I was using the lesson3-head-pose notebook on the BIWI data set as a reference; I don’t think I’ve seen the notebook you’re referencing. Is from the old Part 2 course? I didn’t see anything in the docs either about a collate function for Image Points so I just assumed it hadn’t been done before in any of the lessons.
I worked through lesson one using my own dataset of images captured at my birdfeeder. I previously created a binary classifier using a commercial product Classificationbox and achieved 92% accuracy, but by following the lesson plan and using resnet34 I am getting almost 98% accuracy, so a great result  Notebook on kyso -> https://kyso.io/robmarkcole/birds-vs-not-birds-image-classification-using-fastai
Notebook on kyso -> https://kyso.io/robmarkcole/birds-vs-not-birds-image-classification-using-fastai
3 Likes
Hey, to create a new image classifier after lesson 1, do I need to create a completely new notebook? Also, I am using colab, so can someone tell me how to upload the new dataset. Basically, I would really appreciate a complete step by step guide on how to create a classifier from scratch.
1 Like
My weekend’s excitement on a kaggle dataset I can no longer find: I used the Lesson 1 code to categorize pieces of art to the following categories: painting, engraving, iconography, sculpture, and drawings.
Using the ImageDataBunch.from_folder took forever because I didn’t know how to use the path parameter, and their were corrupt images.
PIL has a nifty verify() function that helped.
Finally found some time to write something about entity embeddings. The course really sparked my interest in diving deeper into the subject. Hope the post could be off some use to everyone.
“Understanding Entity Embeddings and It’s Application” by Hafidz Zulkifli https://link.medium.com/sIBqXgqAPT
1 Like
Hi all,
Jeremy had mentioned about FP16 training during one of the lectures. For this week, I chose to dig deeper into that.
Thanks to @Ekami I was able to do a 2080Ti Vs 1080Ti comparision for training times.
I think this deserves a mention that even though FP 16 is supported by many libraries now, none make it as easy as wrapping your code with a .to_fp16() like fastai does.
Here is a gentle introduction to Mixed Precision Training & a few benchmark comparision:
Regards,
Sanyam
8 Likes
Having similar issue. I’m trying to use exponential mae similarly to what Jeremy did in Rossman, but also getting score around 0.33. Before using fastai v1 I made the same notebook but for fastai v0.7 and got the error 10x smaller. The way you create custom metrics has changed in v1, it’s not as simple as it used to be and it’s quite confusing for me.
I’ve built a binary image classifier, using resnet34 and resnet50 on a dataset of blood cells images to distinguish whether a cell is infected with malaria or not. Here is
- Malaria Cells Image Classification with Residual Neural Network (an article on Medium) and
- the code on GitHub.
Thanks for any constructive critique and suggestions.
3 Likes
I tried another fine-grain classification problem after watching lesson 1.
Dataset - 10 Monkey species
Here’s the blog post explaining my approch.
Feedback and Suggestions are appreciated.
1 Like
I created a Plants and Fruits Image classifier. Here is an article about the same:
3 Likes
I just finished the first two lectures and wanted to try using convolutional networks on my own datasets. Full writeup on my blog.
In particular I wanted to find out what convolutional neural networks are good at and what they struggle with. I created three datasets of increasing difficulty:
- Impressionist Paintings vs. Modernist paintings (Easy; Very different features in each class)
- Cats vs. Kittens (Medium; Cats and Kittens share many features)
- Counting identical objects (Hard; All objects have identical features)
I found the third experiment proved interesting, so I’ll share a little bit about it here.
Counting Objects
Full notebook on GitHub.
For my last task I wanted to see whether or not we could train a ResNet to “count” identical objects. So far we have seen that these networks excel at distinguishing between different objects, but can these networks also identify multiple occurrences of something?
Counting 1-5 Objects
I started by generating 2,500 images using matplotlib with 1 to 5 objects in each and labelling them accordingly.
path = 'data/counting'
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
data.show_batch(rows=3, figsize=(7,8))
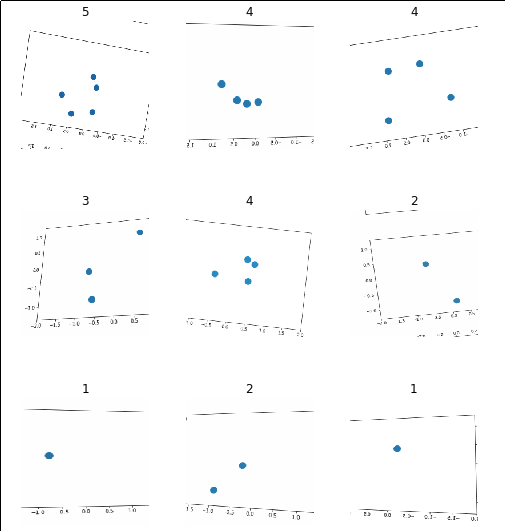
After running a vanilla learner for a few cycles I got an accuracy of 87%! After fine-tuning with a better learning rate I was seeing accuracies of 99%!
What’s going on here? I specifically chose this class to try and trigger a failure case for convolutional networks.
What I would guess is happening here is that there are certain visual patterns that can only occur for a given number of circles (for example, one circle can never create a line) and that our network uses these features to uniquely identify each class. I’m not sure how to prove this but I have an idea of how we might break it. Maybe we can put so many circles on the screen that the unique patterns will become very hard to find. For example, instead of trying 1-5 circles, let’s try counting images that have 45-50 circles.
Counting 45-50 objects
After regenerating a new dataset, we can take a look at it:
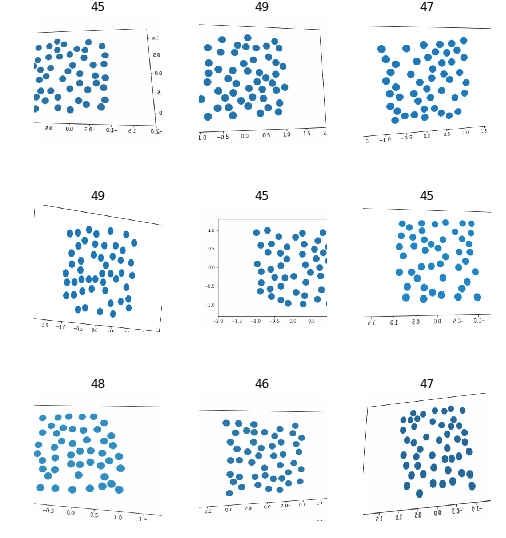
Try finding a visual pattern in this noise! After re-running a learner and trying to fine-tune it I was only able to achieve an accuracy of about 27% which is slightly better than chance.
I should note that although this system cannot accurately distinguish between images that contain 45-50 objects, it might still be successful at counting more generally. When I ran experiments with 1-20 objects, I noticed that its predictions were frequently only off by a little bit (eg. guessing 19 elements when there are really 20). It might be tolerable for some applications to have an “approximate estimate” of the number of objects in a given scene.
Reflections
I found this experiment really interesting and it taught me more about these kind of networks. This task is technically trivial to solve (Just count the blue pixels in each image) but our neural network struggles to make progress when there are no obvious differences between the classes of images.
It was also interesting and surprising to see how it managed to succeed when counting small numbers of objects. Even though these generated images come from a completely different distribution than ImageNet (generated plots vs photos of the natural world) it still managed to use the features it had learned to make sense of plots of a small number of objects.
Edit 1
It turns out that I was a bit hasty here. After receiving suggestions from other fastai forum members I re-ran my experiments with a larger dataset and more sensible image transformations (no zoom, no crop, no warp) and achieved 100% accuracy. The network also succeeded with 100% accuracy when the objects were of different sizes.
The next step will be to re-formulate this problem as a regression problem as opposed to a classification problem. I am interested to see how it does on counts it has never seen before.
12 Likes
Have you tried treating this as a regression problem instead of a classification one? I would probably personally also attempt a different metric rather than accuracy…
Hey I am playing around with the same competition. I am confused about how to create validation set.
I see that you have used valid_pct =0.2. From what I understand, this argument will randomly take 20% of the data from the train folder and move to valid folder.Is this the correct way to do this? I only ask this because it is mentioned in this post that we should not have any driver common in test and validation set. The valid_pct = 0.2 will not ensure this. So what is the correct approach here?
1 Like
I find this experiment very interesting by design and for learning more so i had a look at your notebook.
I believe that you can improve on your score by working more with get_transforms. You are using the default setting and could probably improve the results by analysing an improve the effect of each tranform. Cropping doesn’t look meaning full in this cases
Another question is that looking at the data it is not clear to me what your are trying to learn the network - there is only on image of each count. should it count or make pattern matching ?
If you wanted the network to be able to distinguish between 49 and 50 then it would help a lot if you create thousands og different 49 and 50 dot images and tried out a regression objective also.
A next interesting level would be to do the same with dots of difference sizes.
I would love to see you take this further.
1 Like
Maybe the result could be improved upon if you don’t use any pretrained model (a fastai heresy!!) but instead train it from scratch. The images you have are quite different from imagenet such that maybe even the features learned by resnet in the earlier layers might only be just slightly useful.
1 Like
just to add, I suspect doing the vertical flip in get_transforms would be useful too:
get_transforms(flip_vert= True)
1 Like
great stuff ! thanks for sharing !
Hi pierre, just a little note about your post on medium. Please, be aware that deep learning is far from being an algorithm, it actually uses many different ones but it cannot be considered an algorithmic approach. Your expression “a Deep Learning algorithm” seems to me an oxymoron. Sad no one told you that before
1 Like
i can’t seem to get my versions of your example to work…
i even copy/pasted your code from github … but i get this error as i do with other attempts
when created dataBunch :
IndexError: index 0 is out of bounds for axis 0 with size 0
!curl https://course.fast.ai/setup/colab | bash
is this required or not
i do get this error here:
Updating fastai… spacy 2.0.18 has requirement numpy>=1.15.0, but you’ll have numpy 1.14.6 which is incompatible. Done.
tia -doug
Did u download the image data before creating databunch?
Before running databunch, you need to generate the image dataset.