Great code @tomsthom (also similar work here https://github.com/DaveSmith227/deep-elon-tweet-generator). It seems this approach (language learner prediction) is not the best for text generation. Jeremy mentioned ‘beam search’ as one of the ‘tricks’ for this purpose. I haven’t seen an implementation of beam search in fastai. Anyone looked into that?
1 Like
The issue with beam search is that you would generate the most probable tweet each time. So if you have the same starting point, you will get the same tweet each time.
My approach is to generate a lot of tweets (with a different temperature and variety) and then use a second neural net to select the best one.
I am working on the second neural network (I am doing a manual filtering in the meantime, dropping around 30% of the tweets)
1 Like
Hi all  ,
,
After unpacking the material from Lecture 1 and 2, I went back to my initial project of creating, in Google Colab, a model to recognize 40 characters from The Simpsons.
After cleaning the dataset and experimenting between different learning rates, I was able to improve the accuracy to 95% from 92%. 
You can read more about this, in my blog post.

https://raimanu-ds.github.io/tutorial/can-ai-guess-which-the-simpsons-character-part-2/
2 Likes
Here’s the ref to Jeremy’s note (no further elaboration): Tricks for using language models to generate text - #2 by jeremy
I believe you get the same output for fixed input (ex. translation). In language generation you can always change seed or starting text (ex. use a random word from vocab). Beam search should be better than ‘next token prediction’.
I don’t know how to implement beam search or GANs for language generation in fastai but I am interested in exploring it when available. I tried poetry generation earlier (using language model learner prediction - predict after xxbos or xxfld), results were not that impressive.
Trimmed News - Read a summarized version of the news
Trimmed News is an app for iOS and Android. Currently it is in beta stage but you can already read news from 8 different sources. Summaries are produced using state of the art model but some of the AI parts are done using Fastai. I’m going to improve it a lot in the following weeks and in many cases Fastai will be the choice because of it’s simplicity. I try to get beta users to test it so in case this might interest you go check the website and download the app.
1 Like
Hi all,
The new baby has taken a bit of time.

But I finally got some time to play around with medical images (from lesson 1) and put together both a youtube video and medium post. Feel free to check them out and provide feedback. The notebook is on GitHub.
Update:
Render is now up. https://kvasir-demo.onrender.com/ and I am down to 3%
Update 2:
It is a multi-classification problem. I will have to solve that later.
https://www.researchgate.net/publication/316215961_KVASIR_A_Multi-Class_Image_Dataset_for_Computer_Aided_Gastrointestinal_Disease_Detection
7 Likes
Cute! We need more baby pics on this forum!!
2 Likes
I always have trouble identifying among Cheetah, Leopard, and Jaguar. They all look the same to me. So after watching lesson-2, I thought to make a WebApp which can classify between these animals. I have deployed this WebApp on Render and can be found at https://bigcats.onrender.com
While training the model
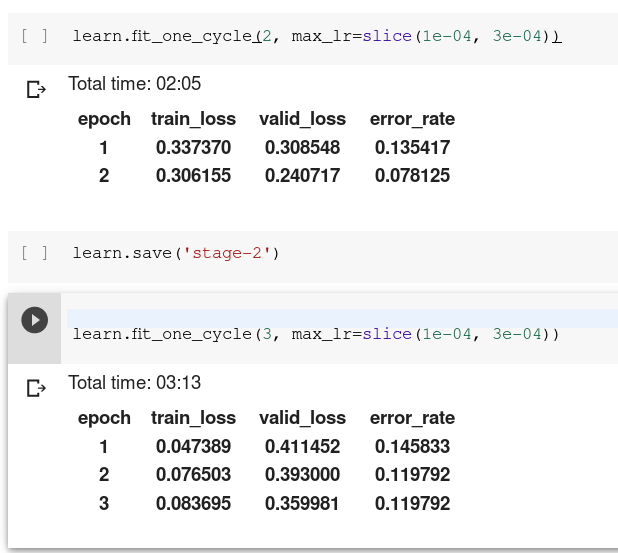
After training for many epochs, training loss decreased but my validation loss is increasing. What does it indicate?
Simple classifier between guitars and lutes:

With Resnet50, only gets one validation sample wrong out of 66 (98.5% accuracy  )
)
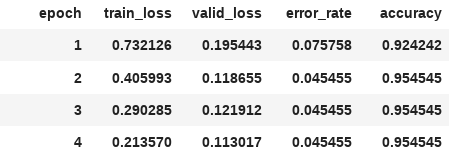

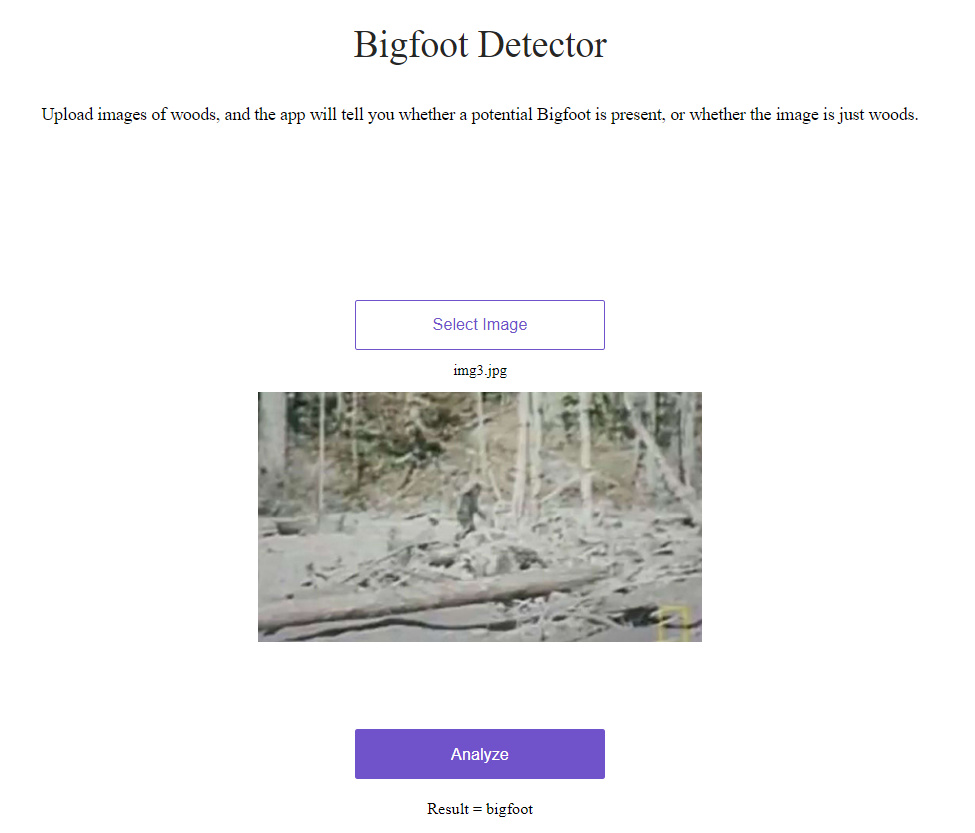
After completing Lesson 2, I created a Bigfoot Detector web app, available at https://bigfoot-detector.onrender.com/. It takes an input of a picture of woods / forest, and tells you whether a Bigfoot-like creature is present or not. Code for the model is available on github.
I used a couple of external resources for this work:
- FastClass - A python package that helps with automating the download of images from Google
- Render - A cloud provider that makes it super easy to deploy an app (even if you have limited coding experience)
I also used ImageCleaner quite heavily (when you do a Google search for Bigfoot you get some really strange results). Thanks to whoever put together the great docs for it!
1 Like
I randomly remembered Jeremy speculating that adding a residual connection in a U-Net might improve performance, do I decided to do a quick experiment. Adding the residual connection gives a slight improvement in loss, but comes at a cost of a heavier model (due to modifications required to make the residual path work, not the residual path itself).
Training Loss/Validation Loss/Accuracy for the same training procedure
Without Residual
![]()
With Residual
![]()
Masks Without Residual

Masks With Residual

8 Likes
This is cool. Did you know a neuroscientist have once given a TED talk, claiming there’s a Simpson neuron, which lighted up whenever they did some scan (maybe MRI) on a subject?
Is there a preview method to show images after data aug? Or sample code? This will be very useful as there maybe unknown defaults that don’t make sense for a particular task.
.
Hi, using the Kaggle dataset, https://www.kaggle.com/jessicali9530/celeba-dataset/home, I want to classify if the celebrity in the image is smiling or not. I have labelled images using https://platform.ai/, and have created a data set of 1000 images. Need help in building the data bunch and the changes required in the learner module. Please help!!!
Hi @jerbly, thanks for sharing you work, it was really helpful. Taking your project one step further I want to classify if the person is smiling or not? As explained above I have labelled 1000 images. Could you please guide me how it could be done and where should I start?
Thanks in advance.
Abhay
.
Today I submitted my first Kaggle competition entry! I made a CNN using a resnet34 architecture and trained it for the Histopathologic Cancer Detection competition. I managed to train the model to achieve an error rate on the validation set of 0.023520 (~97.65% accuracy). When I submitted my entry, Kaggle scored me as 88.15%. I’m not sure why there was such a large discrepancy, but I managed to learn a lot about using Jupyter, loading and saving files, manipulating data frames, and training lots of different types of CNNs. I compared results using each type of augmentation individually, as well as several types at one. I tried different models - I even made a resnet152 at one stage! I also learnt a lot about using Kaggle. So despite not getting as good a score on Kaggle as I had hoped, I still received a lot of value in experimenting with the fastai library using Kaggle. You can find a copy of my notebook here.
3 Likes
My initial thinking is you may have overfitted to the validation set. Did you do any elaborate tuning of the hyper parameters? I glanced your notebook, it doesn’t appear you have done too much tuning? I can’t tell how much work you have done just looking at it. Actually, you can find a thread where I have a bit of “encounter” with JH on the point of overfitting validation set.
Without knowing anything here, i would try cross-validation and model ensemble to see if there’s any improvement. You can google details but very briefly: you randomly shuffle and split your data into train/validation set, and then train and get a model. Next, do this again from scratch such that you have a different split, and then train again, and get another model. (there are other very closely related concept called “Bagging”). There are many strategies on this. Let say you get N number of models. You can use all of them to make predictions and average them. This averaging is most effective if your models make uncorrelated predictions for your input. i.e. they don’t all make mostly same mistakes (that defeat the whole point).
Disclaimer: I actually never participated in Kaggle, my experience mostly came from working on my own dataset and trying to ship an app. But I did hear from others ppl who win Kaggle very often do model ensembling.
Hi Kelvin,
I don’t believe I have overfitted the model. Here are the results for each epoch:
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 0.197657 | 0.150942 | 0.051721 |
| 2 | 0.190311 | 0.136989 | 0.046222 |
| 3 | 0.185618 | 0.125259 | 0.042359 |
| 4 | 0.16728 | 0.123099 | 0.04045 |
| 5 | 0.13936 | 0.143579 | 0.035337 |
| 6 | 0.116577 | 0.088347 | 0.028951 |
| 7 | 0.111443 | 0.089009 | 0.02786 |
| 8 | 0.082007 | 0.077608 | 0.024838 |
| 9 | 0.077655 | 0.076351 | 0.024043 |
| 10 | 0.082422 | 0.072606 | 0.02352 |
I did however use the same random seed for creating the validation set, so I could sensibly compare the performance of my different experiments. (as per Jeremy’s comments in the lecture). However, I understand why you would want to do this to make your model perform better (i.e. more general). I might give this a go and see if I can get it to perform better.
It’s difficult to tell from that if you have overfitted to the validation set or not. It is relative. If you have overfitted to the train set, then the accuracy gap between the train and validation set will be big, which you don’t have, so you are fine with that. But i suspect you overfitted to the validation set (not train), which you will know if the big gap is between that and the test set (which Kaggle is hiding from you and scored you 89%). Again, it is a symptom. Without knowing the detail, it may be other causes.
Hi,
Did you use the metric that Kaggle evaluates you on (area under the ROC curve) when you submitted your predictions ?
It got me the first time I submitted to Kaggle and I finished among the last ones on the Leader Board haha 
3 Likes
Oooohhh. I was using error rate, not area under ROC curve. 
I’ll see how I can use that metric and try again. Thank you!