This is my first post, so please let me know if I did anything wrong.
Here’s a quick summary of what I did:
After watching lesson 1, I put together a model to tell apart pictures of Australian Prime Ministers (they change very quickly these days, so it seemed like it could be useful).
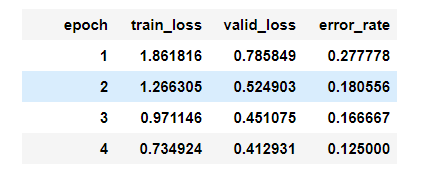
My data set included 50-70 images each of the last six PMs. I used resnet34, and the model got to an error rate of 12.5% after 4 epochs. My code is available on github.
It was really cool to be able to do this after just one lesson! (especially since I have limited coding experience - I’m currently a management consultant so most of my technical skills are specific to Powerpoint)
Here’s some detailed information of what I did: Getting the data:
To download the images, I used a firefox add-on from a forum post.
I downloaded ~60-80 pictures of each prime minister from Google, then went through them and manually deleted any that looked problematic (e.g. pictures of the wrong person, pictures with text in them)
Uploading the data into Crestle:
I had a bit of trouble with this, since it wasn’t obvious to me how to get a large number of files onto my Crestle server, but I was able to find some help in a forum post.
I ended up installing the unzip module for python, uploading a zip file onto my crestle server, and then writing some code to unzip it
Building, running, and fine-tuning the model:
I used resnet34 for the model (I also tried resnet50, but was running into memory issues even with a small batch size)
After four epochs, the model got to a 12.5% error rate
I was pretty impressed with the error rate! Especially since a lot of the prime ministers look very similar (many of them are men with glasses and short white/grey hair). The combination the model had the most issues with was Kevin Rudd and Scott Morrison
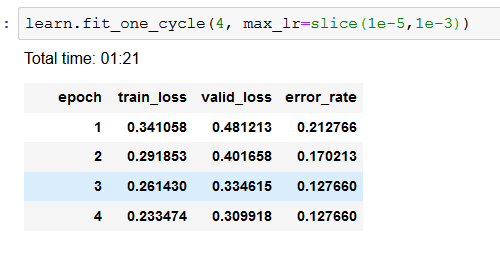
I also tried some unfreezing, but the results seemed pretty bad (error rate of >80%). I’m guessing that I’ll learn more about how to do this in the coming lessons
I had tried training on the same dataset a month ago using transfer learning on a resnet-50 model on Keras. At that time the maximum accuracy I could get was about 80% after training for 10 epochs. This clearly shows the power of setting the parameters correctly. If using the default parameters, this result is achievable, I can’t wait to learn more and retry by tweaking the parameters a bit.
Resources: @raimanu-ds wrote this amazing blog on how to train on colab using fast.ai and datasets from kaggle.
If you get stuck with importing kaggle datasets onto colab, get help here.
Using the image similarity from an earlier post in this thread, I tried to implement google’s X degrees of separation which is simply about finding a shortest path between two images. I was not very successful with the results but it’s overall OK like in this path ( path is from left to right with the image to the left is source and the image to the right is the target).
having some fun with ‘leela-zero’ running on gcp and playing against ‘leela-eleven’ …
both go-engines are available here: https://www.sjeng.org/leela.html
front end is Sabaki gui :
Nice work !
A couple of questions for my own learning:
a) How did you select the image size ?
b) Why were the images not normalized ? (.normalize(imagenet_stats))
But one gotcha when comparing to prior art : the NABirds dataset has the train and test sets explicitly marked. But from the linked jupyter notebook, doesn’t look like this split is being honored. For fair comparison, would be good to train/validate on the training samples and then finally compare the accuracy using the test set.
I also pointed this out, actually on Twitter, probably should do this on this forum instead. JH somehow insisted this is ok. He said if this is not done with too much tuning. But honestly, I aint convinced. You can overfit to validation set simply by adjusting LR, as well as # of epochs you trained and who knows what else, all probably unintentionally. I backed down a bit but maybe i shouldnt. I think I have to call it out, and thanks for pointing this out as well.
To be fair to the researchers of that paper, @JCastle probably want to get a proper test set accuracy. I don’t mean to be downplaying anybody’s hard work here.
This is interesting. A friend of mine told me a startup doing exactly this, and it is getting global biz. This is a legit practical problem. As forgers are very good in faking product, your 37% may even beat lot of human, including me. So 99% probably not a benchmark to beat for now. I suspect you have to get more data, and try to get multiple shots on the same bag from different angle, and emphasizing diff parts, and average the predictions.
I am working on a project that involved counting, but nothing to do with fastai lesson. I am a bit confused since this looks to be an image recognition problem, and so wonder if you are labelling your images as “49”, “50”, “51”? But this will limit the range of object you can count. For my case, I have to use object detection model (which i think will be part 2 fastai)? You may have seen some videos such as yolo, ssd, etc. that draw bounding boxes around objects in some self-driving tech promo? a side product obviously you can count the objects. Potentially, you are not limited to the range of number of things you can count, up to a certain point.
I’d also be interested in how many images. I have a classifier that works across 16 sports, and I also had an ‘other’ option for non sports images. I had between 300 and 700 images per sport, depending on availability, and found that image size made a difference and ended up using 448x448 to get the detail needed to differentiate. Still I get around 95% accuracy. I’d expect two class baseball v football to easily get close to 100%. https://sportsidentifier.azurewebsites.net/ Quidditch was the last sport I added to my list.
I originally ran 4 epochs with either default image size or image size of 224 and of course started thinking of simple ways to improve upon the results. From (data.show_batch), I saw that a number of the images were cropped to a level that was hiding large important sections of the birds, so I increased the size to 384 and results improved 4-5%. Need to continue to research to make improvements.
In the initial stages, I was looking to just get an output and keep things simple, so did not try (.normalize(imagenet_stats)) or additional functionality that FastAI offers. Will continue to explore.
Agree 100% with your statement regarding the researchers train_test_sets. Again, initial hope for me was to just get reasonable predictions and was surprised to how close (+/- 1-2%) to state-of-the-art my initial attempt performed. Making this comparison is my next project.
@kechan - Thank you for your comments. I in no way wish to diminish the real work that the researchers performed.
My understanding is that FastAI’s accuracy rate is calculated on test holdout set that the trainer has never seen. So if the researchers performed their train_test splits properly and FastAI’s random test split is sound, then I believe the results should be fairly solid. However, you are absolutely correct that using the same test set to ensure that one of us is not working with an outlier test set is in order. This my next project.
Happy to answer any questions about my approach, but it is basically all in the notebook. I ran with resnet34 2-3 times, ran 2-3 times with different image sizes, and finally increased the number of epochs as hold out accuracy was still decreasing.
It wasn’t very sophisticated. First I found this LV fan page on instagram (just a warning, the ostentatiousness on display is disturbing). Whoever runs the account takes real vs fake seriously, so they’re only reposting legit products. Then I looked for replica hashtags. Often they were stores posting bags/wallets, when it was obvious they were posting their own photos (walls, countertops, backgrounds give this away) I used the photos for the fake category. I took screen shots, which is why the dataset is so small… it’s time consuming.
The biggest issue is being sure that a replica/fake is in fact a fake and not a real bag image to give the impression of a higher quality fake. This is the main reason I didn’t automate the process, I felt like I needed to be sure what was labeled fake was in fact fake. Here’s a dropbox link to the images I used if you’re interested.
FWIW, if I were to take this project seriously I wouldn’t use instagram as a source. It was either in V2 or V3 of the class where Jermey said that going through the process sorta turns you into a domain expert even if you had zero prior knowledge of the subject (he used dog/cat breeds as an example), that’s 100% true. Now that I know a lot about the counterfeit market I realize that instagram isn’t where the majority of buying/selling takes place.
I agree more data is likely the answer. Sourcing the counterfeit bag images is probably the hardest part of the problem. Lot’s of sellers of fake products use legit images. One idea I had to ensure that the images were counterfeit products was to find pictures used as evidence in cases brought against counterfeiters (in theory these should be available). Maybe someone with a legal background would have more success than me. I found it to be a dead end. I think one way of getting some quality images would be to put together an app that predicts if a bag is fake or not using a simple model like the one I came up with and have users upload pictures of their bags and see the quality of the fake. These new images can be used to further train the model.
Thanks for replying, I was really interested in your data collection process because you obviously have to be an expert to be able to tell apart the real thing and fakes, as counterfeiters have become pretty good.
And to the best of my knowledge, I don’t think the luxury industry has found a way yet to protect customers and their brands against counterfeits though they’re exploring things such as blockchain.
It’s definitely a cool project and if you were to continue, I would be happy to brainstorm with you about this.
That’s not quite what you said on twitter - what @sandhya says here is correct however. But more importantly, what @sandhya has done here is much more respectful of the work that @JCastle did.