Awesome @uwaisiqbal - I’ve been looking for data sets related to Arabic over the last few days. Mainly for purposes of Arabic text extraction from images. This data set looks like a good starting point, thanks!
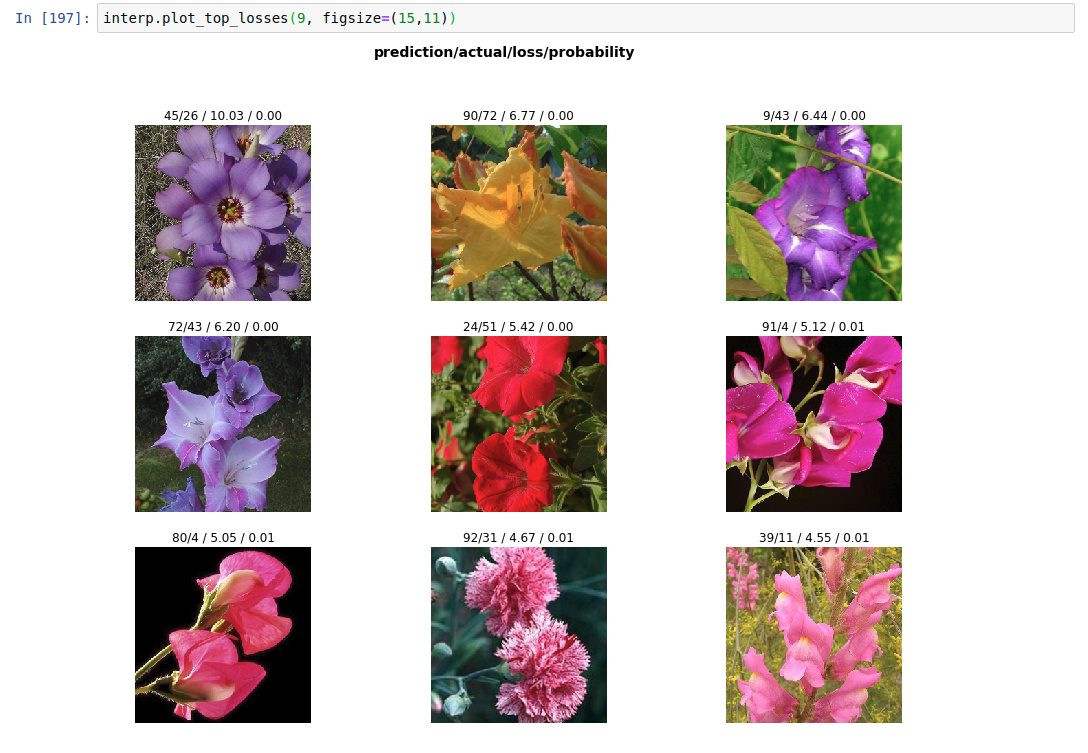
I put together a flower classifier trained on the Oxford-Flower-102 dataset. 102 classes of flowers and I used the same train/valid/test split as in the data split provided. With that split, only 11 images per class were used for training (a total of 1122), and the same number for validation.
The test set contains 6149 images.
After fine-tuning a Resnet50 model, without data augmentation, I got a 92.26% accuracy on the test set. I think it’s a great model considering how little data was used for training and the number of classes.
In case someone else wants to use the data, here is the code to split the data after downloading it into train/valid/test and put it in an ImageNet folder-structure (execute in a Jupyter notebook for the magic commands to work):
import scipy.io as sio
import numpy as np
import pandas as pd
data_split = sio.loadmat('raw_data/setid.mat')
image_labels = sio.loadmat('raw_data/imagelabels.mat')['labels'][0]
trn_id = data_split['trnid'][0]
val_id = data_split['valid'][0]
tst_id = data_split['tstid'][0]
data={'filename': np.arange(1, len(image_labels)+1), 'label': image_labels}
split = []
for file_index in data['filename']:
if file_index in trn_id:
split.append('train')
elif file_index in val_id:
split.append('valid')
elif file_index in tst_id:
split.append('test')
data['filename'] = ['image_'+str(n).zfill(5)+'.jpg' for n in data['filename']]
data['split'] = split
# This dataframe has three columns: filename, label, and split (train/test/valid)
image_labels = pd.DataFrame(data)
# Execute once to create dir structure + copy the data from the jpg folder to the new labeled, split folders
# ! mkdir raw_data/train
# ! mkdir raw_data/test
# ! mkdir raw_data/valid
# for split in ['train', 'valid', 'test']:
# for label in range(102):
# label = str(label+1)
# ! mkdir 'raw_data/'$split'/'$label
# # Copy images to their labeled folders
# for index, row in image_labels.iterrows():
# #print(row['filename'])
# fname = row['filename']
# split = row['split']
# label = row['label']
# ! cp 'raw_data/jpg/'$fname 'raw_data/'$split'/'$label'/'
6 Likes
I am working on something similar in my office! Nice to see your results. Would try to apply that in my work. Thanks!
Which datasets have you managed to find?
I have access to a dataset for OCR with Arabic scientific manuscripts from this project - https://www.primaresearch.org/RASM2018/
I’d be interested in working together on Arabic OCR if you’d be up for that
2 Likes
First, thank you for alerting me to Crestle’s policy until year-end for storage. It even has a real terminal, unlike Colab. GCP keeps running out of resources and Paperspace stopped saving my updated notebooks a while ago (which may have been fixed - I haven’t checked). I ended up using Colab, which leads me too…
Second, I ran the core portions of Lesson 2 on Colab w/o incident. By ‘core’, I mean the learners and the models and even the image verifier. However, Colab doesn’t support widgets, so the FIleDeleter/ImageDeleter functions do not work. Otherwise, it seemed fine.
Did you have a different experience w/ Colab?
Thanks for sharing. Someone at my office asked about use cases for NNs, and time series was one of my examples. Now I have a working example I can share with him.
@GiantSquid and I created this Chrisifier:
For aviation enthusiasts, I’ve updated the aircraft classifier project that classifies aircrafts into civilian, military (manned) and UAV (unmanned) categories. I have pruned the dataset and updated the model. Using resnet50, it has improved quite a bit.
Using the new model I have created this web app. Check it out at: deepair.
I’ve written the following short Medium post describing some of the details. The accompanying notebook can be found at this gist.
1 Like
Hi everyone,
I have created a binary image classifier to identify abnormal and normal brain images from MRs.
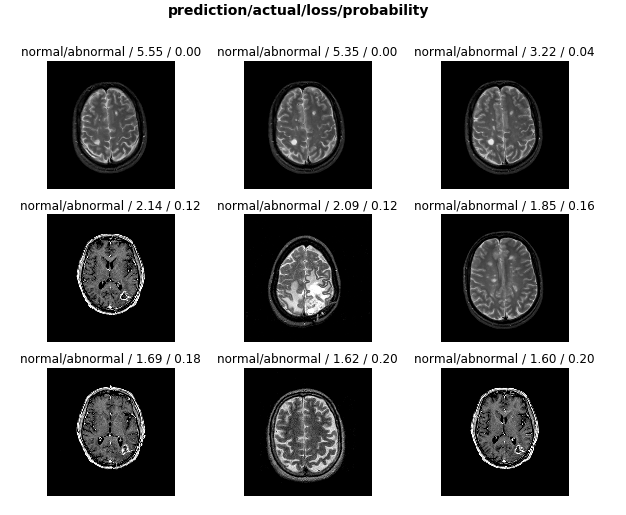
and deployed it
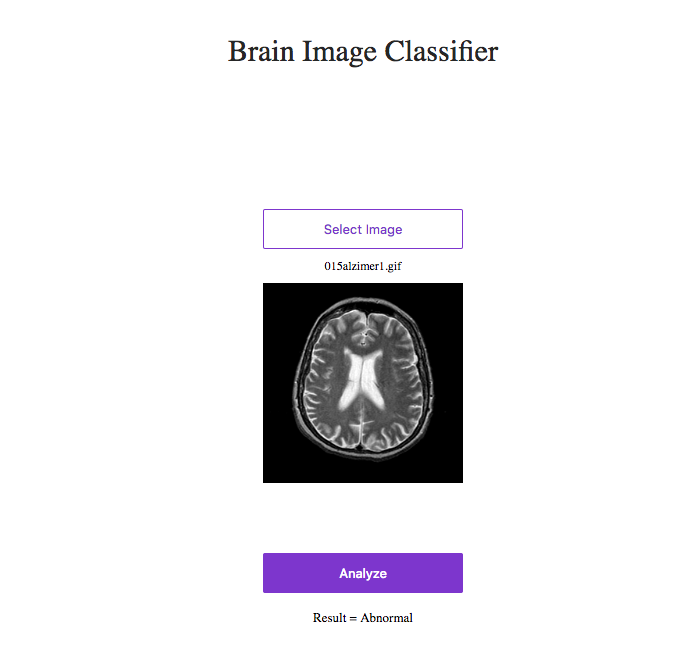
you can test it : https://brain-mr-images-classification.now.sh/
Thank you so much for all your help and support.
9 Likes
These results look encouraging - is your validation set from plants that are well separated from those in the training set?
Hi Everyone,
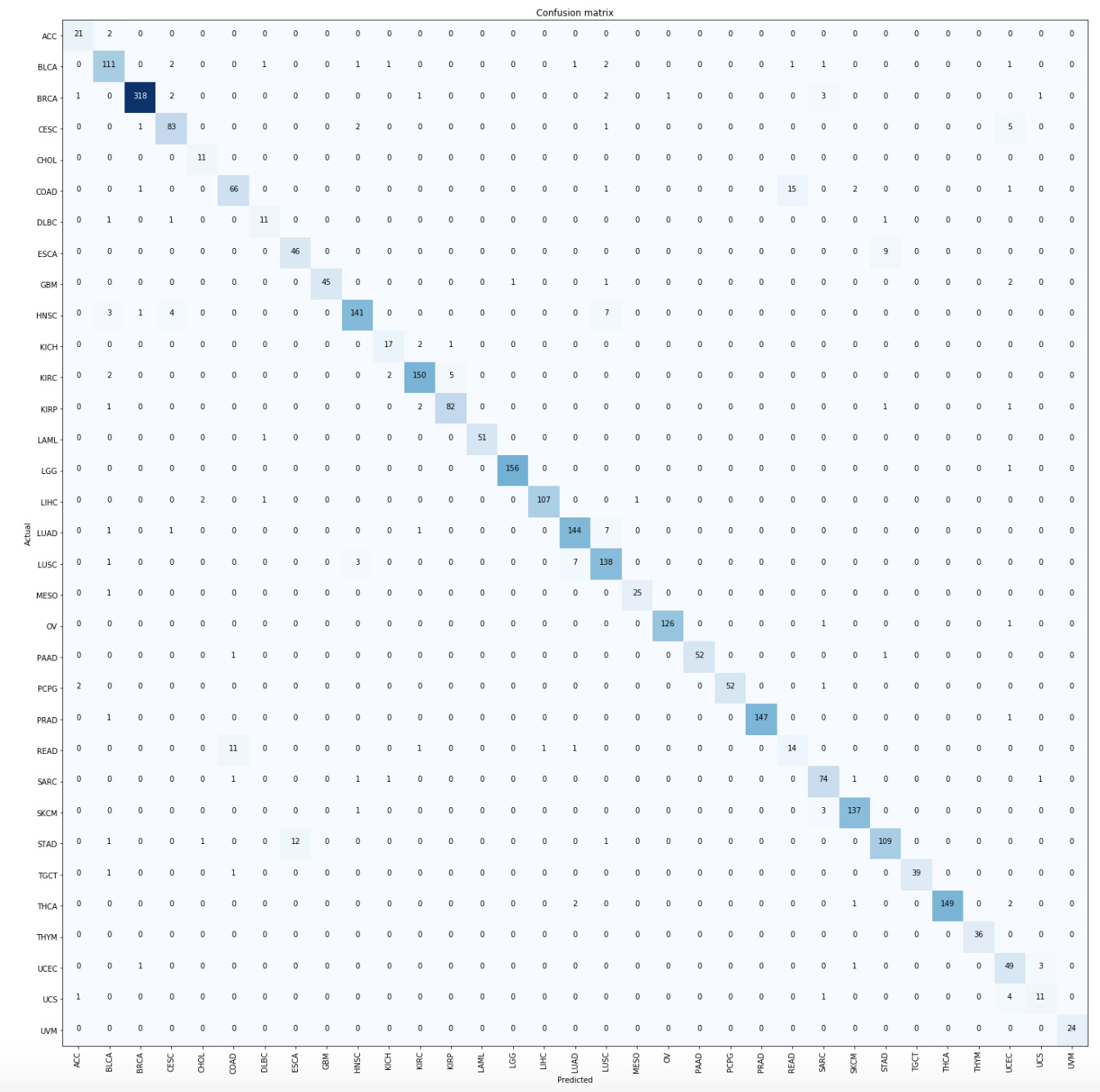
I made Birds classifier based on what I learned in lecture 1 and 2 so here it is
Here I am using a pre-trained ResNet34 model.
The accuracy is 91%
The confusion Matrix

1 Like
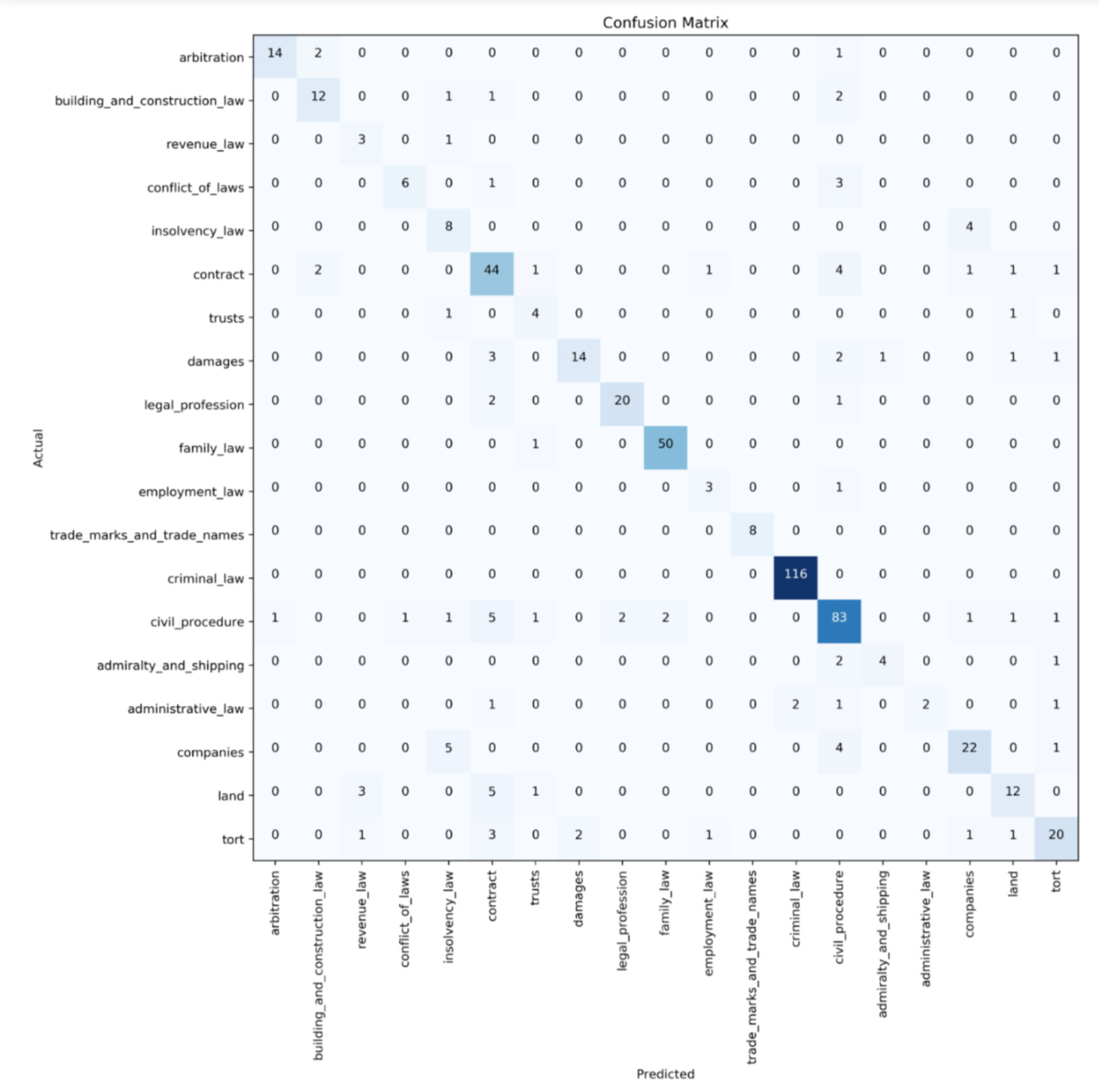
I successfully trained a text classifier on legal judgments based on the lesson3-imdb notebook. A multi-label classifier would have been more suitable for the use case I had in mind but I went ahead and trained a 19-way classifier with very strong results out of the box (82.56% accuracy), considering that there was a huge imbalance in the number of documents per topic, the number of classes (19 instead of just positive/negative) and I used most of the fastai default settings. The resulting errors made by the classifier were reasonable misclassifications due to overlapping subject matters.
What’s so amazing is that the fastai library makes it so easy to get quick results. There were frequent changes to the library in the past week as I was working on this but the actual training of the model was pretty straightforward once the library updates settled, with only a small amount of digging into the source code required to understand what was going on.
I will be presenting my results and how I used fastai’s ULMFiT this Wednesday at the National University of Singapore’s School of Computing Project Showcase (I’ve been participating in a deep learning study group there). Here’s the poster I’ve prepared for it. Will also put up a more detailed Medium post after I run a few more experiments.
I look forward to seeing more of everyone’s impressive work!
Confusion matrix
Sample judgment page

28 Likes
Hi All, used another problem from Cancer Genomics domain – Cancer Type Classification using Gene Expression data – this is my subject matter hence almost the same topic for all of my work  This time, peaked a bit at the structured data documentation and did not convert the data into images (although I am sure we can represent this data as such). Overall accuracy is 93.9%, tiny bit better than the recent paper that addressed this problem.
This time, peaked a bit at the structured data documentation and did not convert the data into images (although I am sure we can represent this data as such). Overall accuracy is 93.9%, tiny bit better than the recent paper that addressed this problem.
Thanks!
14 Likes
Yeah. Got it Thanks! 
Hi everyone.
I made a wolf detector app, that can tell if a wolf like animal is a wolf or not.
http://wolf-detector.herokuapp.com/
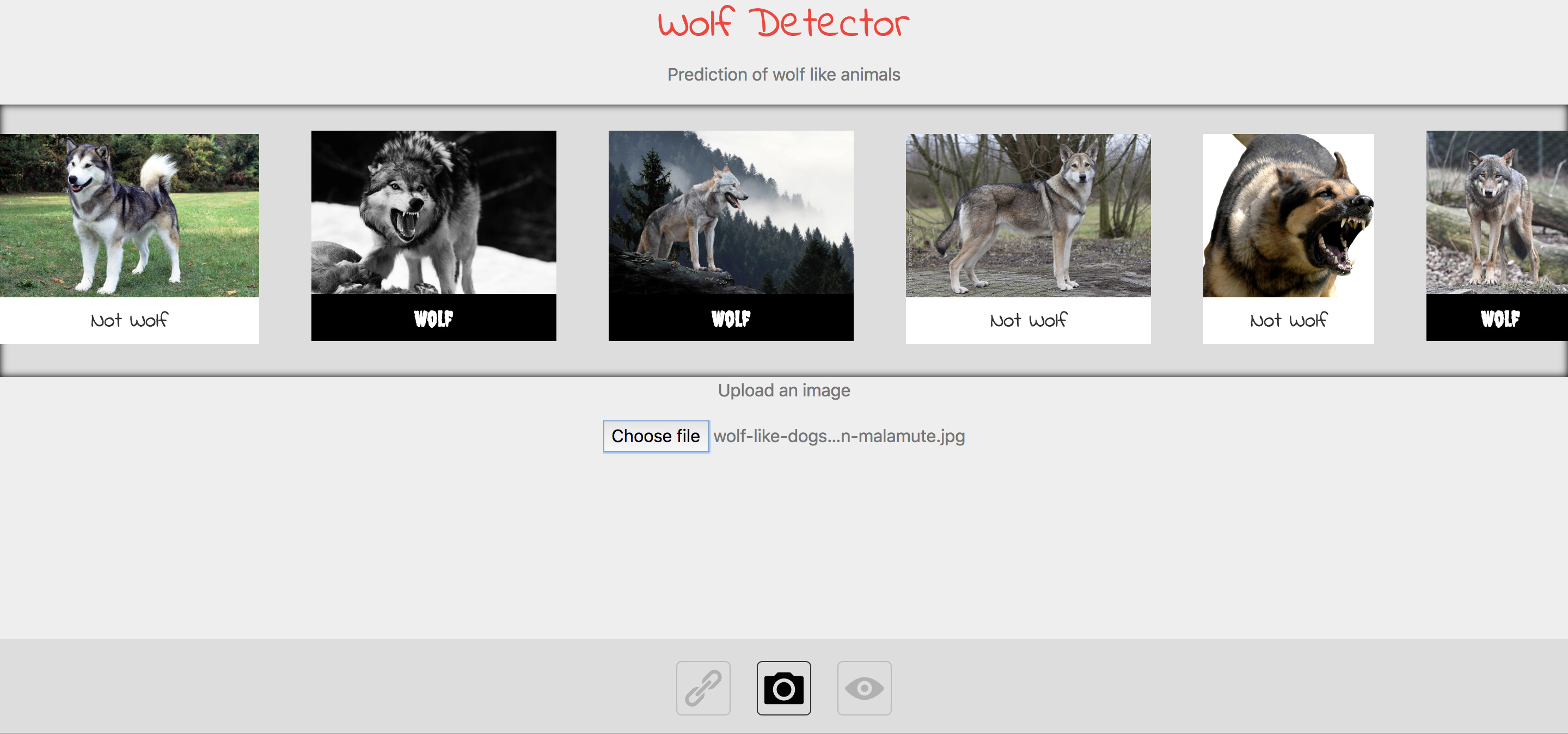
I used 5k images of different wolves and 5k images consisting of non wolf images.
The non-wolf images contain a uniform distribution of all non-extinkt dog breeds and some wildlife such as bear, deer, foxes, raccoons etc to help eliminate background bias.
4 Likes
Are the images 4 channel??
Hi everyone.
Here is my toy app to detect what you are drinking: https://blazys.com/imageclass/
If you use your smartphone you can take picture and test it on the fly.
Achieved around 90% accuracy on resnet50 with about 1.5k Google images.

Here is my github repository with scripts to make it work on your own linux server.
4 Likes
Dragonborns vs Tieflings
My son’s favorite activity since he started high school a few months ago is his afterschool board game club, and his favorite game is a Dungeons and Dragons campaign they play at the club. I sometimes get to hear of funny and heroic acts or complex strategies when he returns home late at night. Although the story telling is engaging, I don’t understand much of the subtle character details, their personalities, and abilities. It turns out, until two weeks ago I couldn’t even tell an Orc from a Goblin most of the time (Orcs are bigger, and Goblins are sometimes green…) or a Dragonborn from a Tiefling; I didn’t even know what a Tiefling was.
The weekend after the second fastai lecture, I became good at telling Tieflings apart from other races. Dragonborns, at advanced levels, can get wings and start to look a lot like Dragons, but, they are much smaller, they stand on two legs, they wear human-like clothes and use weapons in a human way; Dragons on the other hand are huge and very wise, think of the dragon in the Hobbit. To make things more complicated, Halflings still really look like Humans to me, but they tend to be merry and small, though reasonably easy to tell apart from Dwarfs. Since all of these creatures were invented by creative minds, their exact characteristics differ a lot more in the wild than the characteristics of well-defined cat or dog breeds, so the weekend project became an adventure involving data collection, hacking minor tools (sha1sum, FileDeleter mods), and help from my expert son. Here is a neural net that is better than I am at telling the D&D character race from an image:
https://dungeons-and-dragons-race.now.sh
My vacation pictures suggest I’m a Halfling, but my son managed to change his expression enough to pass as a dragon!
4 Likes
Update:
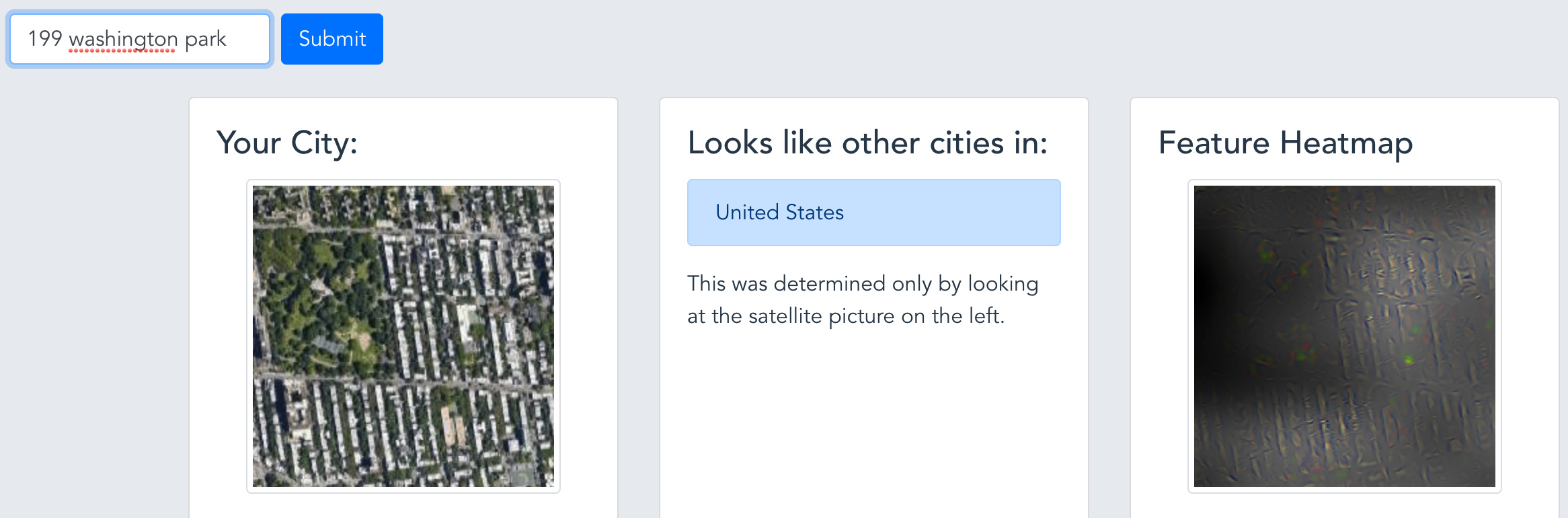
Lots of the feedback I had from the satellite app recognizing the city from the satellite image revolved around the same question: “what is it looking at in the image of my neighborhood that makes it look like it is from my country?”
I tried to implement a couple of interpretation methods I found linked on the forums (see further discussion in this thread).
The results are a little mixed, but I went ahead and added the feature to the app; let me know what you think:
yourcityfrom.space
Example output - you can see here that it avoids the parks and is very interested in the shape of the blocks:
16 Likes
I tried a similar approach with the dataset from Freesound General-Purpose Audio Tagging Challenge(https://www.kaggle.com/c/freesound-audio-tagging) using the data preparation script from AudioNet(https://github.com/vishnu-ks/AudioNet), but my results were not good on all 41 classes (17% accuracy). Could you please share your notebook?
2 Likes