Thanks to @raimanu-ds to point that out. Didn’t catch my attention that anything medical, it is almost never the accuracy that matter. That definitely will mislead you using wrong metrics.
But it is still good to try some model ensembling after that.
Ok so for lesson 2 I created a web app for the malaria detection dataset on kaggle.
And it achieves 97.2% atm, tho I think fiddling around with LR would yield better results I think. Would love to hear your opinions. PS : I had a hard time deploying the starlette code on pythonanywhere so if anyone has any tips I would really appreciate it, but I used ngrok to make other people try it out.
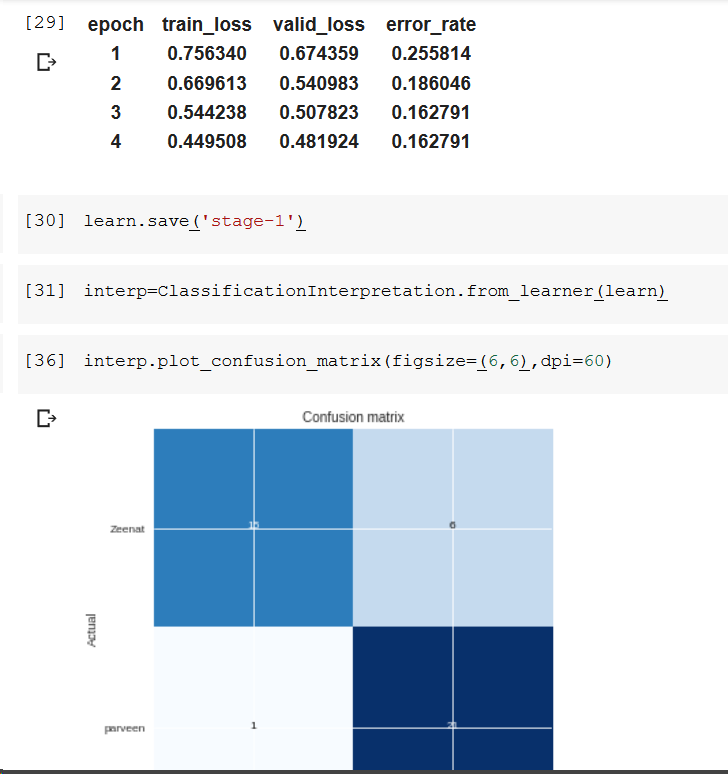
I have tried to create classifier to predict if particular image is of Zeenat Aman or Parveen Babi because since childhood I get confused between these 2 Indian actress.
I know its a very small dataset…One more thing.I did not create separate folder for train and Validation while creating dataset.However during training I gave following command
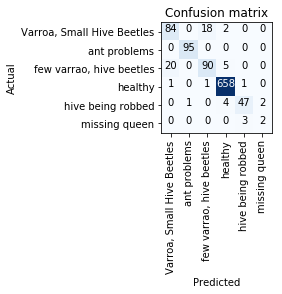
I am a beginner to Deep Learning and recently started the Deep Learning Part 1 MOOC. I have completed the Lesson 1 and as part of my exploration, I took up a dataset to classify the health of a honey bee from Kaggle (https://www.kaggle.com/jenny18/honey-bee-annotated-images). The performance of the model was better than the performance shown in the Kaggle Kernels which was really exciting for me! I have uploaded the notebook to my GitHub https://github.com/vineettanna/Honey-Bee-Health-Classification
I see lot of people have deployed their work as web app. I also remembered in the lesson video, someone asked if it’s possible to collect feedback from user such that the model can improve. Anyone has done this? I recently read this “online” learning, or learning from less common sample, can lead to something called “Catastrophic Forgetting”. Not sure if @jeremy ever discussed in the MOOC.
I tried beam search (in current fastai master, 1.043) on Dave Smith’s Deep Elon (tweets generator) and posted a simple kernel on Kaggle: https://www.kaggle.com/abedkhooli/textgen-143
It needs some parameter tuning and may work better on guru tweets than Elon’s (Dave’s dataset is on github so was easy to test).
After Lesson 1, I built an old vs new Mini (the classic little British car) classifier. I’m British, and who doesn’t love Minis? 18|461x420
Anyway, I have a background in machine learning, and have built models using Keras and Tensorflow. I was astonished to find that the model built using the techniques from Lession 1 had almost perfect accuracy on the validation set. In fact, when I looked at the confusion matrix, and then at the only two pictures it was misclassifying, I found that it wasn’t getting one of them wrong at all! If you look at the picture (and the positioning of the petrol caps) the two Minis in the picture are in fact one of each: an old and a new! 57|303x304
Amazing!
You wouldn’t be the first one to submit only ones (1) and zeros (0) to this competition. You should submit the probabilities (0.98765 for example). Check if this brings your validation score closer to the Kaggle score, if not already implemented.
I’m struggling myself to improve from approximately 0.975 on Kaggle to anything better. In the validation set I can reach 0.99 accuracy on the full dataset. Maybe I’m overfitting, although my validation loss is still lower than the training loss
After watching the third lesson I tried to challenge myself and go through a Kaggle challenge on image segmentation, in particular, ship detection from space. I’ve used some best practices for working with large datasets and highly unbalanced data to achieve 0.91+ dice with 256-sized images. Take a look!
Ps. There is also a Docker image which can be deployed for (fun) inference.
The repo is here.
Created a classifier which will classify popular indian cars. I have used google_images_download which helped me in downloading approximately 100 images per category of images.
More about this project can be found at my github repo.
Please let me know your comments and feedbacks. Thanks to @arunoda for his amazing blog on creating a dataset for cars which helped me a lot in collecting the dataset for this project.
For my own work, I need to work with images of 4 or more channels, not just the standard 3 RBG channels. As far as I know, both @ste and @wdhorton have shared implementations of 4-channel images for the Human Protein Atlas Kaggle competition. However, none of their code works for images of 5 or more channels because they rely on fastai.vision.Image. Here, I have implemented a way to use images of any number of channels, as well as custom ways to visualize them.
The notebook doesn’t solve any real problem, it just showcases the implementation. I figured it’d be helpful to other folks that have images of 5+ channels in their own projects.
I have read a few post saying that training loss is higher than validation loss. One thing that needs clarification: Is the data augmentation (that get_transforms()) apply to train data set, and not to validation data set. I don’t remember this being discussed in the lesson, but i think general practice is you don’t apply data aug to validation set.
So if you have very strong data augmentation, this will lead to a tougher training set, and your network may have harder time to predict. Your validation set stays at the same difficulty, and so can score better in the loss than the train set.
It will be interesting if you try to vary the amount of data augmentation, and monitor the train loss again.
Hello fellows,
I am sharing my first work on the forums. I have created a classifier to identify which city a skyline belongs to. I used google images to train ResNet 34 model on New York, Chicago, Dubai and Hong Kong’s skyline and got close to 86% accuracy. I am sharing the link the to website here