Hi everyone,
I was curious about whether a CNN could learn to count objects in images. It turns out it is an active area of research, with at least two approaches, one via detection (bounding boxes), and another via regression.
I wrote a notebook where I explore the task of counting objects by regression, where the task is to count the number of horizontal rectangles in images with both horizontal and vertical rectangles on a black background. I tried to design the experiment challenging enough so that obtaining a CNN with accurate predictions could be interpreted as it learning to count. Then I dived into analyzing the testing performance to conclude whether the CNN generalizes well.
Details in the notebook and readme, but the conclusion is that the CNN shows very good performance learning to count objects, with a very interesting ability to generalize to images generated with parameter values not seen while training.
Images: synthetically created. The number on top with the label of the image (target variable for regression), which is the number of horizontal rectangles.
The images were generated using 3 parameters: number of objects (horizontal rectangles: label); total number of rectangles, and size of the rectangles (constant within each image). For training the images were generated using certain values, while for testing images, additional new values were used, in order to later evaluate the capacity of the trained CNN to generalize well beyond training.
The number of objects in training is between 5 and 45 (only 28 values in this range), while for testing all values from 0 to 50 were used.
The reason to put both horizontal and vertical rectangles, as opposed to only horizontal ones, was to prevent the CNN to learn the easy correlation between white pixels and counts of rectangles.
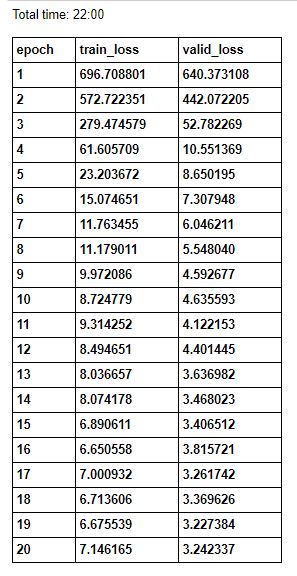
Train/Valid Loss (MSE):
Performance: the mean absolute error (MAE) on validation was 1.4, and on testing (including images generated with values different from those in training) went up to 2.3.
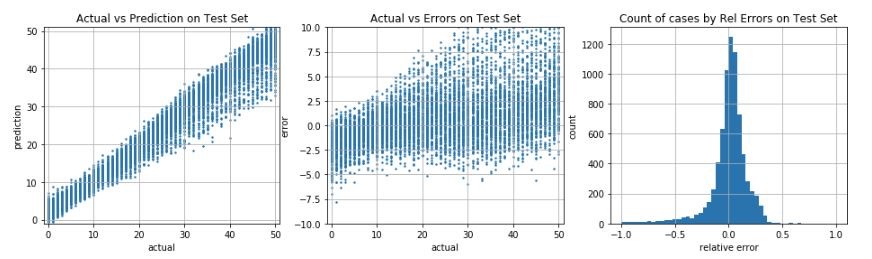
Plots: Actual vs Predicted, Actual vs Error, Relative Error distribution:
- Testing for images with known values for image parameters:







 .
.
 )
)