Update:
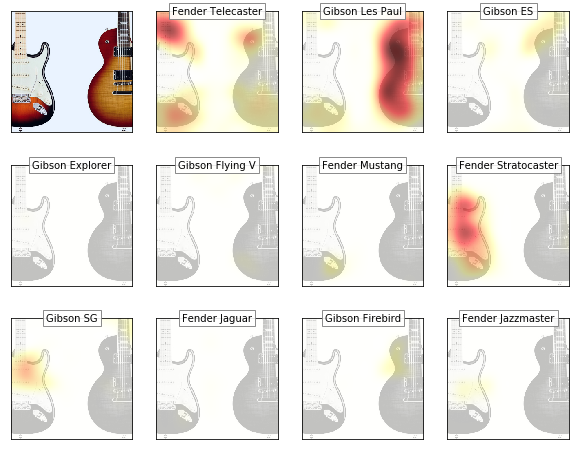
Managed to produce GradCAM activation maps (with kind support from @henripal)! Unfortunately, I have problems to incorporate them into the Flask app atm so the app is not updated yet.
Anyways, this is the interesting result for a double classification challenge (the model goes for the right guitar in it’s prediction)…
Seems like:
- a telecaster is associated with bright fingerboards
- a Stratocaster feature is the body horn and the tone knobs
- a gibson Les Paul is identified by the body contour
The notebook is here: