Thanks for the interesting heads up. I wondered a lot on how to solve the translation invariance for my project. I heard that VGG has less problem with this than resnets. I am working on EEG spectrum analysis. It is just like audio waves but in the lower freq. range (2-80 Hz).
I’ve got a few of insights on how things can be improved with spectrograms. EEG signals are extremely noisy and extremely faint. Basically it is usually buried in the background noise that it is difficult usually to be noticed even by the human eye. But the slight variations in color for CNN means a lot 
For instance one of the powerful methods to filter out signals is to make baseline correction. The most simplest scenario is where you decide that the 1st second of all your dataset in the frequency domain (i.e., the spectrum) is the baseline. And you will subtract the whole spectrum in each wave file, the amplitudes of the average baseline of that file. By this you will have much cleaner signal. Basically, this is like an adaptive filter in the time domain. We are removing the noise but even the noise that happens within the freq. range of the signal itself. And this is a very difficult research problem when we are not allowed to use baseline correction (like filtering mother’s ECG signal and picking up only the fetal heart ECG which is much fainter than that of the mother). Good systems will be able to give you a very clean fetal ECG without mother’s ECG.
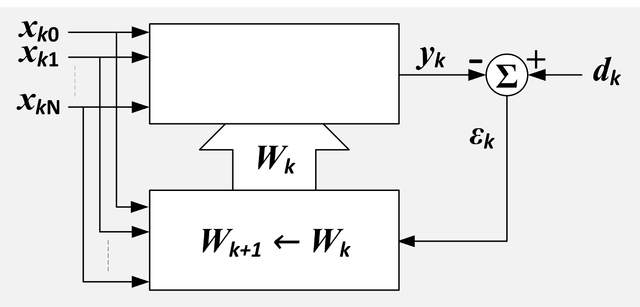
Think about the active noise cancellation headphones. They are removing (or trying its best to decrease) the amplitude of the outer speech and without affecting the headphone audio playback of the speech that is played in your headphone. Filtering out such noise, cannot be done by a simple FIR filter (like an equalizer in your Hi-Fi stereo).
@kodzaks
You can get a lot from such adaptive filtering. And do not worry about resizing the whole 10sec rectangular into square. It does not matter for the NN, unless there are certain features that happens within not more than 100ms. Increasing the resolution will help too if you are concerned that the squish is making certain sounds disappear. Squish for you will be just like playing youtube in 2x speed. (Well for you will be ~5x maybe). But it should be fine if your NN baby found himself in a world that everybody speaks in 5x speed. He will learn that language in that speed.
I love audio and signal processing… This is something that I am very excited about for 20-30 years…
Also an important tip for augmentation
I am okay with Telegram group… But I feel very sorry that our discussion and insights will be buried in closed social media… If we make our discussion only here will be much better. Even Google is indexing this forum and solutions will appear in google searches of other folks. We can help others doing so. Other fastai folks will see your chit chat and may help with an idea or other. Even Jeremy sometimes chime in, and you will lose all of that in a social media like Telegram or Slack.
I have worked with MNE EEG processing python library, and it provides several ways of baseline correction in time and in frequency domain. I haven’t check whether this is a thing in librosa, but even if it isn’t, it is easy to replicate the idea in your audio data. Or even use MNE library for your audio which is quite flexible. Just change the freq min and max into what you want… But I highly encourage to stick with audio libraries, because there are many things related to EEG that you should understand if you want to dive in this library which is completely irrelevant to you (like epochs, channel locations, event related potentials …etc.)
Notice how this baseline period between -0.5s to 0s is almost void of any signal:
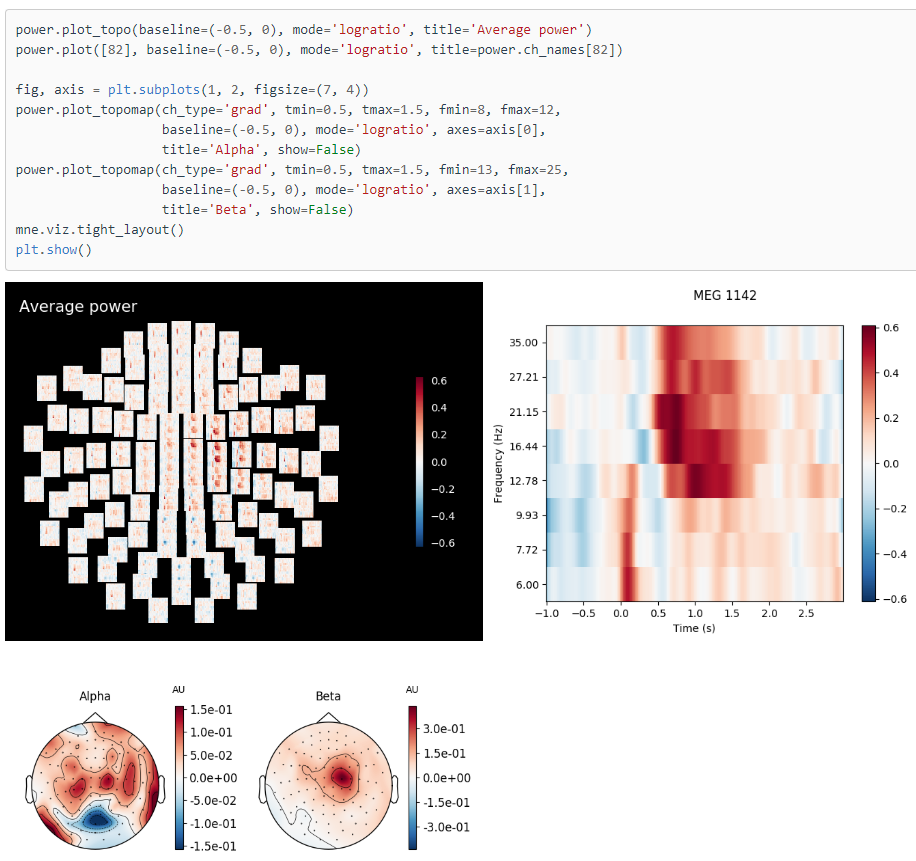
Actually this means that any continuous background noise that appears in the baseline and after that will disappear. Think like speaking where heavy machinery is continuously working in the background. Catch its frequency spectrum in 1 sec period before you speak and subtract the amplitude of each frequency of this baseline from your speech segment, and viola, your speech is without that background noise.