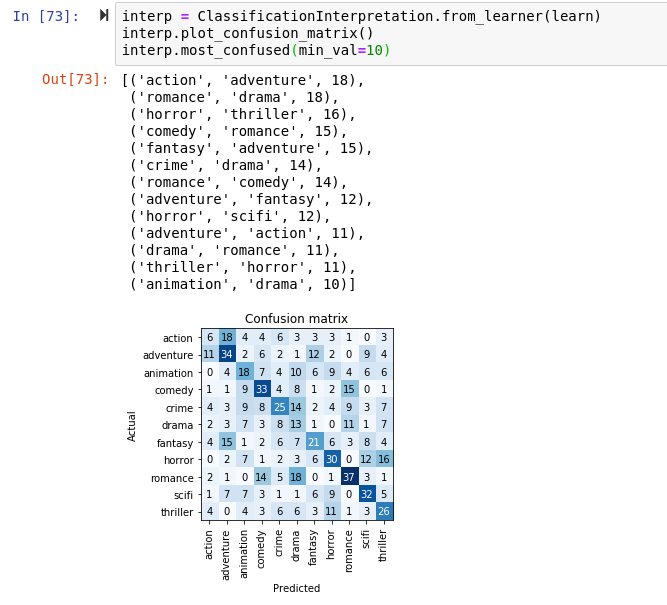
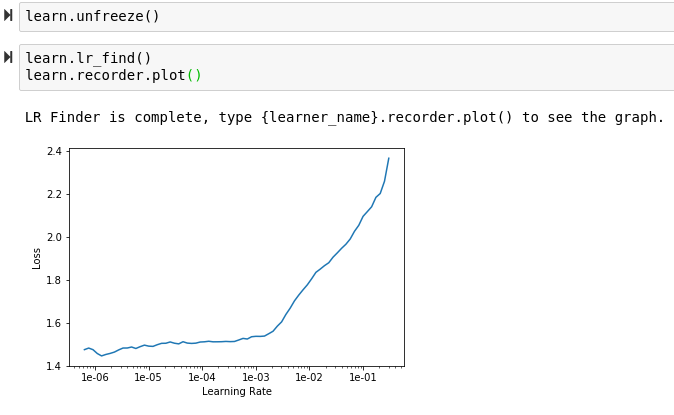
Hi All, First I thank Jeremy for this awesome course, I did some fun project based on lesson 1, its a vehicle classifier, I took images from Google and feed it to the fastai library to classify different type of vehicle (SUV, Formula1, Hypercar, pickup truck, batmobile, container truck, heavy duty truck, convertible) without change any default setting achieved 90%~ accuracy with resnet50. my next step will be adding more images to each class and add more transfort medium like a bike, bicycle, auto,bus etc., then integrate with live traffic cam to do analysis about the transport medium movement. again thank you so much for this awesome course.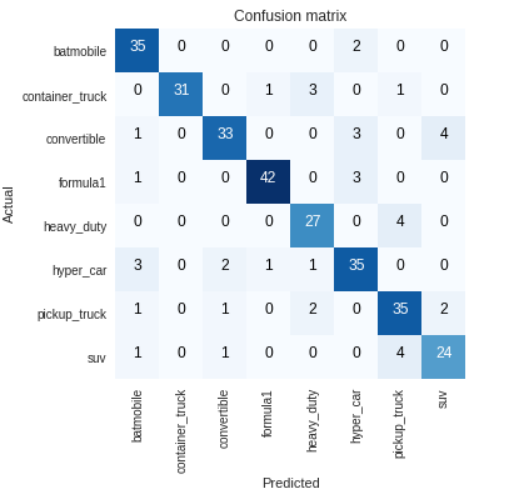 with resnet 50
with resnet 50
looking for suggestion to add more things in this fun project. Thanks