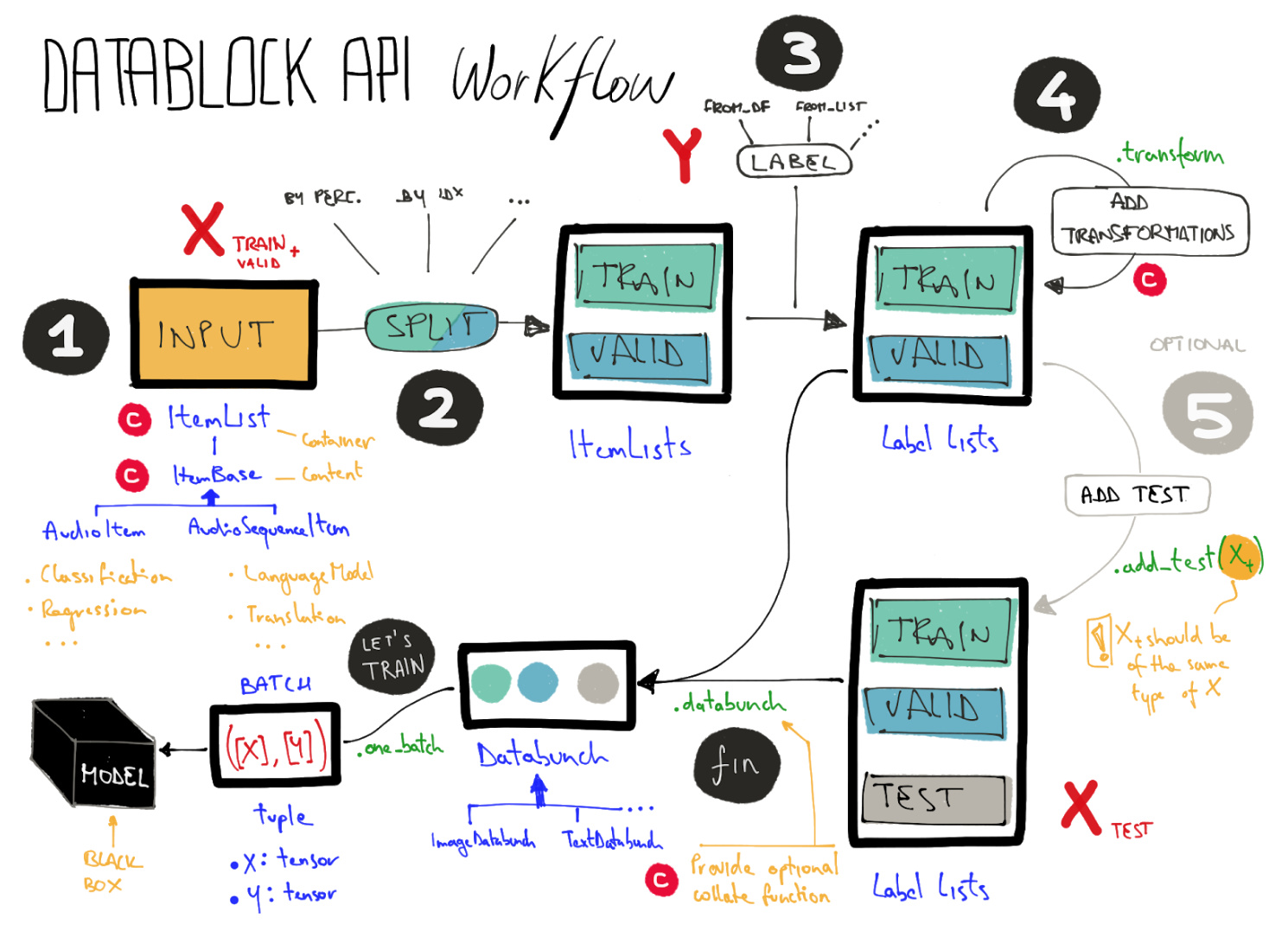
Thanks @hwasiti,
I’ll recheck this.
Butch
Your drawing is amazing… What software/hardware did you use?
2 Likes
Thnx @hwasiti !
I use paper app on an old iPad since a lot of years: it’s the fastest way I found to materialize my ideas 
I’ll post a blog in my workflow soon.
4 Likes
Predicting Hotel 1-star to 5-star from an image.
Then compare the model performance by quizzing a “hotel expert” on 25 images from the validation set. The model’s performance is slightly better than the expert’s on MSE.

https://github.com/sutt/fastai-tmp/blob/master/hotel-star-ratings.ipynb
Some interesting features the model picks up:
3-star: has folded cloth curtains
5-star: has lots of contiguous glass windows
1-star: the bedding only has white sheets; also, has a visible text sign (if exterior)
13 Likes