I used the data preparation script from AudioNet (https://github.com/vishnu-ks/AudioNet). How did you generate spectrogram images from audio files?
2 Likes
Thanks! I’ll look into it.
I haven’t found anything concrete yet. For OCR I found the “Khatt Database” - I contacted the authors to get a download link and they haven’t replied yet.
The other data sets I found are not OCR - mostly Wikipedia articles, tweets, and text-messaging dumps for sentiment analysis and other NLP applications. It seems that Stanford, Concordia University.
I want to dig deeper and decide on a project to work on, it’d be awesome to work together.
1 Like
Update:
Managed to produce GradCAM activation maps (with kind support from @henripal)! Unfortunately, I have problems to incorporate them into the Flask app atm so the app is not updated yet.
Anyways, this is the interesting result for a double classification challenge (the model goes for the right guitar in it’s prediction)…
Seems like:
- a telecaster is associated with bright fingerboards
- a Stratocaster feature is the body horn and the tone knobs
- a gibson Les Paul is identified by the body contour
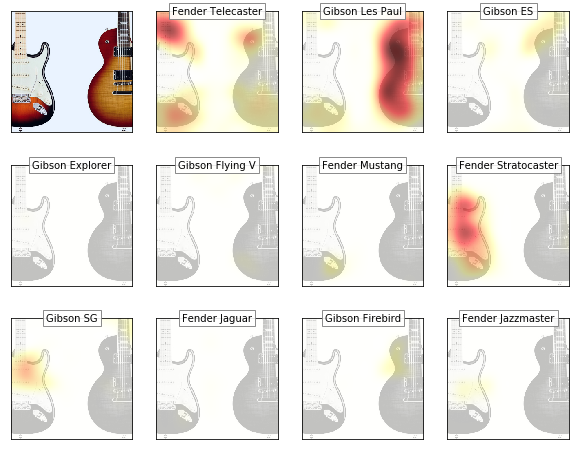
The notebook is here:
15 Likes
I have been successfully converting 2D LIDAR data into images. I am using a rotating lidar inside of pipes to look for defects in the pipe. The lidar itself provides 1 measurement every 1/4 of a degree for 270 degrees. So each “row” is 1080 points of data and each data represents the distance at that angle.
A single scan of the data looks like this:
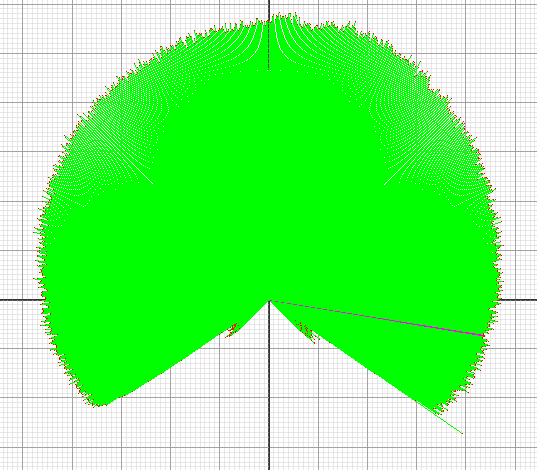
I am squeezing 200 scans on top of each other and normalizing and getting out data that looks like this:

I am doing some more math on top to get better results from my models. This math is to do a vertical diff row by row.

I’m not a huge fan of doing the extra math on top of the raw data before sending into my models for training but i have been getting better results on basic classification.
If anyone wants more information or just to chat about LIDAR please feel free to ping me.
20 Likes
This is awesome, thank you for sharing!
Hello, guys. I’d like to share my simple baseline for Human Protein Atlas Competition on Kaggle.
1 Like
@bjcmit I moved the pre-processing of audio (the steps that download, generate spectrogram, stores in google drive) into a separate notebook, here is the a blog post that goes through everything link. Sorry I should have done/shared this earlier.
1 Like
Yes, it is referred to as the alpha channel

A small utility for the lazy practitioners!
5 Likes
I’ve made a web app to identify the species of a tree based on a photo of its bark
https://treeid.now.sh (source code)
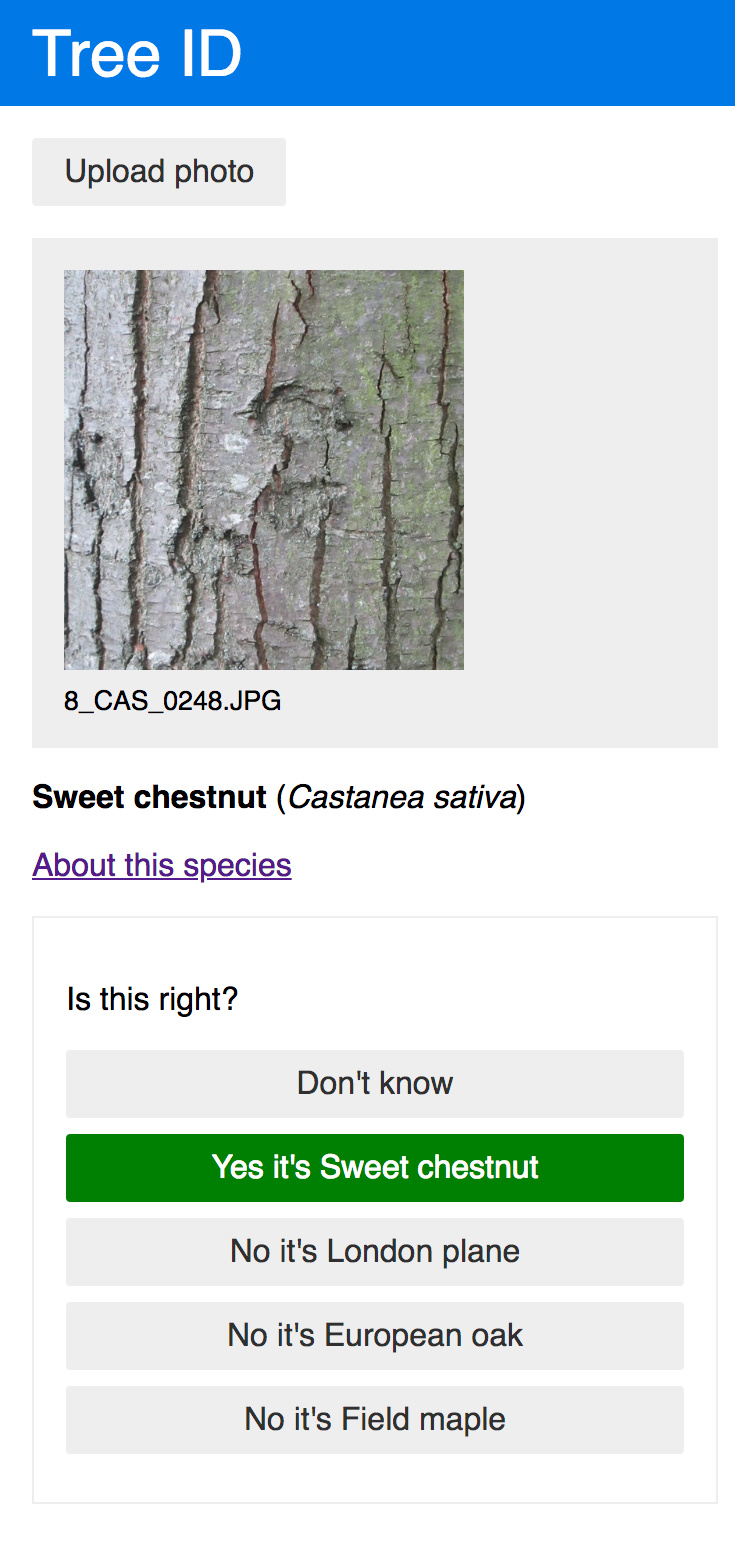
It’s currently trained on very small dataset I collected from eight trees in the local park. As such it only knows about London plane, Sweet chestnut, European oak and Field maple and its accuracy is ~70% (see update below).
Importantly, it also uploads the submitted photo to AWS S3 then asks you if the classification was correct. Based on your feedback it labels the uploaded image which means the more people use it, the better it will get. It doesn’t yet retrain itself automatically though.
A recent paper, Tree Species Identification from Bark Images Using Convolutional Neural Networks got 94% accuracy over 20 different tree species using a much larger data set of >20k images. Their 30GB corpus is available to download and I plan to pretrain a network on it before fine tuning for my smaller data set.
UPDATE: after collecting photos of more trees and training at multiple resolutions, I’ve got accuracy up to 93% and expanded the set of tree species to six.
26 Likes
I’ve trained a CNN Regression model to count the number of people in a crowd using the UCF-QNRF dataset.

Even though the model is underfit, it’s within a factor of 3 and often much better than that. This is pretty useful, it’s better than I can guess.
This graph shows the ratio of prediction:actual vs actual counts.
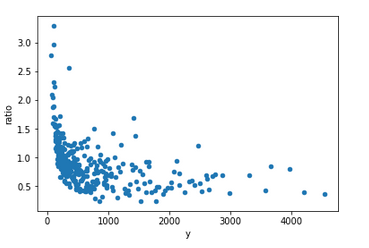
See the notebook for details.
22 Likes
Hi there! I wrote a short post on using the data block API. Any feedback, corrections, or suggestions greatly appreciated 
14 Likes
I used the CelebA dataset from Kaggle for a regression model.
list_landmarks_align_celeba.csv in the dataset contains image landmarks and their respective coordinates. There are 5 landmarks: left eye, right eye, nose, left mouth, right mouth
This notebook attempts to make a learner to predict those five points. I used a 50,000 subset of the 200,000 images in this dataset and got good results:

14 Likes
I have extended the last week’s (lesson 3) planet notebook to add support on creating a submission.csv file where we can upload to kaggle for grading.
5 Likes
I also used the same CelebA dataset for a multi-class classification in this notebook.
This was the result for a picture of me!
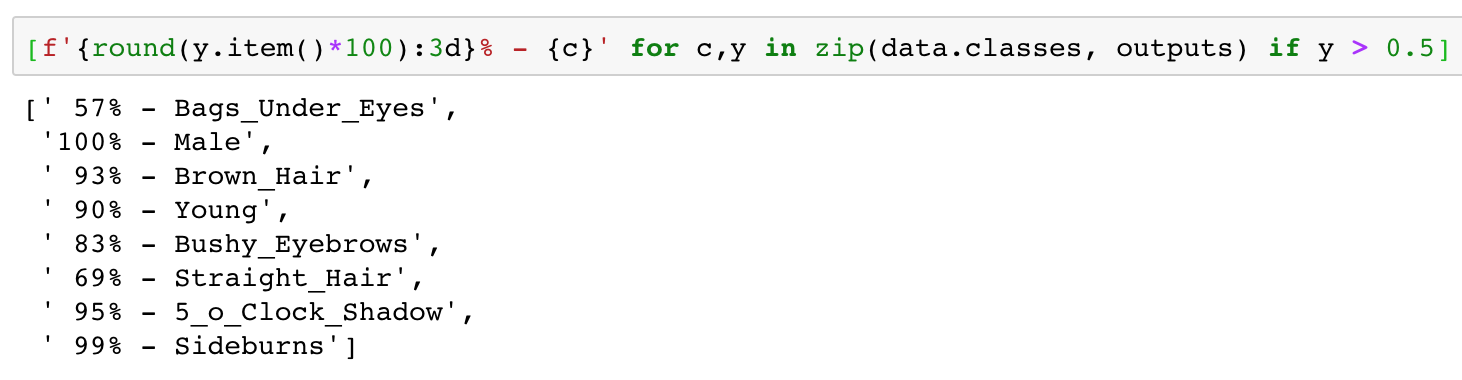
2 Likes
This is awesome! 
1 Like
The data block API is beyond amazing
I have transitioned the Quickdraw starter pack to now use the dataset API. There were models I wanted to train where I would need to hack together custom Datasets and potentially custom Dataloaders - the dataset API makes the headaches go away
As for the starter pack, this time I ironed out a couple of the rough edges of the earlier version. I also now generate the drawings on the fly so experimentation should be much easier now.
The only annoying thing about this dataset is how long training takes with size 256x256 - but maybe there is a way to get equally good results with smaller sizes?! 
24 Likes
Transfer-Learning - Image Classification

Transfer-Learning - Image Classification
Please check out my work on Optimizing Image-Classification using Transfer-Learning! This is an image classifier of 4 different types of Arctic Dogs! This medium blog tells you step by step of how I finally bring down the error rate at the end after a few tips and tricks from our previous lesson 3 lecture.
Thanks!
Awesome to see an example using categorical embedding w/ a tabular dataset ; )