I would suggest just use the last fully connected layer as the feature and don’t process it using PCA.
I see. So you really did get negative counts quite easily just like that. I think you can use your work as a testing ground or study case, for the efficacy of imposing constraints on your predicted outputs to fall on a required domain, to improve overall performance. There seemed to be some calls that this is true. But i don’t know.
In your case, you want to avoid negative. A log(count) or log(count + 1) can achieve this since you will need to do exp(your prediction) to get back the real count, and exp(x) is always > 0.
Also, it may be more revealing if you make your validation set a bit tougher, e.g.
Train: Use synthetic image with 1-10 circles
Validation: Use synthetic image with 1-15 circles.
Now, if your network is not generalizable, you will catch it early. Your validation error will never approach to where you like it. But if you are doing very well even with that, then thats onto something. Then you have more hope it can generalize outside of these ranges in your final test set.
In general, it actually maybe good to sneak in some “tough” sample to the validation set, maybe even tougher than the test set (speculate it if you can’t see it), to challenge your model.
1 Like
Nice work, rastringer. This is one of the ideas I considered taking up, glad to see someone did it. Out of curiosity, do you train either one? I’ve been training bjj for about 15 years now, and have dabbled in judo.
It would be interesting to see how a classifier would do with neutral poses, since there are subtle differences in the way the gi is worn. The classic judo gi is slightly looser fitting and longer than in bjj. Bjj practitioners are also a more liberal with their patches than judo.
thanks for the suggestion @maral the idea behind using PCA is to speedup the similarity calculation, so instead of a feature vector of 512 per image I will end up with smaller vector (says dozen). Also PCA should be good at capturing most of the information in this new space. I think the problem is with the dataset, may be if I try with another one I could end up with more interesting paths.
Yes, you are welcome to do so @anurag. Testing locally saved me a lot of time, helped me better understand your files and allowed me to customize html, css, js and server.py files.
Hello,
I have created a basic ship identifier by training on the images downloaded using googleimagesdownload. I made this after completing the first lesson. The accuracy is very poor, due to lack of data (I think) I would really like some suggestions on it. Here is the gist of it.
After lesson 1 I built a classifier to try to predict the difference between inline/roller hockey, ice hockey, and lacrosse. I figured it would do well with lacrosse, but I was honestly surprised at how well it did predicting ice hockey vs. roller hockey. The final error rate was .022.
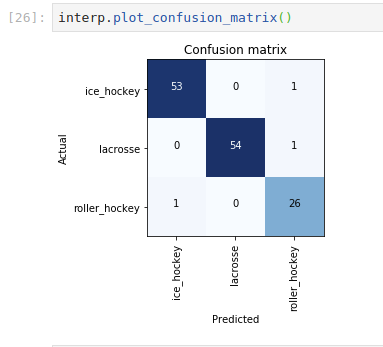
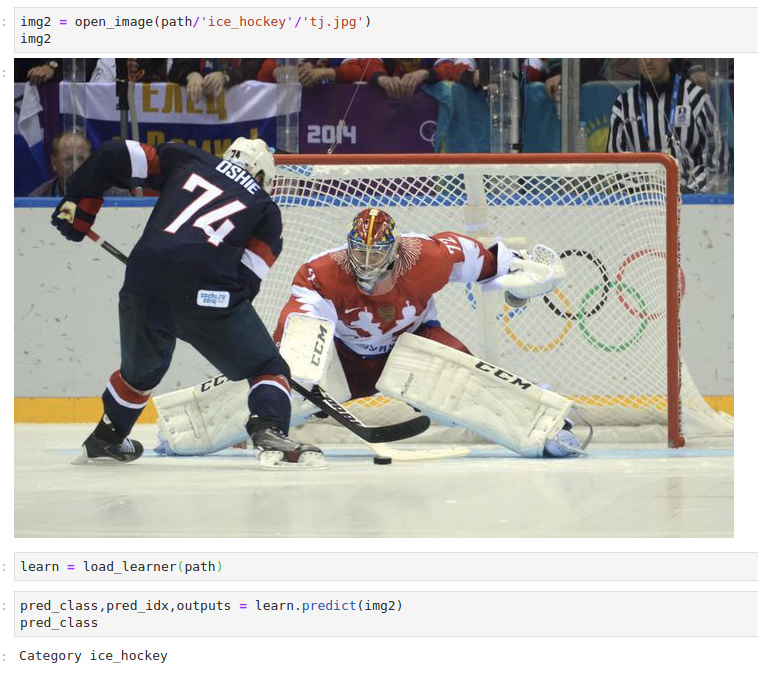
Here are two final pictures I gave it that it had not seen before:

I used a pre-trained GAN to turn images into cartoons. Here are a couple before and after shots. I am about to turn it into a twitter bot although not sure how long it will last 


















28 Likes
more and more inspired by fast.ai, just published part 1 of a 3 part article on medium, big thanks to fast.ai for inspiring so many of us, I’ve also created some 3D animations of loss landscapes to illustrate the article and I’m planning a lot more on the 3D visualization area (pd: the loss values are on purpose scaled/exaggerated in the animation to help with visual contrast), here the article:
and some of the 3D animations I created for the article:
Im enjoying a lot part 1 of the 2019 DL course, Fast.ai totally rocks! 
29 Likes
Nice!
What approach / function did you use to generate training data? (assuming you used the same approach as in lesson 7)
Hi everyone,
For this week, I have shared an interview of another amazing fastai fellow: @alexandrecc
Dr. Alexandre has shared many great insights about the intersection of DL and medical tech, and his work.
Link to interview
Regards,
Sanyam.
6 Likes
I did not train a model. I used a pre-trained GAN. Specifically, I used CartoonGAN. Check this repo
3 Likes
Hi guys 
I was part of the original FastAI (Keras) course back in 2017 but wanted to do it again with PyTorch and the FastAI framework.
Just finished Lesson 1 and I wrote a little classifier for mosquito species identification.

I’m sharing my blogpost here.
Hope you find it interesting.
2 Likes
Hello sgugger
Can you elaborate on this? What is the proper way or example of how to get intermidiate features using fastai_v1. When do use remove()?
Regards
Great point ShawnE! Adding a more varied dataset including neutral poses where stance and gi feature more prominently could be a great way to go.
That’s great you’ve trained for so long, excellent. I’ve dabbled here and there in BJJ but location moves meant I often had to leave a club just as I felt I was getting somewhere. I hope to get back to it soon…
Thank you for the great feedback!
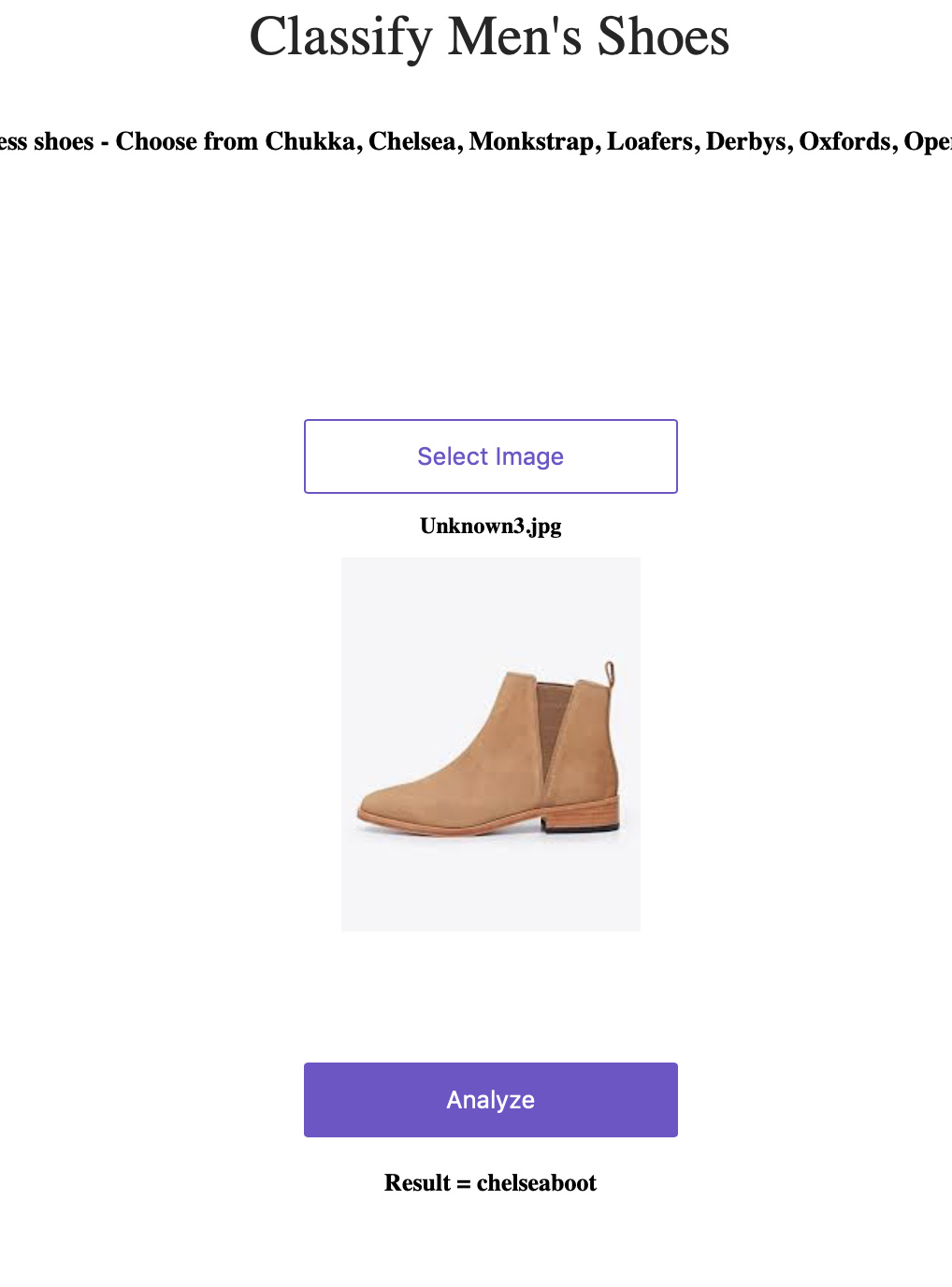
Shoe classifier is now live!
Based on the image classification exercise - created a simple men’s shoes classifier that lets one classify between a few types of men’s dress shoes. I put it on Github, deployed it on Render and it’s now live!
I can’t believe how easy it all was just following the instructions in the course resources!
And am going to live blog the entire course work @
Even made a pull request to one of the course’s docs.
I did have one last thought on your work on “counting” application (btw: I think it is pretty unique and creative). if you recast it as a regression task and after hard work, it is still overestimating on counts thats larger than the range you trained it on, it may mean something. 'Cos I wonder to a small extent, this is how animals get their “number” sense. It must be a primitive image recognition thingy? If you have connection with psychologist or biologists, try to see or read on experiments related. Maybe animals also tend to overestimate counts. I frankly don’t know how you could even “verify” this. But if this is true, then e.g. a bird may think there’s more food particles if you give it all at once, vs. doing it twice halving the size each time (if it can remember it).
Those who have already watched the part 1: I wrote this medium post to explain how I keep up with the development of AI. I recommend to read it because there is techniques that help to get the most relevant information easily. Don’t just wait part 2 but spend time learning yourself.
1 Like
I have been working on a classifier to identify dinosaur images. The challenge I set out to tackle is to build something that will be able to identify images from a variety of sources, whether they be paleontologist drawings or pictures of kids toys. I’d like to take this all the way to an app that I and parents like myself can use whenever our kids ask us “what’s that dinosaur?”
I was impressed that I was able to achieve 80% accuracy over 10 categories, while still having some errors in my data labels (revealed when looking at the top losses). I was also able to get 87% out of a resnet50 model, but that accuracy varied widely in between notebook runs. If anyone has time to look at the notebook maybe they can help me figure out why.
The notebook is posted on github here.

1 Like
I have worked on a deep learning twitter bot generating funny “inspirational” tweets.
It’s live and you can see it here: https://twitter.com/DeepGuruAI.
It uses ULMFiT and techniques from the course.
The code is open source (https://github.com/tchambon/DeepGuru), and the github page describes the different steps (training, generation and bot).
4 Likes