I find this experiment very interesting by design and for learning more so i had a look at your notebook.
I believe that you can improve on your score by working more with get_transforms. You are using the default setting and could probably improve the results by analysing an improve the effect of each tranform. Cropping doesn’t look meaning full in this cases
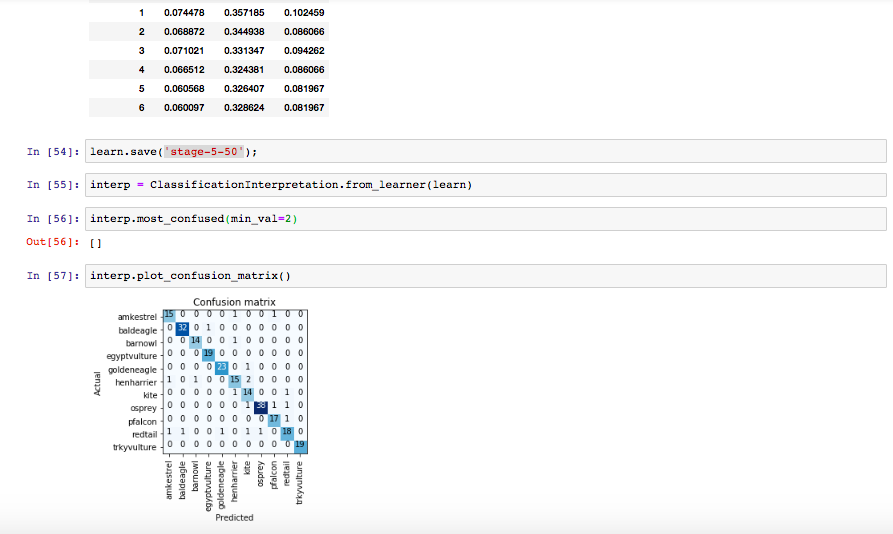
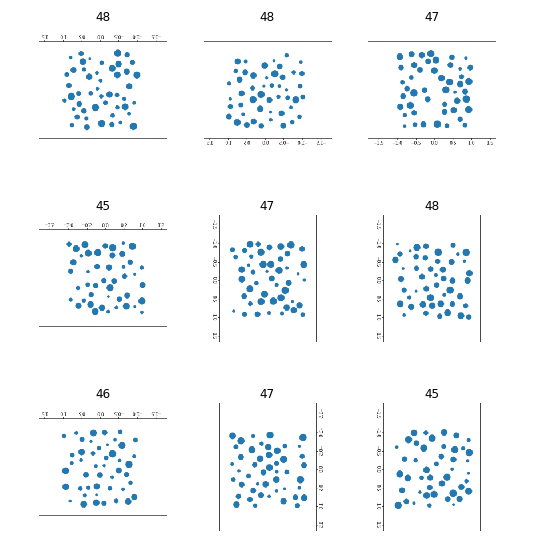
Another question is that looking at the data it is not clear to me what your are trying to learn the network - there is only on image of each count. should it count or make pattern matching ?
If you wanted the network to be able to distinguish between 49 and 50 then it would help a lot if you create thousands og different 49 and 50 dot images and tried out a regression objective also.
A next interesting level would be to do the same with dots of difference sizes.
I would love to see you take this further.



 ,
,
