Hi Yijin, nice post on your blog. Very readable. I was lucky enough to get 1st in 4 of the 8 tasks in this challenge (2nd overall). There are a couple of ‘competition tricks’ involved beyond network training. Perform image hashing to identify dupes. Then 1) use it to remove duplicates from training, 2) use it to obtain ground truths where test images are in the train set. Then you can use inter-task findings. A model trained to classify damage levels may also be useful when used in concert with a model trained specifically to check if there was any damage at all. Similarly, a model trained to detect collapsed structures may also be useful to classify moderate or heavy damage. The result comms I have from PeerHub said “The dataset used in this challenge is a Beta version, which contains some wrong labels and duplications. It will be further cleaned and released in the mid of April [2019].” So this may explain your not being able to reach the previous results. I’ll message you the hyper params used for task 1 which you blogged about.
Thanks for your comment : )
That’s amazing! Well done!
Those are indeed very useful tips and tricks. In my quick runs and data cleaning, I did notice some duplicates that I removed, but did not go any further than simple checks by eye (using the fastai2 ImageClassifierCleaner). And I did not think about checking file hashes – will keep this tip in mind for future data checks!
; )
Did you combine any of the tasks into multi-label classification? I was wondering whether that will add further useful info/data for model training.
I only found out about their dataset release after I had done my fastai2 quick-explore. Might circle back to look at the cleaned and released dataset, and the rest of the eight tasks, if/when I have some time again.
Thanks.
Yijin
Anyone knows the former Swedish car manufacturer “Saab” ?
I have implemented a classifier for these model:
9-3, 9-5, 9000, 900

and finally managed to run it on mybinder via voila:
If you are interested in the repository:
voila code: https://github.com/we-make-ai/saab-model-classifier-voila
notebook for creating the model: https://github.com/we-make-ai/saab-model-classifier
Hello, Czech study group here. So far, we have deployed the following models:
- Karol Pal trained “plastic bag or jellyfish?” classifier https://plastic-jelly.westeurope.cloudapp.azure.com/
- Vlasta Martinek trained Cyberpunk or Steampunk? classifier ( web , GitHub )
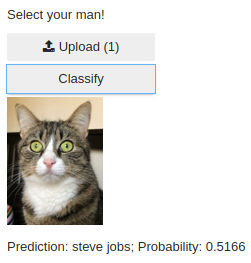
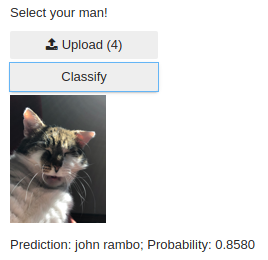
- Petr Simecek (me) trained Steve Jobs vs Rambo classifier ( GitHub )
- Zdenek Hruby trained a classifier of architectural styles (web, GitHub)
I personally really enjoyed using an app from my cell phone (i.e. taking the photo instead of uploading) and making faces to my Jobs vs. Rambo classifier. I also tested other kind of pictures (see below). Currently, I am going to use Google Photos API and classify all my photos there.
I used the bear classifier code nearly one-to-one to create a wild garlic vs lily-of-the-valley classifier (getting Binder to run the app was not easy but the forums were helpful).
Both plants are very common in Germany.
Wild garlic (German: Bärlauch) is a plant whose leaves are used for making tasty soups and pestos and Lily-of-the-valley (German: Maiglöckchen) is a very very similar looking plant that is highly poisonous!
Enthusiastic visitors to Germany who want to try wild garlic recipes need to be very careful while picking these leaves! This app can help 
Jokes apart, I got 86% accuracy when I used the defaults (150 images of each class, standard transforms, just like the bear classifier). Over the next couple of days, I might look more into improving the model.
This is very cool. Do you have a notebok for how you set it up? I would love to test it out on basketball jumps.
I wrote a callback to W&B to compare and monitor models (took me several months already!).
The goal is for it to be easy to use by just adding WandbCallback to your learner and have it log all metrics, parameters you used in every function, upload model, monitor computer resources, etc…
This was a side project as I was playing with fastai2 to try to make my own colorizer but it became much larger than intended and I still see room for improvement.
You can find more details in my full post.
Hello Everyone,
I have written an article on how to do data-augmentation on audio files in python with help of librosa library.
Please do let me know your reviews and please do share.
Thanks
My first use of fastai v2 was to participate in a ICLR 2020 (International Conference on Learning Representations) conference challenge on Computer Vision for Agriculture https://www.cv4gc.org/cv4a2020/#wheat classifying types of crop disease.
I achieved 3rd out of 300+ using fastai v2 pretty much straight out of the box except for hooking in an external senet154 model from the excellent ross wightman’s model zoo. It was interesting in that the best performing image size was very large at 570px.
If you’re interested in Pytorch3D you should check out keops which is really great for working with large point clouds.
Also this just occurred to me but could be interesting. A few years ago someone made an interesting repo doing style transfer with a Wasserstein metric (as opposed to Gram matrix or other techniques) which had some interesting results. To actually do this, he had to assume the tensors he was comparing came from a multivariate Gaussian distribution in order to get a closed form solution.
Nowadays there’s geomloss which uses Keops to implement Sinkhorn divergences which serves as a drop in replacement for Wasserstein distances without making a Gaussian assumption. It could be interesting to see what style transfer looks like with Sinkhorn divergences.
The Sinkhorn Divergence is an interesting topic, I have read in the past this paper about it Learning Generative Models with Sinkhorn Divergences they had pretty good results proving that this divergence interpolates between classical optimal transport OT and Energy distance/Maximum Mean Discrepancy MMD losses. I will have a better look at GeomLoss. Thanks
Here is an attempt at Neural Style Transfer from first principles.
I am setting up an optimization loop manually using all the lower level primitives in PyTorch.
Was a great educational experience for me.
Update: Wrote a blog post about how this works. Here is the link.
Together with @lesscomfortable we built a real time mask detector. It is a two step pipeline, with a pre-trained face detector followed by a mask-wearing classifier trained with fastai2.
We think this might help policy makers to measure compliance and enforce #masks4all.
Demo video: https://player.vimeo.com/video/410577283

And here the second (notebook too)!
I played around with the Plant Pathology Kaggle competition as an excuse to perfection my understanding of some fastai functionality in Computer Vision.
I explored the DataBlock API, custom Callbacks, Progressive Resizing, Label Smoothing, and TTA.
Enjoy!
Dear @muellerzr and @lgvaz I finally started play around with Style Transfer and I was reproducing the code in this repository as you recommend. https://github.com/muellerzr/Practical-Deep-Learning-for-Coders-2.0/blob/master/Computer%20Vision/05_Style_Transfer.ipynb
I got this error when I did the
learn.fit_one_cycle(1, 1e-3)
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-48-486c2b8b9d58> in <module>
----> 1 learn.fit_one_cycle(1, 1e-3)
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
110 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
111 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 112 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
113
114 # Cell
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
193 try:
194 self.epoch=epoch; self('begin_epoch')
--> 195 self._do_epoch_train()
196 self._do_epoch_validate()
197 except CancelEpochException: self('after_cancel_epoch')
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/learner.py in _do_epoch_train(self)
166 try:
167 self.dl = self.dls.train; self('begin_train')
--> 168 self.all_batches()
169 except CancelTrainException: self('after_cancel_train')
170 finally: self('after_train')
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/learner.py in all_batches(self)
144 def all_batches(self):
145 self.n_iter = len(self.dl)
--> 146 for o in enumerate(self.dl): self.one_batch(*o)
147
148 def one_batch(self, i, b):
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/load.py in __iter__(self)
95 self.randomize()
96 self.before_iter()
---> 97 for b in _loaders[self.fake_l.num_workers==0](self.fake_l):
98 if self.device is not None: b = to_device(b, self.device)
99 yield self.after_batch(b)
/opt/conda/envs/fastai/lib/python3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)
343
344 def __next__(self):
--> 345 data = self._next_data()
346 self._num_yielded += 1
347 if self._dataset_kind == _DatasetKind.Iterable and \
/opt/conda/envs/fastai/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)
854 else:
855 del self._task_info[idx]
--> 856 return self._process_data(data)
857
858 def _try_put_index(self):
/opt/conda/envs/fastai/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _process_data(self, data)
879 self._try_put_index()
880 if isinstance(data, ExceptionWrapper):
--> 881 data.reraise()
882 return data
883
/opt/conda/envs/fastai/lib/python3.7/site-packages/torch/_utils.py in reraise(self)
392 # (https://bugs.python.org/issue2651), so we work around it.
393 msg = KeyErrorMessage(msg)
--> 394 raise self.exc_type(msg)
OSError: Caught OSError in DataLoader worker process 2.
Original Traceback (most recent call last):
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop
data = fetcher.fetch(index)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 34, in fetch
data = next(self.dataset_iter)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/load.py", line 106, in create_batches
yield from map(self.do_batch, self.chunkify(res))
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/utils.py", line 271, in chunked
res = list(itertools.islice(it, cs))
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/load.py", line 119, in do_item
try: return self.after_item(self.create_item(s))
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/load.py", line 125, in create_item
def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py", line 287, in __getitem__
res = tuple([tl[it] for tl in self.tls])
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py", line 287, in <listcomp>
res = tuple([tl[it] for tl in self.tls])
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py", line 264, in __getitem__
return self._after_item(res) if is_indexer(idx) else res.map(self._after_item)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py", line 227, in _after_item
def _after_item(self, o): return self.tfms(o)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py", line 185, in __call__
def __call__(self, o): return compose_tfms(o, tfms=self.fs, split_idx=self.split_idx)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py", line 138, in compose_tfms
x = f(x, **kwargs)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py", line 72, in __call__
def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py", line 82, in _call
return self._do_call(getattr(self, fn), x, **kwargs)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py", line 86, in _do_call
return x if f is None else retain_type(f(x, **kwargs), x, f.returns_none(x))
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/dispatch.py", line 98, in __call__
return f(*args, **kwargs)
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/vision/core.py", line 98, in create
return cls(load_image(fn, **merge(cls._open_args, kwargs)))
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/vision/core.py", line 75, in load_image
im.load()
File "/opt/conda/envs/fastai/lib/python3.7/site-packages/PIL/ImageFile.py", line 247, in load
"(%d bytes not processed)" % len(b)
**OSError: image file is truncated (43 bytes not processed)**
Maybe I could ask this question in another topic thread if this could be a common question?!
OSError: image file is truncated (43 bytes not processed)
I was able to achieve some results anyway


looking also at these threads https://github.com/eriklindernoren/PyTorch-YOLOv3/issues/162
Big thanks to @oguiza for some debugging help, here is an article on speeding up fastai2 tabular with NumPy. I was able to get about a 40% boost in speed during training! Article
- Note: bits like
show_batchetc don’t work, but this was a pure “get it to work”
hello all !
I am working on a subreddit flair detector, where in user input the link of the post and and with the post content the model predicts the flair of the post, I wanted to deploy my app on heroku for which i need the fastai library without the CUDA-GPU dependencies, how can i do that !?
or is there a way to
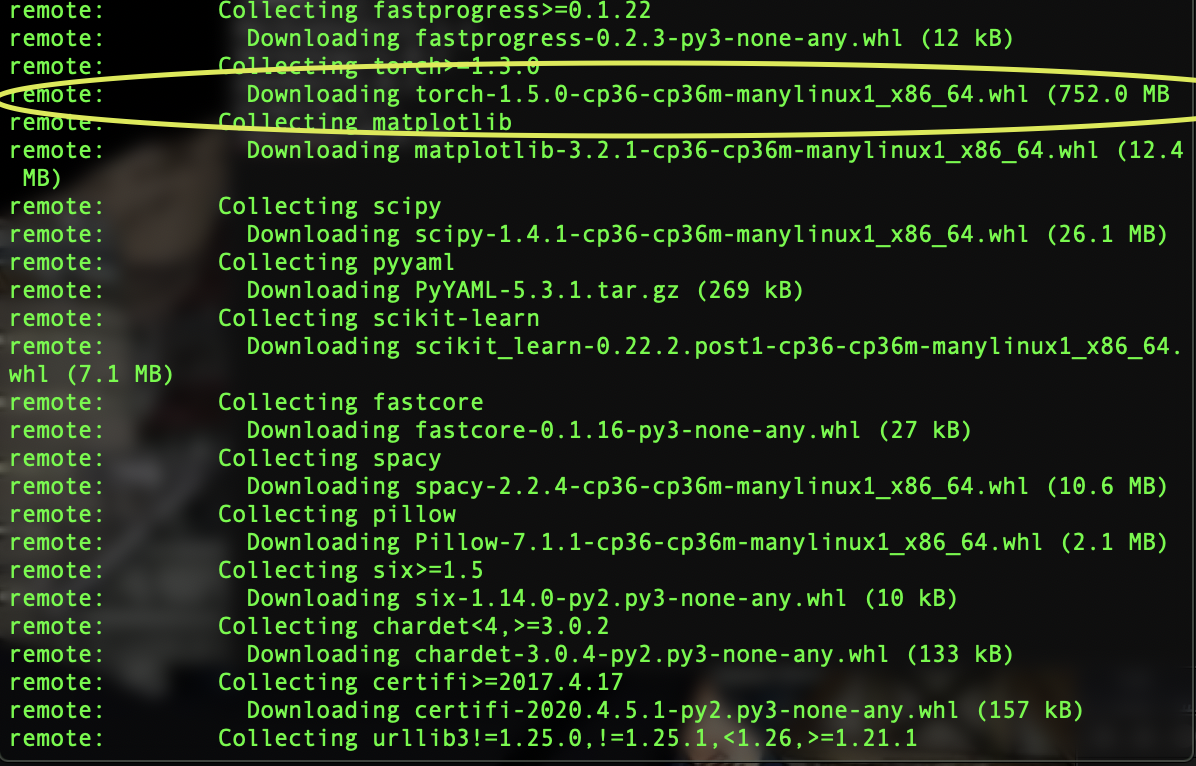
reduce the size of the file, highlighted above!?
heroku gives a limited size of 500 MB for the web application
How come this is heavy?
What are you packaging inside it exactly?
im trying to deploy a model on heroku and it requires a requirement.txt file
here’s what my requirements.txt file contains:
Flask==1.1.2
itsdangerous==1.1.0
MarkupSafe==1.1.1
Werkzeug==1.0.1
pandas==1.0.3
praw==6.5.1
starlette==0.12.0
uvicorn==0.7.1
Jinja2==2.11.1
gunicorn==20.0.4
python-multipart==0.0.5
fastai2
it is list of the libraries which are neede to be installed on server side, and probably the file belongs to the fastai2