I noticed that the transform to spectogram wasn’t expanding the channel dimension to 3 as is done by the library for the mnist dataset. I’ve added that into my fork of the project. You were replacing the first Conv2d layer which would loose all pretrainined learning? I may be wrong about this.
After making these tweaks I checked to see how well this approach performed on Free ST American English Corpus datset (10 classes of male and female speakers) I was able to get these results:
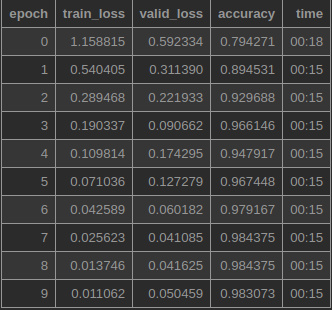
98.3% accuracy
Here is the Notebook. It is derived from your AWS_LSTM notebook