Wait, am I reading this right?
Does pytorch alone account for 750 MB?
Recently, a new competition started, the PANDA challenge.
I wrote a starter kernel over here in fastai2. It scores 0.67 now (highest scoring kernel right now):
https://www.kaggle.com/tanlikesmath/prostate-cancer-grading-intro-fastai2-starter
Please upvote the kernel if you found it helpful and informative! 
Also, I had a precursor kernel here.
Hope these resources are helpful!
13 Likes
@ilovescience Great notebook! Very informative! Was looking into this competitions myself and your notebook is very useful!
I have a couple of questions though and hope you can help me out with them:
-
I have read in multiple kaggler approaches about ‘seeding everything’, is this mainly for reproducibility or is there any other reason? Also does Fastai library have a way to seed all of these in an easier way?
-
How did you go about choosing SE-ResNext as your model? Is there a reason or intuition behind this? Admittedly never heard about this architecture until reading your notebook.
-
Could you explain the
m.children()part of the code and reason for such a model cut?
-
Finally, in terms of the gap between the training and validation plot which you addressed this in your notebook as well. Does this indicate that the model hasn’t converged yet and needs to be either trained longer or on a bigger architecture?

Thanks in advance! ![]()
1 Like
I had a go at using voila/binder to deploy a cloud (in the sky) classifier: https://mybinder.org/v2/gh/solpaul/cloud_voila/master?filepath=%2Fvoila%2Frender%2Fcloud_classifier.ipynb. ipywidgets + Voila is great, a fantastic way to build something quickly, even works quite well on a mobile device (upload button gives the option to take a photo, although displaying a high resolution seems to take longer). I’ll definitely use it again, but I had a slight issue with binder.
The link above (copied from the binder setup page) starts up the app ok, but it then goes to the wrong url resulting in a 404 error. If I then delete “/tree” from the middle of the url it then correctly goes to the voila app (also achieved by clicking on the Jupyter icon, navigating to the notebook, and then clicking the Voila button). I double checked that I followed the instructions properly so not too sure what’s going on.
For training I found that Bing search images were very poor but I found a dataset with 2.5k labelled images of clouds that were used in this paper: https://www.researchgate.net/publication/326873190_CloudNet_Ground-Based_Cloud_Classification_With_Deep_Convolutional_Neural_Network. Unless I’m misreading the paper, their accuracy was far higher than I was able to achieve by fine tuning a cnn_learner, even after a lot of playing around with the parameters. The architecture and training parameters in the paper are reasonably simple so I’m going to try to recreate it to see if I can reproduce their results.
1 Like
The past few days I tried to find an easy and cheap way to deploy my models as a rest api. I tried different providers and finally came up with a solution. For 5 $ per month you can host 2-3 models and the performance should be good enough for side projects and playing around :).
https://floleuerer.github.io/2020/04/26/deploy-digitalocean.html
6 Likes
Thank you for your positive feedback. I am glad that people found it helpful
-
Yes it is mainly for reproducibility and also to better compare different runs. If you don’t set the seed, you are not sure if the model did better because of improvements you made, or just because of randomness. fastai2 does have the
set_seedfunction (which I just discovered yesterday) but I haven’t tried it out yet. -
I have seen SE-ResNext50 (and it’s larger model Se-ResNext101) being used commonly in Kaggle to get good results, or even as part of their winning ensembles (ex: here). It’s slowly becoming a new favorite of mine apart from ResNet. I find it easier to train than EfficientNets actually, as EfficientNets are a lot more finicky and sensitive to hyperparameter changes. Most ResNet training tricks we learn in this course and discussed in the literature work relatively well for SE-ResNext models, but not for EfficientNet models (in my personal experience).
-
The model itself is a PyTorch
nn.Module, andm.children()returns the submodules (i.e. the layers) that are part of the modelnn.Module. It’s standard PyTorch functionality. -
I would say that it doesn’t matter if there is a gap between training and validation loss. Only that they are decreasing. Not all models will perform as well on the validation set as it is doing on the train set, but as long as the validation loss is decreasing and not increasing, then the model is training and we can continue. You can see that when the model is unfrozen and training, the validation loss barely changes so I don’t really train the unfrozen model much further.
I hope these answers help. Let me know if you have any further questions!
3 Likes
@marii This looks so coo! Did you have a link Molly?
Glad you decided not to call it fast food
2 Likes
To the initial mask-wearing detector, we added a social distancing monitor
Demo video: https://vimeo.com/412427948

13 Likes
Introducing blurr (https://github.com/ohmeow/blurr) … an extensible integration of huggingface transformer models with fastai v2.
Built using nbdev, the library will enable fastai developers to build transformer based sequence classification, token classification, question/answer, LM, and/or summarization models with fastai. Right now, it just supports sequence classification and question/answering out of the box.
Over the past few months, I’ve been able to get all such models working, more or less, in v1. But now with the advent of v2, and the goodness it brings in terms of features like type dispatched methods and the DataBlock API, I think I’ve finally figured out how to bring all those bits together into something useful as a package.
I tried to build something that doesn’t try to do too much … or too little, in order for developers to make as much use of it as possible. Whether I’ve found that sweet spot or not is I guess up to whoever ends up using it.
-wg
11 Likes
Great work … smooth results.
Do you guys have a repo for this work?
I’m not much of a vision guy myself … but I work with several students on a High School robotics team who are building object detection based models and they would love to see how y’all built this and also what kind of hardware you’re running on.
This isn’t a project fastai project but thought someone might find it useful (and I did create it to explore the lessons in the class).
Here’s a dataset of 649 short wav files, from famous (and not so famous) US movies. It comes with a CSV file detailing:
- movie title
- year produced
- file name (to match with wav file)
- speaker
- text from the wav
I filtered out the clips with more than one speaker. Also, the speaker and quote text is scrapped from the same site I used for the clips. It’s possible there’s mistakes. I appended the movie years.
A warning, quite a few of these are what I’d mark NSFW. If you get offended by foul language, or inappropriate comments, this probably isn’t for you.
3 Likes
Hi all, this may be slightly off-topic as the library used is not fastai.
Still, both the motivation, the general knowledge and part of the inspiration comes from fast.ai so I feel it is proper to share it here also.
Presenting. Michel A. Renard, a GPT-2 trained Twitter pundit spoof bot.
https://twitter.com/MichelARenard


PROBLEM: In these times, I got really interested in the quality of pundit advice, and read a bit about it. Basically, the prediction level is terrible (and usually worse than a coin toss). This kinda matched with my basic intuition (feeling that most people speaking their minds have close to 0 added value and are just optimizing screen-time).
SOLUTION:
- I created a dataset of Twitter pundit tweets (in particular I focused on my favourites, because they both sounded deep and usually weren’t).
- I used that to fine-tune a GPT-2 model to my satisfaction
- Then I generated and queued enough messages for a 4 year period (assuming tweeting every half hour, which the more prolific seem to do).
- Using Azure functions (super cheap serverless) it randomly decides when to tweet and then does so.
- You can see (and follow ;D) here:
https://twitter.com/MichelARenard
P.S. Michel is the first name of Nostradamus and Renard is french for fox (a riff on foxes and hedgehogs from Tetlocks’ model). The image of my AI pundit is from https://www.thispersondoesnotexist.com/ and the background is the Real Gabinete Português de Leitura and inspired by https://twitter.com/BCredibility
Hope you enjoy and please share any suggestions.
2 Likes
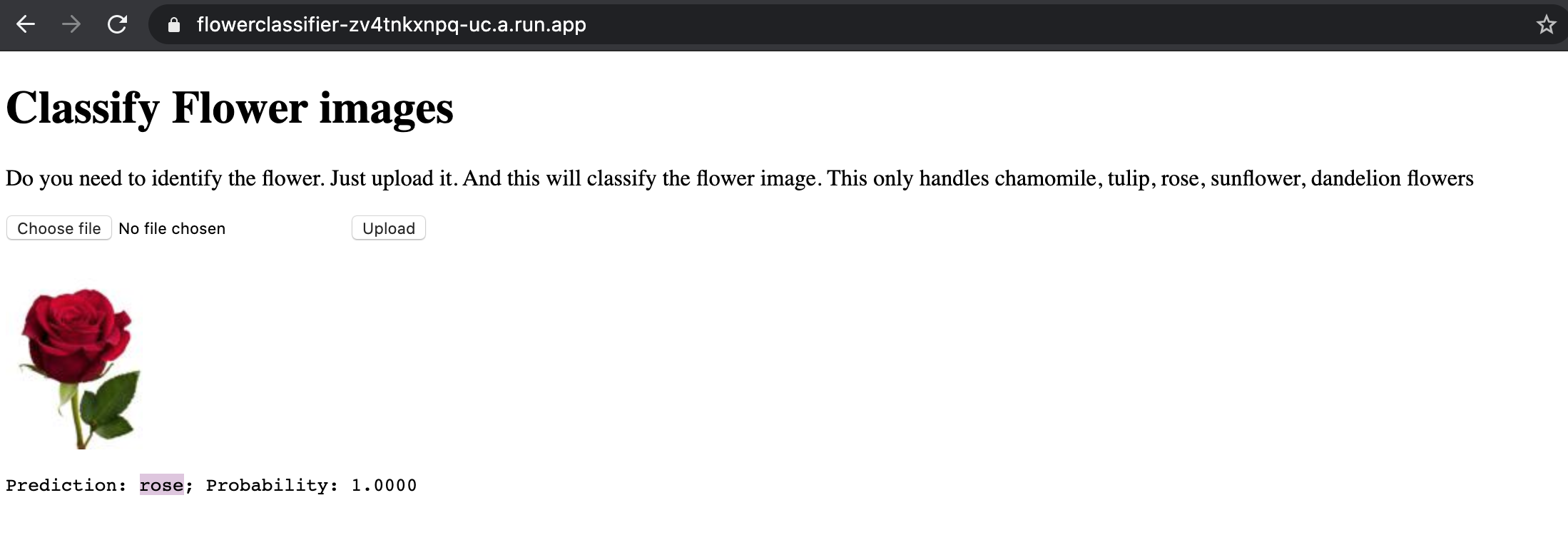
I created an web app to classify flowers using GCP run. Checkout https://flowerclassifier-zv4tnkxnpq-uc.a.run.app/
Git repo https://nik-hil.github.io/2020/05/04/Deploy-flower-classifier-as-web-app-on-GCP-Run.html
3 Likes
After lesson 7, I was curious how much better random forests are at predicting rows where the trees agree versus when they don’t.
I ran a simple experiment: Split the rows of the validation set into quintiles based on preds_std (i.e. the standard deviation of the tree predictions for a given row). Then, for each quintile, calculate the RMSE.
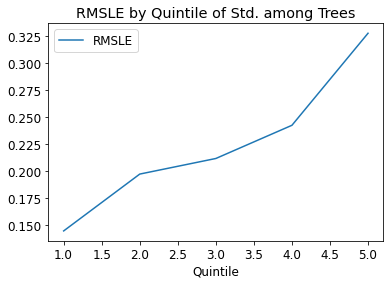
The results, at least on the bulldozer’s dataset, definitely validate that the model performs better on rows where the tree is in agreement. I think the most interesting takeaway is that, even in the lowest quintile, the RMSE is still 0.15 (versus ~0.23 for the whole validation set)
Notably, this means that the tree variance generally overstates the model performance:
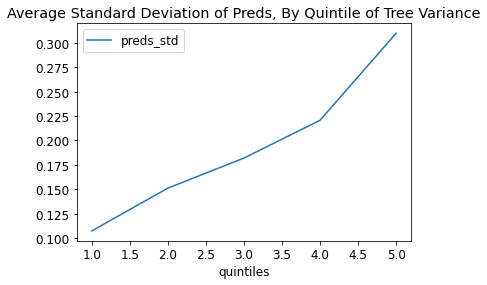
For example, while the most uncertain predictions ended up having an RMSE of 0.15, the tree variance method indicated 0.11
The code behind these charts is simple. You can run it right after preds_std is defined. Running it later on is tricky, since the model variable gets redefined later in the notebook.

Hi all
so I took the challenge to rebuild the MNIST classifier for all images in the MNIST dataset using the MNIST code we used in class and I think I came up with good results and I would like to post it in my blog but I would like some feedback before that if anyone can take a look and let me know if what I did actually makes sense and its correct.
Here is my notebook: https://github.com/victor-vargas2009/FastAI_Experiments/blob/master/nbs/MNIST_Classifier.ipynb
Thanks a lot in advance
1 Like
Done ![]()
See here for more info: blurr - Getting Started
6 Likes
Fastai V2 now running on the Nvidia Jetson Nano!
As the speedy new GPU accelerated image transforms of fastai V2 needs some functions not included in with Nvidia’s stock pytorch wheels, I decided to write up the recipe for rolling your own.
If you want to play with fastai V2 on your jetson nano, check out https://github.com/streicherlouw/fastai2_jetson_nano
15 Likes
A mini project. I created a callback that shows a chart of GPU utilization as you train. I find it useful for debugging and more handy than looking at nvidia-smi in the console. The code is here. Feel free to try it out.
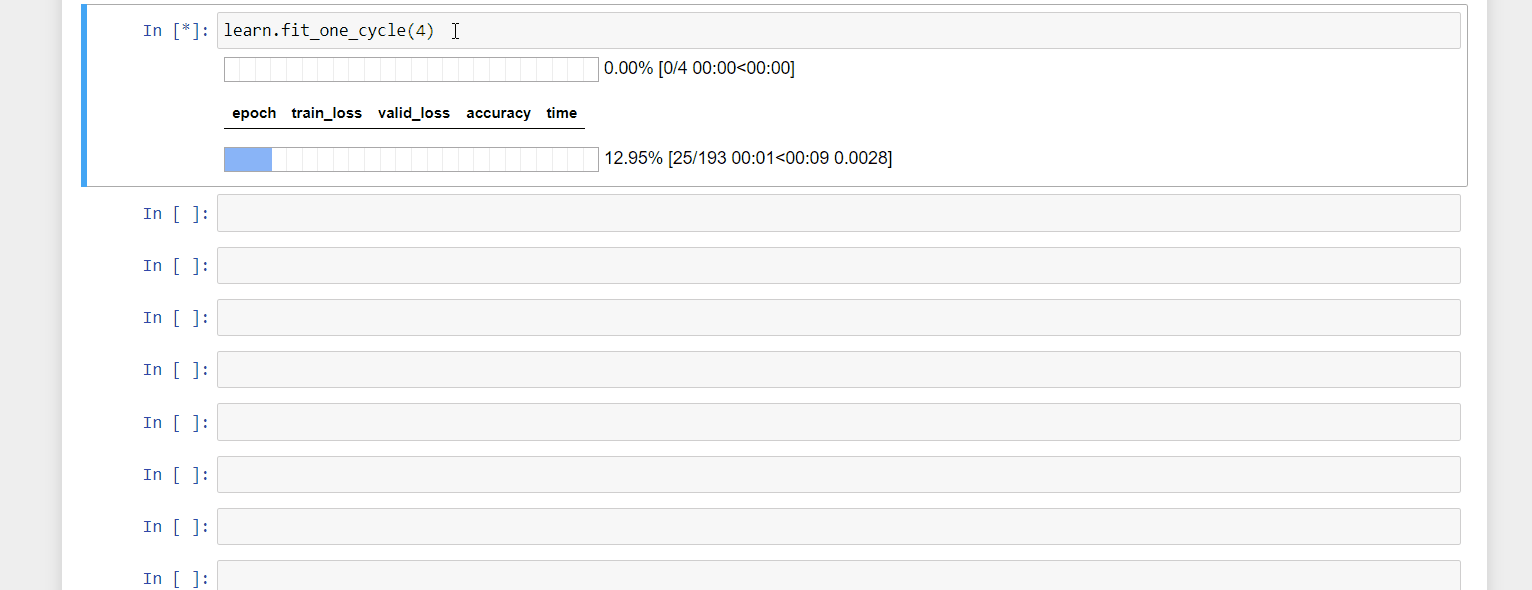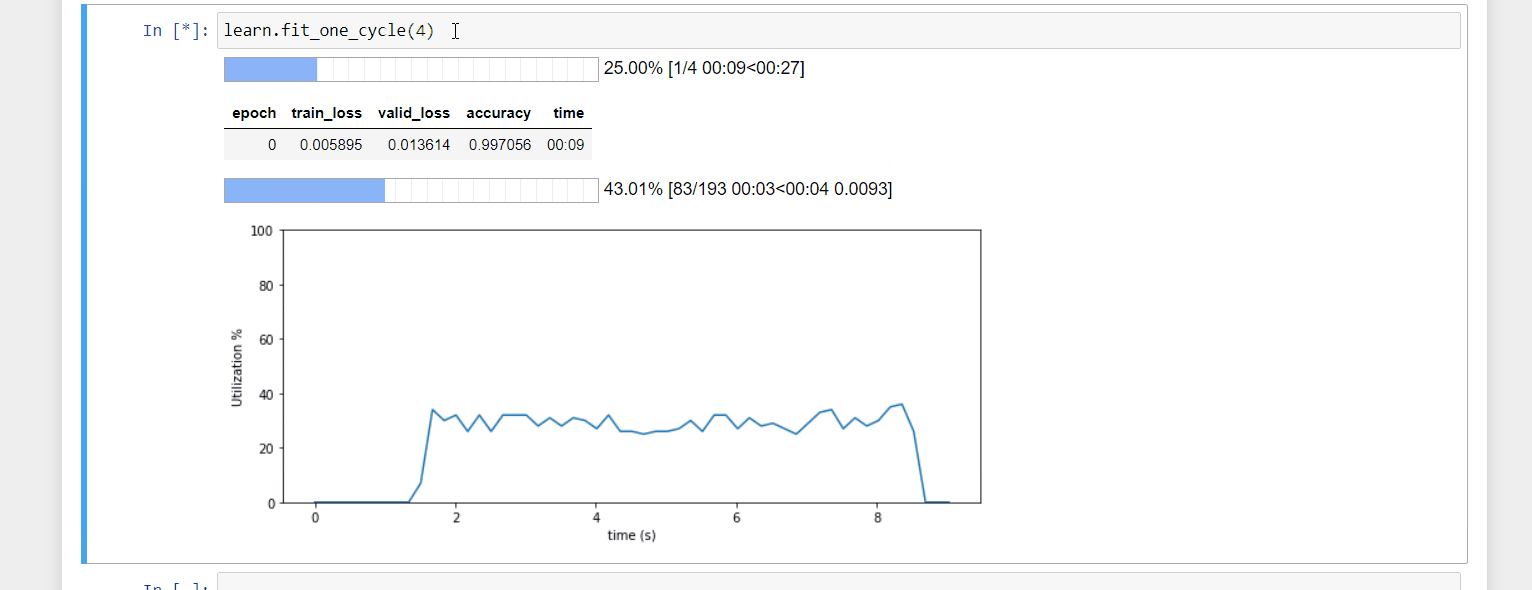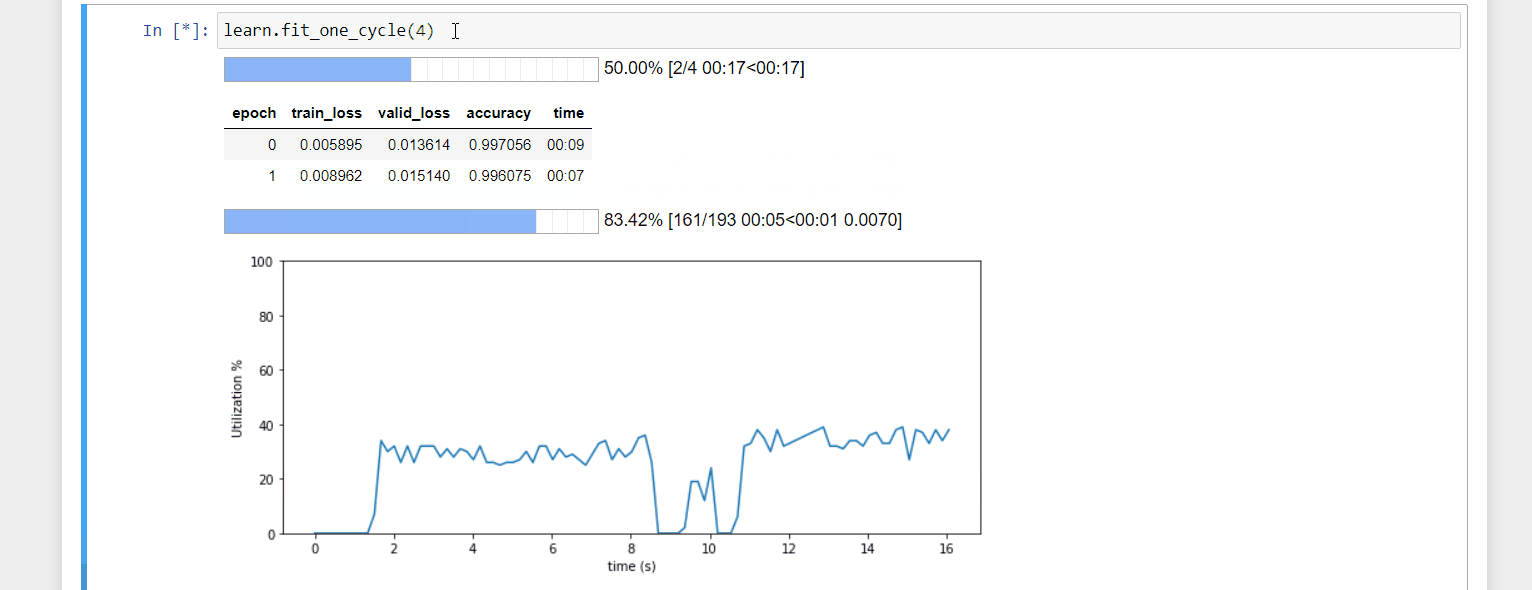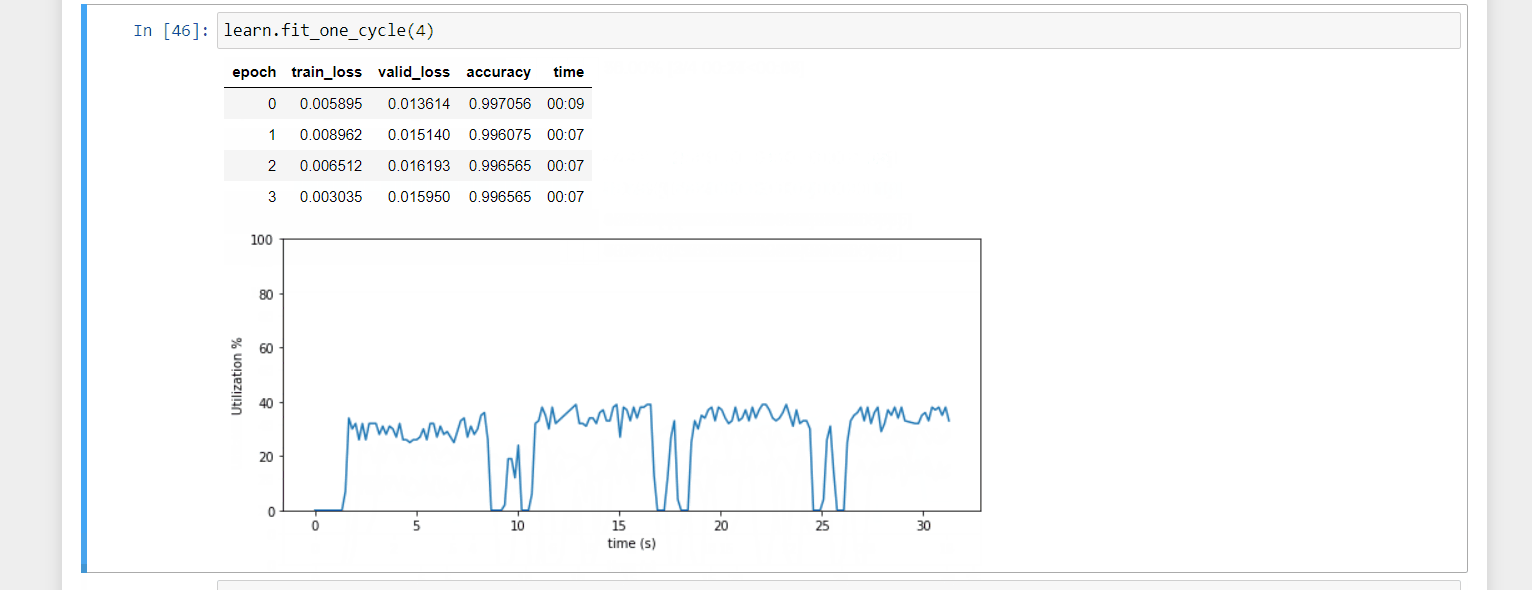
20 Likes
I just finished writing and recording a tutorial on the fastai2 DataLoader, and how to easily incorporate it with NumPy/Tabular data as a simple example. Read more here: DataLoaders in fastai2, Tutorial and Discussion
5 Likes