Can you tell the difference from the photos? (If it’s a task that humans can’t do from your data, then generally a computer won’t be able to either, so you want some kind of human baseline to compare to.)
1 Like
That “downplaying” apology applies to me, you are doing the hard work here as well and I am just a bystander.
The problem is not so simple. There’s a 3 way split as far as I know. Train, validation and test set.
Train - seen by model and used to adjust weight
Validation - not seen by model and used to continuous evaluate progress, but lt is seen by you, the human decision maker.
Test - not seen by model, not used during training in any manner, not even printing out its loss or accuracy. It is used only at the end running only once. Ideally, this data is hidden under a rock until your finish all your work.
This is really the most honest way with probably no chance of accidental overfitting. And of course, this is how Kaggle work as well. You don’t see their test set while u work, and only get a number reported back to you.
This point may be explained further in fastai, I am not sure. But if not, you can easily google it up.
Having said all this, I get JH point. There’s a good chance you achieved equal or higher accuracy than the paper, cos u aren’t tuning the hyperparam like mad, only very mildly by LR or epoch num if so. But I would be careful if the claim is compared to a research paper, and then mentioning it on Twitter, then the result will have to be defended more. I perfectly understand we are all just learning, I just shared this cos I ran into bad things before by leaving out work.
The post you’ve cited is very interesting: I definitely want to take a closer look at it! I agree with the author that having “unkonwn” people in the validation set let you better measure how the model generalizes.
My notebook is an “initial trial” / “starter kit” for a generic object classification competition in kaggle with fast.ai, not an attempt to win it.
Take a look at your data augmentation:
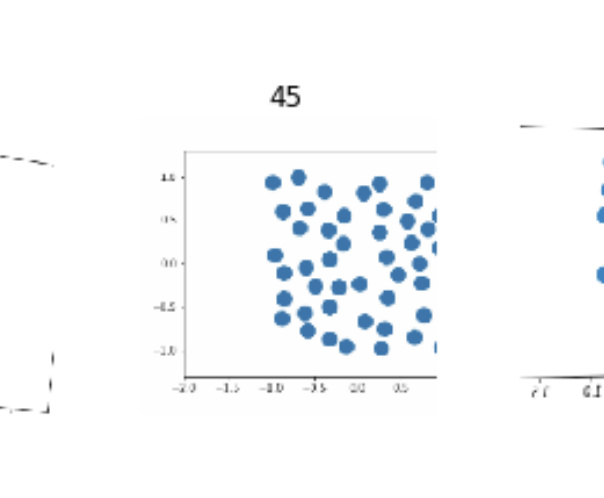
In this sample you’re probably using a wrong label because the visible dots are less than 45.
I naively knew sourcing the data this is hard, but after hearing your experience, it looks even harder. Making an app to serve customers and then collect the data is probably the way, assuming you have no deep connection in that industry. I had thought about a cannabis identifying app, and u bet it’s not so easy to collect large diverse dataset, before legal trouble, even if you live in Canada.  I googled sativa and some well know brand, and I already got discouraged. This is another area you probably need some connections with the right biz ppl. For counterfeit bags, it will help if you have a personal collection, and just take hell lot of photos.
I googled sativa and some well know brand, and I already got discouraged. This is another area you probably need some connections with the right biz ppl. For counterfeit bags, it will help if you have a personal collection, and just take hell lot of photos.
I can’t tell the difference between a good knock off and an original. However, it seems that there are people who can. Often a fashion blogger/account will post a “can you tell the real from the fake” like this one the majority of people who comment are able to spot the fake, so I assume it has to be possible. Sending one of these bloggers the same images and seeing if they can beat the classifier would be an interesting exercise.
If you have time, take a quick look at course 3 of Andrew Ng Deep Learning specialization on coursera. He had a very in-depth discussion on human baseline, Bayes error, and super human performance. He used radiologists as a discussion case,
Another thing is. What’s the prior chance that given any bag you see, it is a fake. You may run into same issue for cancer diagnosis. So you ultimately may want F1, precision, and recall, in addition to accuracy. This may also vary from region to region. If you visit China, it may be much higher than in the US/Canada.
I just posted the notebook with 95% accuracy of the CamVid-Tiramisu dataset to my github.
I also included a notebook showing how I converted the labels of the CamVid dataset to match the labels the Tiramisu paper used, and some other training I did.
This is the first personal project I’ve shared. Any feedback about my project and/or github is welcome 
1 Like
My post on how to create a Web App on Render from a fastai v1 model (thanks to @anurag for this possibility) with a focus on local testing before online deployment (for the occasion, I’ve reloaded an ImageNet classifier).
9 Likes
yes that’s what i meant
Hi - first post here. In the spirit of sharing “also the small things”, I’m just putting my web scraper code for Wikipedia here: https://github.com/NicolasNeubauer/fastai-stuff/blob/master/scrape_wikipedia.ipynb
If you find a table containing image references and a column you want to use as a label, you can just use this code, adapt the extraction code, and it’ll write this into a “from_folder”-friendly format.
edit: wrote this before watching the 2nd video; obviously could use more fastai-internal tools.
1 Like
Nice work @pierreguillou. I think I’ll borrow your idea of documenting and testing locally before deploying on Render and update the deployment guide.
1 Like
Yes, I framed it as a classification problem as opposed to a regression or object detection problem. I wanted to see if it was possible to distinguish between different classes of images when those images were composed of things with identical features (eg. all circles).
I played around with repeating this as a regression problem and noticed that it didn’t seem to generalize beyond the ranges on which is was trained. For example, instead of limiting the number of elements from 45-50, I tried using a range of 1-50 and optimizing over the mean squared error.
While this worked very well for images within the range of 1-50, it didn’t generalize very well outside of it. The network would estimate values much, much higher for counts it had never seen before.
Both of these approaches are probably not ideal for “counting” and something like object detection would probably make more sense, but I wanted to play around with edge cases of convolutional neural networks in order to try to learn new things about them.
1 Like
That’s very interesting, I assumed you have also regularized it with weight decay or dropout. If it always overestimate if data is higher than the upper range, you can experiment with predicting log(count) instead of count, or other transform, and see if it will do better. The hunch also comes from the fact that u r predicting a float with regression, and count is an integer. This is making it hard for your CNN.
1 Like
In addition, I didn’t check your notebook in full. Just curious if you can generate an input such that it predicts a negative count. I mention this cos you may want to build in a design, such that nonsense like this won’t happen. And doing log or exp or whatever may make that happen.
Yes those are all good suggestions. With the naive approach I used you can definitely generate nonsense. When I trained for only a portion of the range (10-50) providing low counts like 1 or 2 resulted in negative numbers.
Thanks Jeremy !
Thanks Jeremy. I’ve watched Lesson 2 now, and I think I now have a better understanding of what’s going on. I played around with the model some more, until I got the training loss to be lower than the validation loss, and was able to improve the accuracy significantly (from 12.5% error rate to 5.6%)
Here is a classifier I could build and deploy even before I finished Lessons 1 and 2. This demonstrates the effectiveness of Jeremy’s and Rachel’s methods and the how practical they are.
I am a professional photographer and I take photos of the interior of houses being listed for sale. The number of photos can range from 40 to 100 depending on the size of the house. After taking the photos I need to label them before delivery to my customers.
A sample is below
Photos: https://silverscreen.smugmug.com/Real-Estate/17050-Saint-Anne-Ln/
Virtual tour which needs labelling https://silver-screen-photography.seehouseat.com/1215335?a=1
Labeling photos is a tedious task. So I decided to build a classifier to do it.
I used downloaded images from Google and the classifier can classify images into 7 classes - bedrooms, bathrooms, front views, backyards, living rooms, kitchen and dining rooms.
The notebook is at https://github.com/suresh-subramaniam/fastai
I have not implemented the code to label the photo with the predicted category or created an application out of it. I plan to do it in the future.
I learnt the following
- It is easier to use a Chrome plugin to download photos from Google than the script suggested by Jeremy.
- The best accuracy I could get is around 83%. I had not cleaned the photos before training. I am sure that cleaning up the junk photos will improve the accuracy.
- Sometimes photos of rooms do not have furniture in them. It is harder or impossible to distinguish between a living room and a bedroom, if they both don’t have furniture. This uncertainty is reflected in the low accuracy.
I hope this was useful.
2 Likes