Hi everyone,
I’ve noticed that in Lesson 3, Image regression task (head coordinates) a slightly more complex procedure is required to convert 3D head position to screen coordinates. More specifically, other than intrinsic camera matrix multiplication (which is done in the original solution), there are also rotation and translation matrices which are used to define RGB-camera position relative to the depth-camera on Kinect (ground truth head positions are defined in depth-camera coordinates)
Here’s the relevant part of notebook which uses matrix multiplication for the 3D->2D coordinates conversion:
def convert_biwi(coords, cal):
pt = cal @ np.append(coords, 1)
return tensor([pt[1]/pt[2], pt[0]/pt[2]])
def get_ctr(f):
ctr = np.genfromtxt(img2txt_name(f), skip_header=3)
fcal = img2cal_name(f)
cal_i = np.genfromtxt(fcal, skip_footer=6)
cal_p = np.eye(3, 4)
cal_rot = np.genfromtxt(fcal, skip_header=5, skip_footer=2)
cal_rot = np.vstack([np.c_[cal_rot, np.array([0, 0, 0])], [0, 0, 0, 1]])
cal_t_vec = np.genfromtxt(fcal, skip_header=9, skip_footer=1)
cal_t = np.identity(4)
cal_t[0, 3] = cal_t_vec[0]
cal_t[1, 3] = cal_t_vec[1]
cal_t[2, 3] = cal_t_vec[2]
cal = cal_i @ cal_p @ cal_rot @ cal_t
return convert_biwi(ctr, cal)
(what I didn’t get is why I had to swap x and y coordinates in the tensor([pt[1]/pt[2], pt[0]/pt[2]]) expression. Any advice?)
With that change, the validation error is more than 2x times lower than before: 0.000971
And after training it a bit more with half the original learning rate, the validation error decreased 10x times more: 0.000100!
The results seem to be insanely accurate:
Wow, that feels like magic.

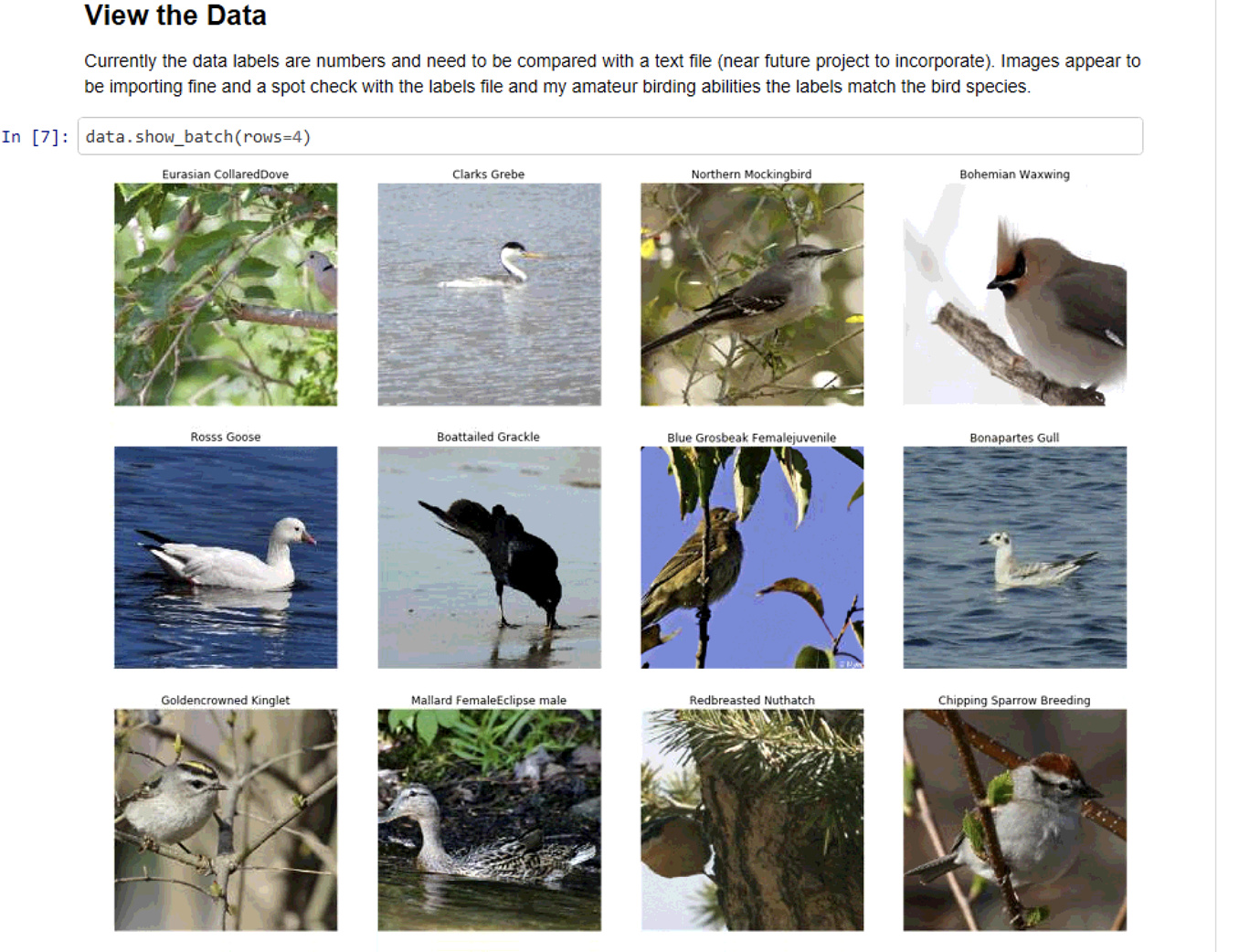
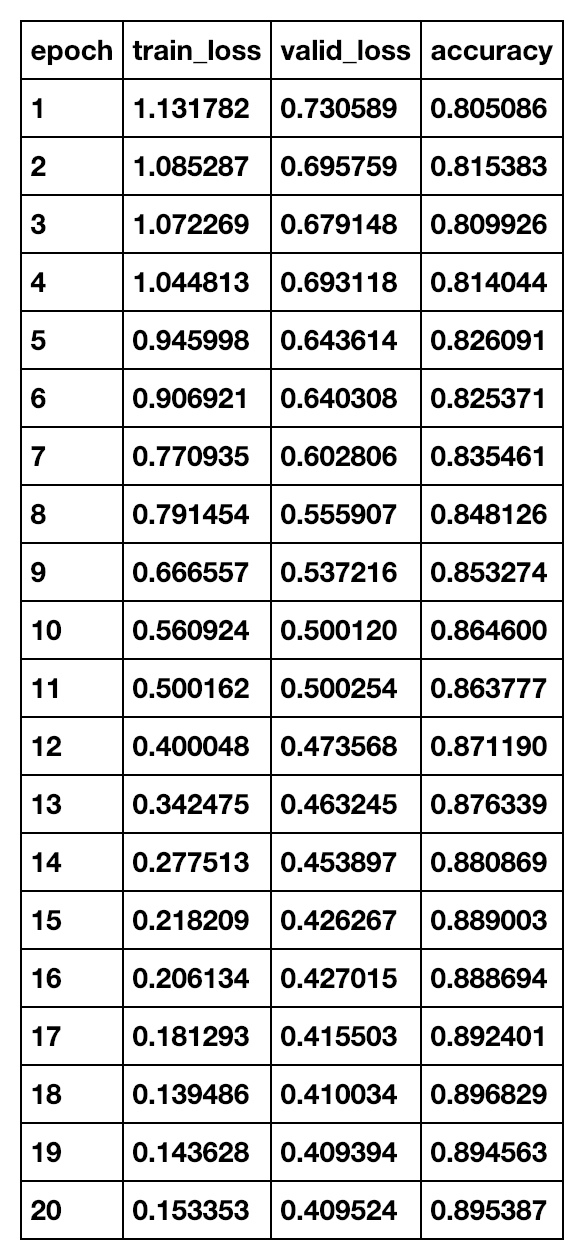
 ), trained a ResNet50 network and achieved 90% accuracy.
), trained a ResNet50 network and achieved 90% accuracy. Thanks to Grad-CAM and
Thanks to Grad-CAM and