I suggest you use the already defined torch.nn.functional.softplus function!
I have been using it in my implementation of both the function and the module, and have encountered no issues so far.
Let me know if you need some help with that 
I suggest you use the already defined torch.nn.functional.softplus function!
I have been using it in my implementation of both the function and the module, and have encountered no issues so far.
Let me know if you need some help with that
Hey Less. Thanks for that update. It’s not my implementation though. I found it here - https://github.com/Tensor46/TensorMONK. I prefer my Softplus based implementation better over the baseline function based implementation, but was just curious. Can you open an issue in that repository regarding your findings?
Thanks
Hi @fgfm - thanks, that is exactly what I have been doing already, and it works great.
def forward(self, x):
#inlining this saves 1 second per epoch (V100 GPU) vs having a temp x and then returning x(!)
return x *( torch.tanh(F.softplus(x)))
The new code above was what was not working…was just trying to see if it offered an improvement in computation time ![]()
Thanks again!
@LessW2020 I’m noticing a behavior and I’m curious if you have as well. I’m playing around with Ranger and I am noticing an increase in accuracy if I turn batch normalization off. Specifically this is tabular however, I am curious if you played around with this at all during your experiments? Without the batch normalization as well it seems to overfit less (valid_loss goes up). Thoughts? EG:
W/O batch normalization:
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.216009 | 0.226282 | 0.987378 | 01:56 |
| 1 | 0.212948 | 0.224774 | 0.987181 | 01:57 |
| 2 | 0.212310 | 0.224170 | 0.987682 | 01:56 |
| 3 | 0.210955 | 0.223668 | 0.988217 |
W batch norm:
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.243163 | 0.249636 | 0.977681 | 01:53 |
| 1 | 0.235176 | 0.263560 | 0.981574 | 01:53 |
| 2 | 0.228351 | 0.253624 | 0.983057 | 01:54 |
| 3 | 0.225320 | 1.108701 | 0.984635 |
I know that the accuracy does not change much, however I’m looking more at model behavior 
*Note: It is definitely performing worse and overfitting. Which I find odd, as batchnorm should keep everything in check and yet with a 2 layer tabular model it seems not to be 
Hey all – I really enjoyed reading through this thread. It’s been super fun to see everything develop.
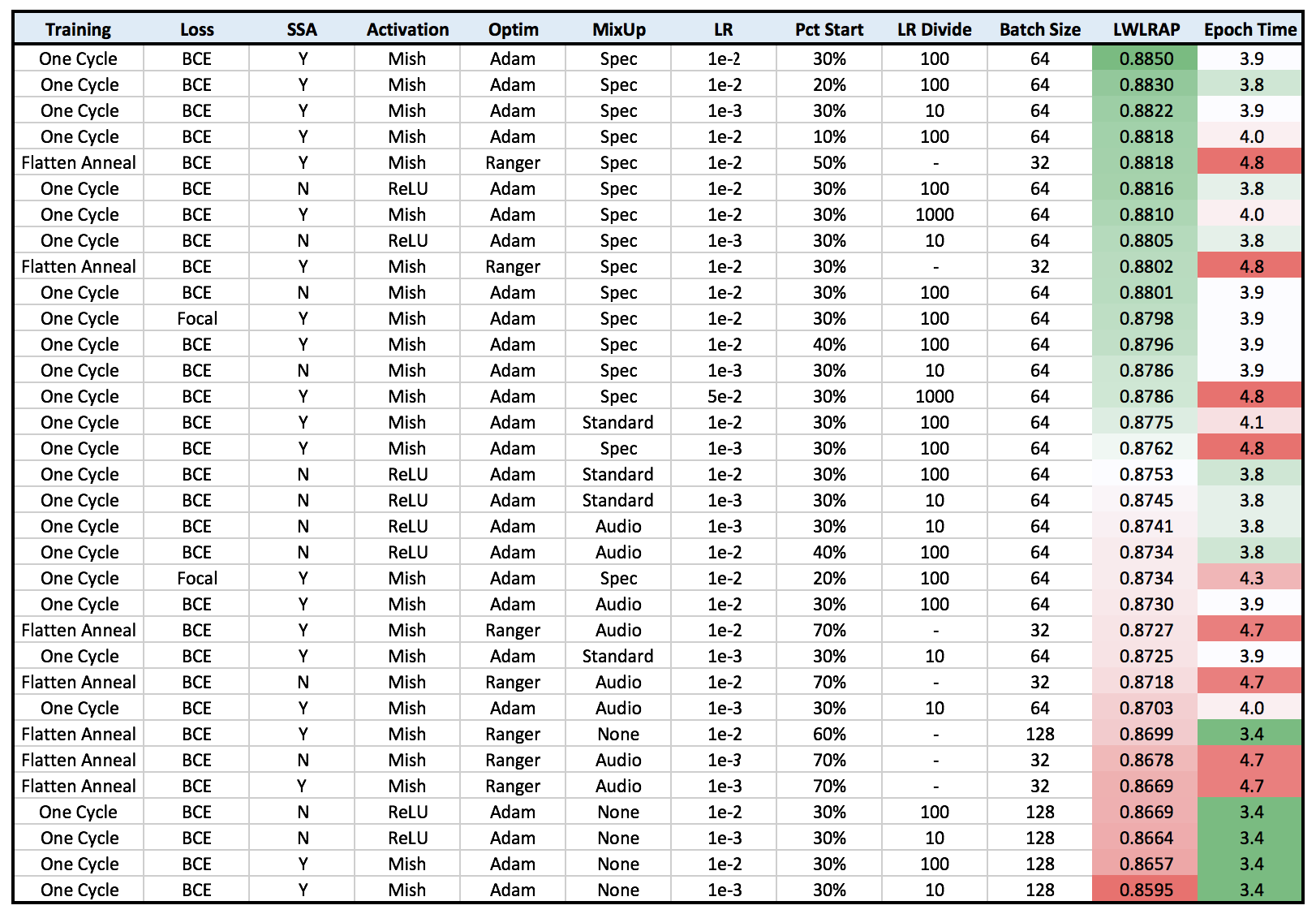
That said, I’m working on a project that uses audio data and I tried out some of your ideas so I figured you’d be interested to see the results. I know it’s not exactly what I’d imagine you want to see, but any information is good information
Architecture: XResNet 34
Data: Classify songs to their appropriate genre (20 in total, 4k spectrograms per class)
Image Size: 128px
Epochs:: 20
Hardware: 1x P4000
My Thoughts
While unfortunately your best Imagenette / Woof model (w/ Ranger and Flatten Anneal) didn’t end up being the best performer, I did get really nice results by using Mish and SSA. One of the best things I noticed about using Mish is that the loss curve is much more smooth and consistent compared to ReLU which should save me a ton of time in the long run (less worry about variance between runs / local minima). There also seems to be a synergistic effect with Mish and SSA, though I’m not quite sure why that might be.
Surprisingly (based on the overall sentiment that MixUp needs a lot of epochs to deliver any boost), MixUp was one of the main determinants in performance, and when I didn’t use it, the model performed the worst.
I’d say the biggest downside of the Flatten Anneal / Ranger combo is that it takes longer to train. But weirdly enough, the training time jump only occurs when MixUp is introduced – so there seems to be some bad synergy there.
But overall I’m super happy with the results and I was able to reduce my error by 15% by trying out everything in this thread – so thank you and please keep up the amazing work 
Hi @zache,
Thanks for all the feedback (and excellent data chart) and very happy to hear that some of our techniques here were of benefit for you!
Definitely appreciate all the feedback as great to see what is working/not working on things beyond Woof/Nette.
There’s more new ideas being tested so may have some new stuff for you to try soon as well.
Thanks again for the feedback!
Less
Wow, that’s very odd. I haven’t tried turning BN off - the only thing I’ve tested is the switch for order of BN vs Mish (i.e. Mish first, then BN).
I wonder if putting running batch norm in there might glean some better insight?
I will try that soon ![]() I’m currently working on preparing a difficult keypoints dataset, as fastai lacks in this (I believe) and I’m making it similar to imageWoof/nette (hopefully Jeremy likes the idea?)
I’m currently working on preparing a difficult keypoints dataset, as fastai lacks in this (I believe) and I’m making it similar to imageWoof/nette (hopefully Jeremy likes the idea?)
A new paper came out yesterday that looks very compelling:
I’ve made a new beta drop of Ranger that uses it instead of RAdam and am testing now. First impressions are that it greatly stabilizes training in the mid-range and beyond where things get a lot more erratic on average without it.
I’m running an 80 epoch right now with it, as they show that this calibration outperforms SGD+Momentum over the long run.
(use the Ranger913A.py file).
You should definitely make a blogpost about this summarizing your findings. Would be awesome. Do you have a repo on this?
@LessW2020 I am trying to run running batch norm as according to this post: Running batch norm tweaks and when it runs update stats I get the following:
--> 24 s = x .sum(dims, keepdim=True)
25 ss = (x*x).sum(dims, keepdim=True)
26 c = self.count.new_tensor(x.numel()/nc)
IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
Which I believe has to due with the fact of how tabular tensors are passed in as two separate entities (cont and cat vars). Where should I go about fixing this?
Super interesting thread and discussion! ![]()
As far as I got everything correct from the previous posts, this was so far the best model setup:
ConvLayer class of fastai v2 dev.)I tried my Squeeze-Excite-XResNet implementation with AdaptiveConcatPool2d with Mish based on the fastai XResNet and got the following results after 5 runs:
0.638, 0.624, 0.668, 0.700, 0.686 → average: 0.663
… so this was not really improving the SimpleSelfAttention approach from the notebook.
Then I combined the MXResNet from LessW2020 with the SE block to get the SEMXResNet ( ![]() ) and got the following results (+ Ranger + SimpleSelfAttention + Flatten Anneal):
) and got the following results (+ Ranger + SimpleSelfAttention + Flatten Anneal):
0.748, 0.748, 0.746, 0.772, 0.718 → average: 0.746
And with BN after the activation:
0.728, 0.768, 0.774, 0.738, 0.752 → average: 0.752
And with AdaptiveConcatPool2d:
0.620, 0.628, 0.684, 0.714, 0.700 → average: 0.669
With the increased parameter count (e.g., SE block and/or double the parameters from the FC head input stage after the AdaptiveConcatPool2d) the 5 epochs are very likely not enough to really compare it to the models with fewer parameters, as it will need more time to train (like mentioned above).
I also have seen the thread from LessW2020 about Res2Net. - Did somebody already tried it in a similar fashion and got some (preliminary) results?
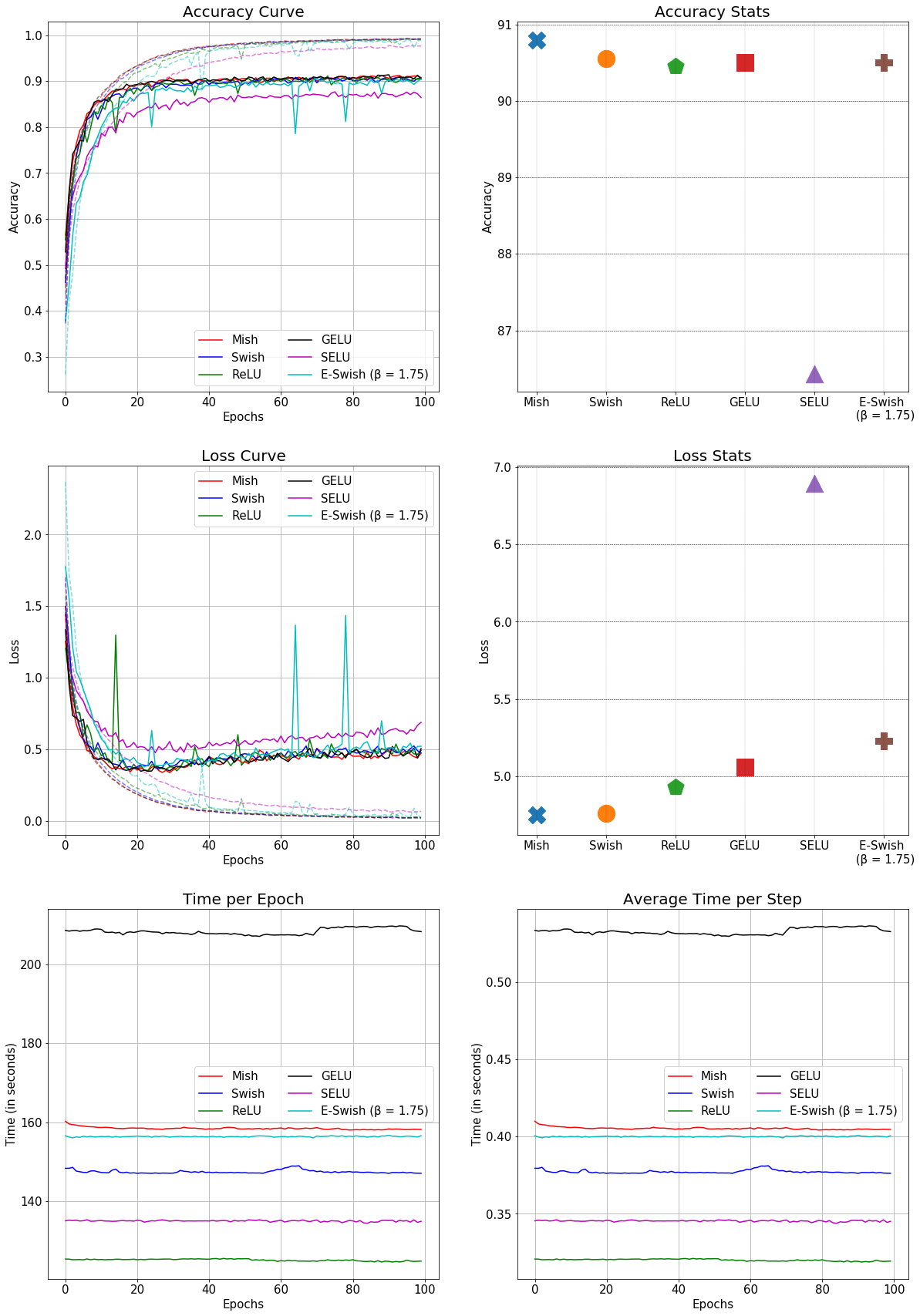
Just completed a thorough benchmark on SE-ResNet-50 on CIFAR-10.
Parameters:
epochs = 100
batch_size = 128
learning_rate = 0.001
Optimizer = Adam
Observation Notes - Mish Loss is extremely stable as compared to others especially when compared to E-Swish and ReLU. Mish is faster than GELU in comparison. Mish also is the only activation function which crossed 91% in the 2 runs while other activation functions went to a max of 90.7%.
Mish highest Test Top-1 Accuracy - 91.248%. SELU performed the worst throughout.
(Please click on the picture to view it in larger aspect)
I think you mixed up the axes labels on the accuracy curve and loss curve graphs. epochs should be x, not y.
Corrected!
Not yet – I was going to wait until after I am finished with the project since this was just a small part of something much bigger. But I’ll definitely share it here when I do!
I just wanna note here as I reran my tabular models and here is one bit I noticed. The increase in accuracy was noticed specifically when I included information via time-based feature engineering. When the paper is published I will be able to share more details, but I definitely notice the change specifically there. In all other instances there was no radical difference. The moment that was introduced accuracy shot from 92% to 97% with negligible error. This I believe is what was missing. I will note that this time-based feature engineering is not like Rossmann. I will try plugging in a Mish activation as I believe that this could shine here.
I would really like some more in depth on this. Are you working on a paper as per what you wrote? If yes, do send the arXiv link, once it’s up.
I am, hence why I can’t say too much on here right now! ![]() But I will definitely send the arXiv once it’s up
But I will definitely send the arXiv once it’s up ![]()
Awesome. Do provide the Mish scores once you have them.