I think your final line is my favorite in the whole starter pack. I had never thought of putting this directly into the notebook and it’s amazing:
!kaggle competitions submit -c quickdraw-doodle-recognition -f subs/{name}.csv.gz -m "{name}"
I think your final line is my favorite in the whole starter pack. I had never thought of putting this directly into the notebook and it’s amazing:
!kaggle competitions submit -c quickdraw-doodle-recognition -f subs/{name}.csv.gz -m "{name}"
I like the idea that you are incorporating users feedback into your next training iteration. However, you do want to put manual inspection in between because feedback is not always right 
Talking about collaborative filtering, I’ve created a small post when was watching the previous version of the course. The code from the post is written in PyTorch but probably could be interesting for someone who wants to dig deeper into the topic.
One of the gists from the post that shows writing of a small custom nn.Module with embeddings:
Update 1: Not sure why the link to Medium is not rendered properly, here is a plain address:
https://medium.com/@iliazaitsev/how-to-implement-a-recommendation-system-with-deep-learning-and-pytorch-2d40476590f9
Otherwise, you probably could find it via @iliazaitsev username on Medium.
Update 2: Ok, Medium support responded that my account was blocked automatically by their spam filter. Probably they need try some Deep Learning methods to reduce the number of false positives 
looks like that medium link is broken tho 
Great project! It’s good to finally get to see your work after you talked about the idea in our previous meetings.
Are you pointing to this study group run by Assoc. Prof Kan Min-Yen?
I am looking forward to your detailed blog post. Thanks.
Hm, thank you for letting know! Not sure why but Medium shows it suspended
@ttgm Would you mind sharing your notebook please?
@bholmer interesting work! How did you separate out and visualize the different areas of the painting that appear to belong to different artists?
Hi Jon. The latest update to the API is quite different from the code in my post so I’ll hopefully refactor it this weekend and link to the new notebook at the bottom.
I used facial keypoint detection dataset from kaggle. (CNN+regression)
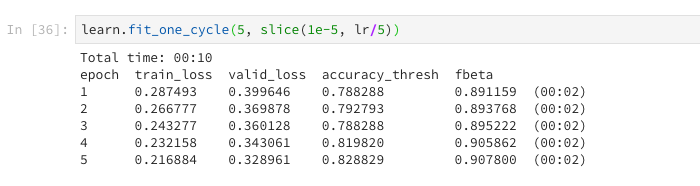
It’s a challenging problem. Mainly for two reasons.
As you can see, the training data is not very accurate.

Rmse Loss
Predictions
What I learnt…
Also, I have re-structured the original dataset into jpeg images. https://www.kaggle.com/sharwon/facialkeypointsdetectionimg. I think this will be helpful for beginners.
Notebook is still a work in progress. I’ll share a clean version soon.
Also, The submission file is a bit weird. I’m not sure why they are not evaluating on the basis of all the points.
To do:
Where are you guys hosting your starlette API?
I’ve been using ZEIT but it’s slow as heck when waking up the app from a frozen state. Impressed by how responsive your emoji app is and so interested on what you all are doing.
I’ve made lynx classifier (it classifies which lynx species is given lynx).
https://which-lynx-is-it.now.sh/
Error is something 20%ish (lost the notebook, because of issue with gcp). Considering the fact that the dataset was noisy it think it’s good. Interesting thing is it really has problem classifying baby lynxes for some reason.
Hopefully I will have time this week to write a blog post about it.
It’s just a small ec2 instance (behind an ELB to terminate the SSL which is required for WebRTC to work).
I was really surprised at how much throughput we could get during fastai inference. The fact that we were sending smaller cropped images from the client really helped.
As in “Elastic Load Balancer”?
I’ve written the following short Medium post doing some theory review of the concepts we deepened into during Lesson 3, like the learning rate and activation functions.
Yes. Another group used fastai for sentiment analysis on market news to perform Forex market prediction.
If you use the production guide we provided then it won’t go to sleep, so you won’t have that problem ![]()
Thanks for the 411!
I’m doing a multi-label prediction project with Pizza Slices. My ultimate goal is to make a GAN-powered app that lets you design the “perfect pizza” slice by clicking buttons to add toppings. This is a first go with using the multi-label classification task like the planet notebook.
My dataset is pretty tiny (only 167 images total).
The potential labels are:
82% accuracy after some initial fine-tuning.
I’m not sure how to do the most_confused or confusion_matrix with this task. I would love some advice!! Thank you.
I tried to classify programming languages based on the text. I want to test out a theory that you don’t need to read through specific text in a document to be able to classify what kind of a document it is.
My dataset was not very large. My error rate was pretty high (30% for 3 classes)
My next course of action will be to increase the size of the dataset and try again. However, please give me suggestions on how you would approach the issue differently (still without using OCR or NLP).