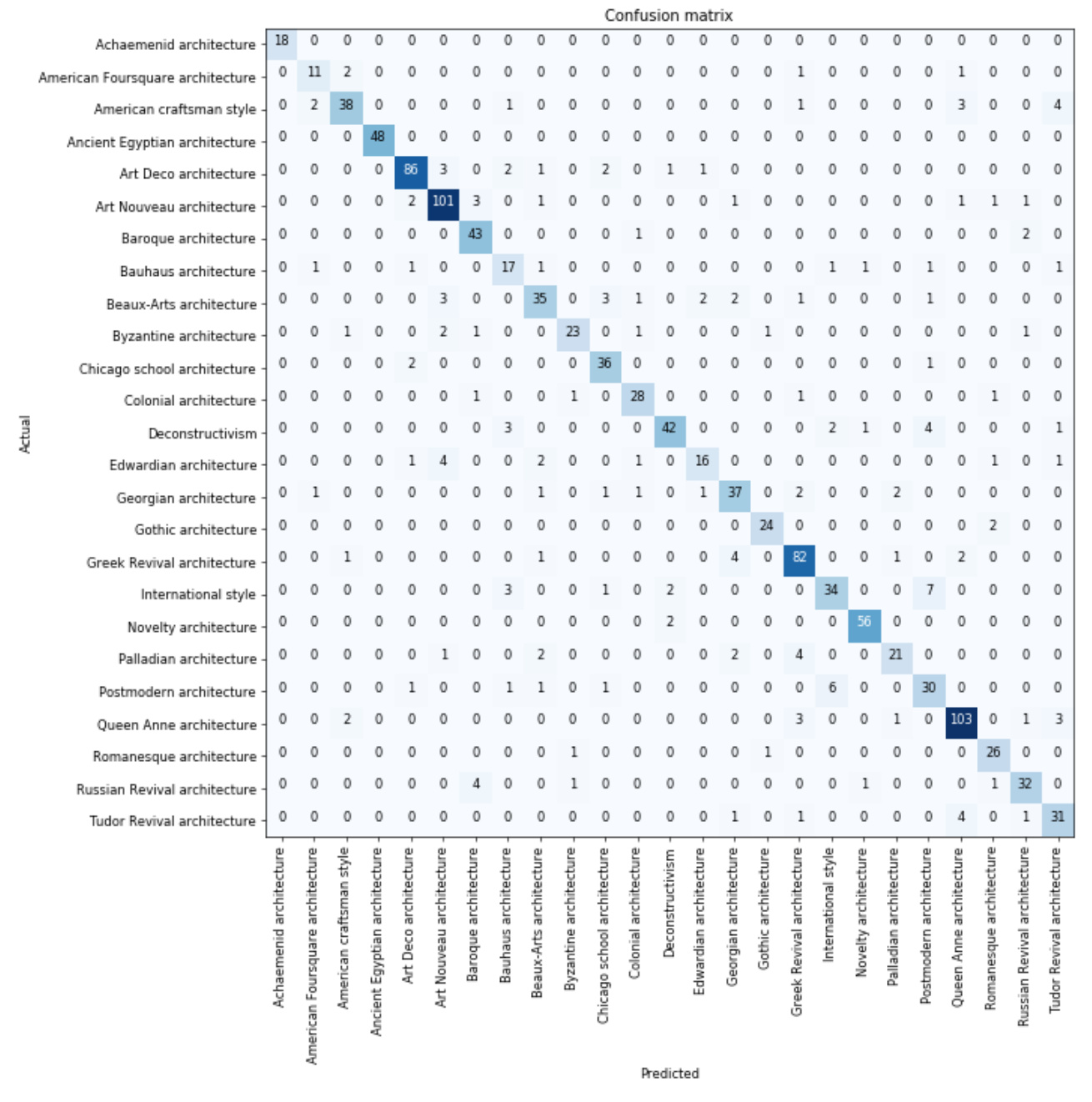
I downloaded an architecture dataset to see if I could classify different styles of architecture. There are 25 types across 5k images in the dataset, originally scrapped from wikimedia.
I’m excited to see my error rate is far below the original 2014 paper’s classification rate of ~47% accuracy when using all 25 classes. Surprisingly mine is around 85%!
I’d like to do a visualization of what features are most indicative of art nouveau. I’ve seen a few inspections of activations based on PCA but that doesn’t highlight the areas of a picture or show the activation of the layer. Can anyone point me in the right direction?
Hi All,
I had the chance to interview another fellow student of ours. You might recognise him as the creator of DeOldify: DeOldify uses Deep Learning to colorize old B&W images. Jason Antic: @jsa169 Link to the interview
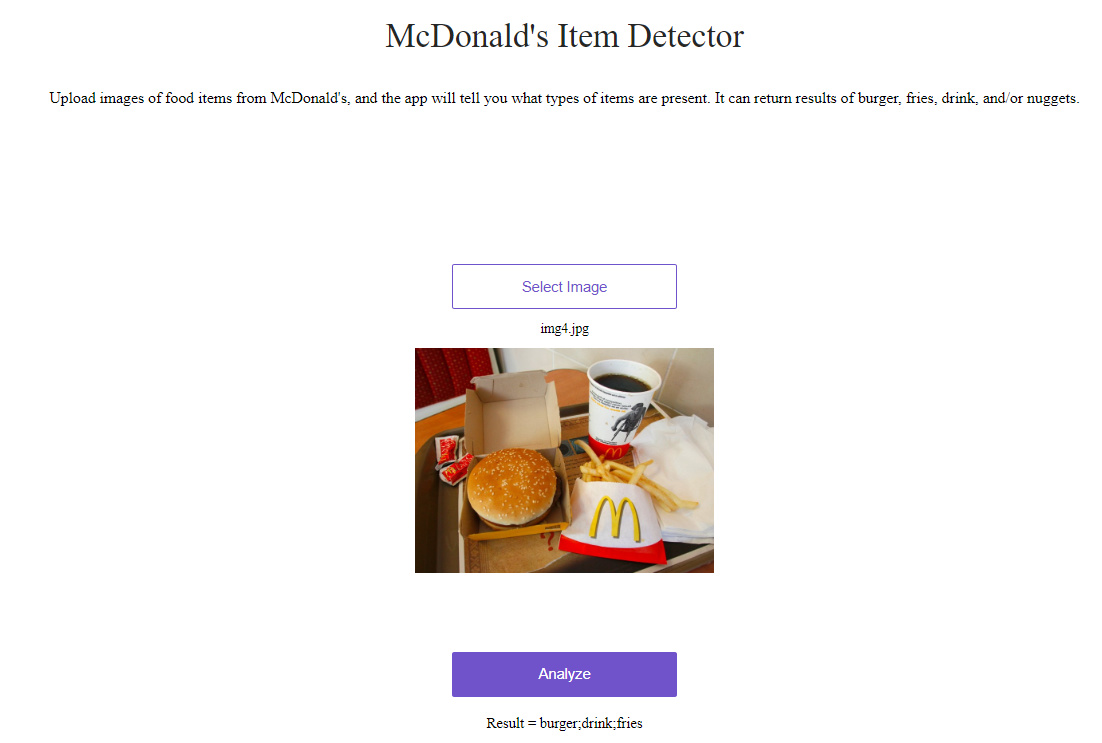
After lesson 3, I created a multi-label image classifier that detects McDonald’s food items. It’s available at https://mcdonalds-item-detector.onrender.com/. You input a picture of a McDonald’s meal, and it tells you whether any ‘burger’, ‘fries’, ‘drink’, or ‘nuggets’ items are present.
I think food classification is a really interesting area. Some potential applications could include improving food safety for people with allergies, improving the eating experience for people who are blind, and potentially enabling reverse-engineering of recipes.
I used a resnet34 model, and did some progressive resizing. I started out training with 128 size images, then did some fine-tuning, then trained with 256 size images, then did some more fine-tuning
I was able to get to ~94% accuracy (with a threshold of 0.2)
I followed Jeremy’s suggestion in the lecture, and did a lot of playing around with learn.recorder.plot_losses() to see the effects of different learning rates
Getting the data for this was a pain. I was able to automate the image downloading, but then I created a csv file and had to manually input tags for all of my images. I ended up using only ~150 images because it was so tedious. I definitely have a much greater appreciation for people who put together huge datasets!
Hi! I wrote a piece on the DeViSE paper which combines word vectors with image classification. If you have any feedback on how to make it more understandable/accessible I would appreciate it. You can find it here:
I agreed the data collection is the most tedious one. Some plausible strategy
First collect pic of images with only 1 food item only, and hopefully this reduces the labor of labelling, and trained an single-label classification model.
Use this model to make predictions on a greatly expanded set of meal photos (multiple food item). Use sliding window or random cropping on each image, your model may predict different food depending on where that cropping landed.
Label the meal photo with all the results from running the model, and you will get multi-labels
So this can bootstrap your data set. The downside is that the model is going to make mistakes and not as good as you doing it manually. So it really depends, if you have massive amount of meal photos, this may worth a try.
Hi friends
Just published the last part of a 3 part article about predicting malignancy in tumors combining a 2 layer neural network built from scratch in Python and the Wisconsin dataset. Although this is all written in standard Python, I was inspired to begin writing articles because of fast.ai and I mention fast.ai related stuff at different points in the articles. I recently finished watching the first pass of the new 7 lessons of V3 and I look forward to continue enjoying fast.ai
The articles include 3D animations of loss landscapes that I created specifically for them
Hi all. I created a multiclass cloud classifier and pushed it to production, combinine lecture 2 and 3.
Its a Resnet50, learned on cca 14 000 cloud images (10 base categories, representing the 10 base cloud types) accuracy around 0.9 after transfer learning and a short period of unfreezing.
Thats nice work! Is this “altocumulus”? i opened that web site with my phone and snap the photo you posted. If it doesn’t take you much work, try to deploy it on a mobile device and have it run natively. for iPhone 7S +, the running speed is very respectable, and this allows making inference directly with the video feed. In my opinion, this is another level of UX than the website. Just imagine users pointing their phone and scan the sky, and have the cloud type reported in realtime!
A question I have, do you know of any dataset for identifying rock type? i.e. sedimentary, Igneous, and maybe rough estimate of mineral content (e.g. red looking one has high iron content). This will be highly educational, and for budding geologist, a must have going out in the field. I dreamt of building this ever since i heard that deep learning can make this much more reliable, but i am constantly distracted. I would be surprised if no one has made one yet.
If i have your app as well as this, I can tell whats above me, and below me…
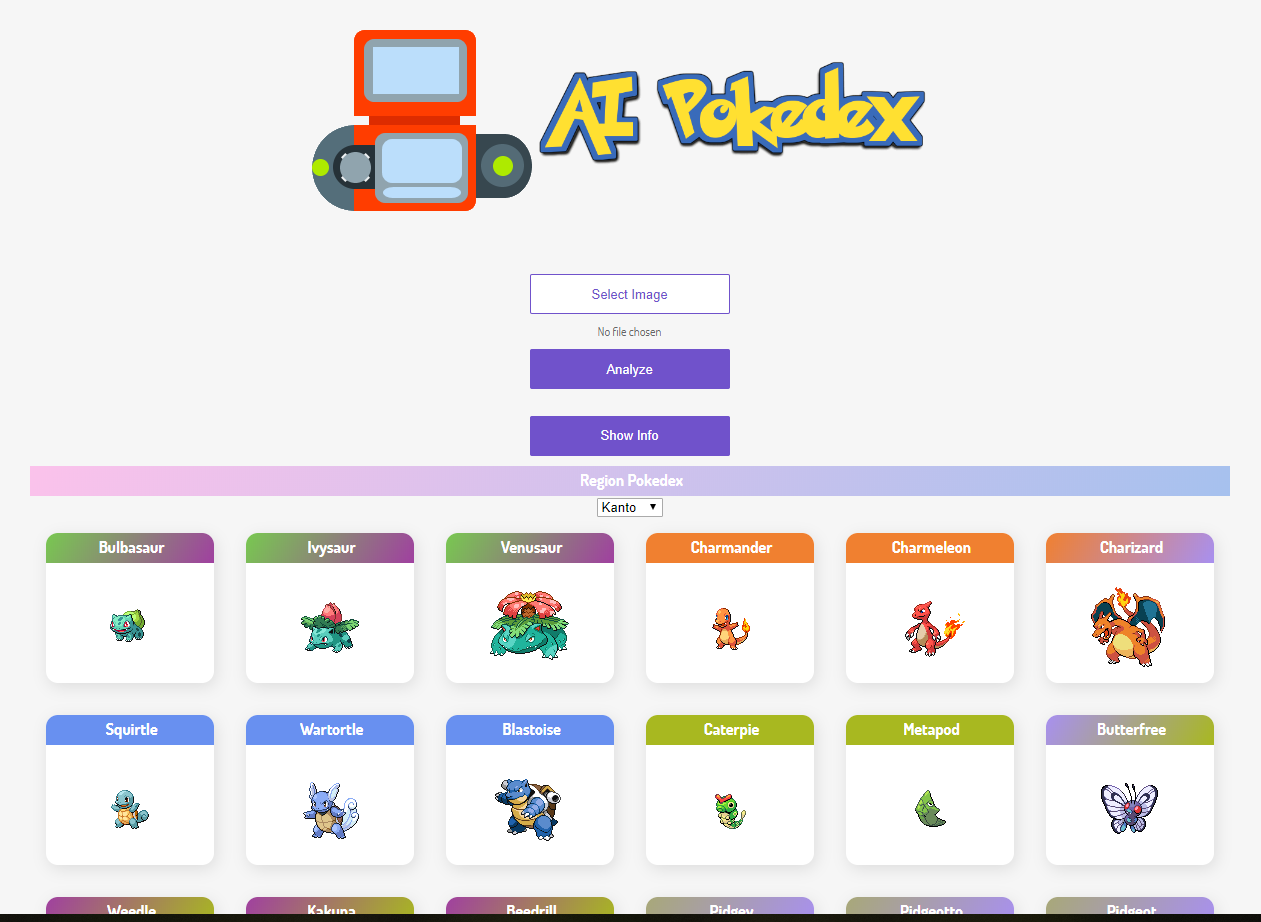
Hi everyone! I created a Pokedex. It’s currently available here. You can input an image of any Pokemon and it tells you what Pokemon it is and you have the option to view more information about the Pokemon after that.
Unfortunately it is a single-label image classifier as I couldn’t find any multi-label Pokemon datasets out there and labeling them myself would be a long process.
Technical Details
It’s trained on resnet34, with just horizontal flipping for the images for data augmentation, and I managed to get an accuracy of 87% which I feel is quite alright for the quality of data that I have.
The dataset used to train was built through using Bing Image Search API to download around 90 images of each Pokemon, amounting to around 70,000 images before cleaning.
A lot of data cleaning had to be done as some images were duplicates of one another, especially for those Pokemon that usually appeared together, or those that evolved from one another. I modified the ImageCleaner code to automatically move around the relabeled images to the correct folders so that cleaning was easier. But even then, there’s still quite a bit of uncleaned data because of the sheer number of images.
Code for the webapp is available through the links inside the webapp. I can provide the code for my model if anyone wants it too.
Great fun
Regarding multi-label, its a bit of work but perhaps you can create it.
The algorithm could be something like:
Take your single-label dataset
Take a random 1-n-sized subsample from it, getting 1-n one-label items (where 1 is what you have now and n is max number of samples you support in multilabel)
Generate a new image from these 1-n images (for example blank canvas, random or roughly random positions where you insert images from 2…Imagine it like throwing cards on a table and then photographing the table). Label it with labels you already have from 2.
Train
…
PROFIT!!!
In theory, it could possibly work. In practice, well theory and practice can differ
I shall try a version of what you are suggesting using Pillow over the next few days.
But I’m not sure of how accurate the eventual recognition for actual multi-Pokemon images (such as drawings, posters, screen captures from the anime) would be, considering the fact that they tend to be in different positions or be hindered by parts of other Pokemon.
Hi everyone! I’m working on what I’ve learnt from lesson 1 and I wanted to create a classifier which could detect if two images are a visually similar. So I would have two folders: good matches which contains pairs of images which are similar and bad matches which contains image pairs which are dissimilar. I would then be able to submit any pair of images and the classifier would predict whether they are a good match or not.
Is there a way to set up the classifier so that it takes input as a pair of images instead of just a single image?
Thank you Glad you like it.
I’ve been thinking about a mobile app but will probably postpone it or let it pass, as I currently suck at mobile development and would probably waste a day or two at it learning the ropes, when someone half-competent could do it in a couple of hours. Also, id prefer it being cross platform (eg. Xamarin) and I am under no illusions that Im good at UI.
That being said if anyone is up for making a nice looking Xamarin shell of a mobile app,it should be relatively easy to integrate it and I’d love to do so.
Also, and perhaps more interestingly, such a project would be a usefull mobile starter for all the OTHER projects (so like Jeremys’ starter but for mobile) and looking at it that way it would be extremely useful.
Re sediments, like the idea. Dont know where you could get data, though. Sorry
Probably the easiest way would be to put them side by side (so, create a new image combining two alike, or two not alike images). Label according to type.
If i was doing it (it is slightly unusual) id do a small proof of concept not to waste too much time collecting data. Also id take care to exclude image order, so lets say A and B is similiar C and D are not. You’d want to create:
AB, similiar
BA, similiar
CD, not
DC not
(Note that I’m doubling each pair,as you are stiching images but dont really care that AB and BA are differently ordered)