The reasoning for hoping for Mish is I have been thoroughly testing these new optimizer + Mish on a variety of datasets with no changes whatsoever. But with this dataset I saw direct changes using the new optimizer + scheduler. Sadly, the only bit that did not change was Mish in the end  My model was set up with two hidden layers of 1000 and 500. I ran it in three separate areas that I saw various improvements on (with the optimizer and in general) but to no avail Sorry @Diganta! The tabular mystery is still a thing! (because this whole experiment has gotten me re-thinking tabular models as a whole)
My model was set up with two hidden layers of 1000 and 500. I ran it in three separate areas that I saw various improvements on (with the optimizer and in general) but to no avail Sorry @Diganta! The tabular mystery is still a thing! (because this whole experiment has gotten me re-thinking tabular models as a whole)
1 Like
I do agree that tabular models are a mystery of their own. But I would really like to see your progress.
I’ll send you a DM 
1 Like
I’ve been out of the loop here for a bit as I have a lot of consulting work in progress, but @muellerzr happy to see you might have a paper out soon!
Re: tabular data - here’s a recent paper and apparently open source code that may be of great interest:
I want to test it out but too swamped atm.
Also, I wanted to add that I’m having really good results with the Res2Net Plus architecture and the Ranger beta optimizer. I’ll have an article out soon on Res2Net plus, and then the Ranger beta and the paper it’s based on but it trains really well…not fast enough for leaderboards, but excellent for production work.
Hope you guys are doing great!
5 Likes
@LessW2020 very good find! I’ll try it out and report back Hope you are doing well too (and not too too swamped! )
Only bit that concerns me: “Our implementation is memory inefficient and may require a lot of GPU memory to converge”
1 Like

@Diganta Congratulations for your work!
Now it is a fact that Mish activation boosts the accuracy as well as the model stability on SqueezeNet.
I have been following this thread & the imagenette/wolf and was super excited about MXResnet, where Mish also boosted the model.
Do you know if is there any benchmark of EfficientNet replacing the Swish activation for Mish?
Exciting times we are living, you don’t know if current SOTA will survive next week.
Thanks again for keep pushing.
3 Likes
@LessW2020 I’ve been running some trials with Ranger913A over the past few days with EfficientNet-b3 + Mish on Stanford-Cars. Overall I found it matched the accuracy of “vanilla” Ranger but didn’t beat it. It also needed a higher lr (10x) than Ranger and was about 15% slower to run.
If there are 1 or 2 other parameter configurations you feel are worth exploring then I can probably make time to trial them, however in general with Ranger913A and Ranger I’ve found 93.8% to be a hard ceiling with b3, although I have seen 93.9% after adding Mixup.
All results are in the “Ranger913A” notebook here: https://github.com/morganmcg1/stanford-cars
Results
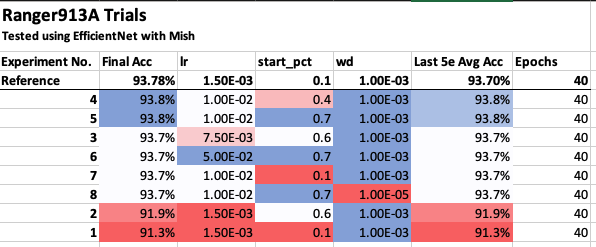
Accuracy, last 10e (full 40e plots in the notebook)
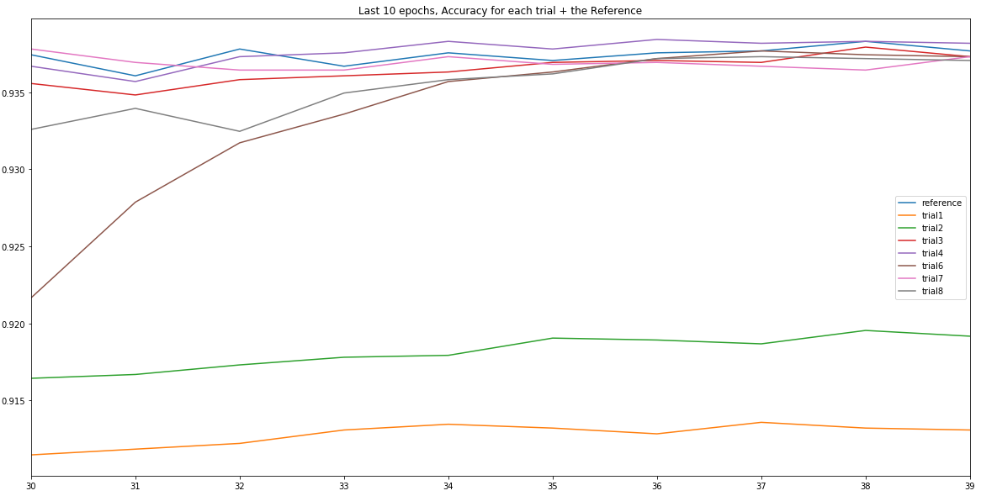
Validation loss, last 10e
@mmauri I have a look at my repo above, and my other results with EfficientNet + Mish + Ranger: [Project] Stanford-Cars with fastai v1
Its not on Imagenette/Imagewoof but I’ve found Mish + Ranger to be super helpful. Also, myself and @ttsantos are working on a PR for the efficientnet_pytorch library to allow you to toggle the activation function between Mish, Swish and Relu…
6 Likes
Hey Marc. Thanks for the appreciation. Yes it demonstrates the consistency and superiority of Mish yes. @morgan here used Mish with Efficient Net and beat the accuracy of the Google’s paper on the Stanford Cars Dataset on the B3 model.
Also for more comparison, I used the B0 model to get scores for various activations on the CIFAR-10 dataset.
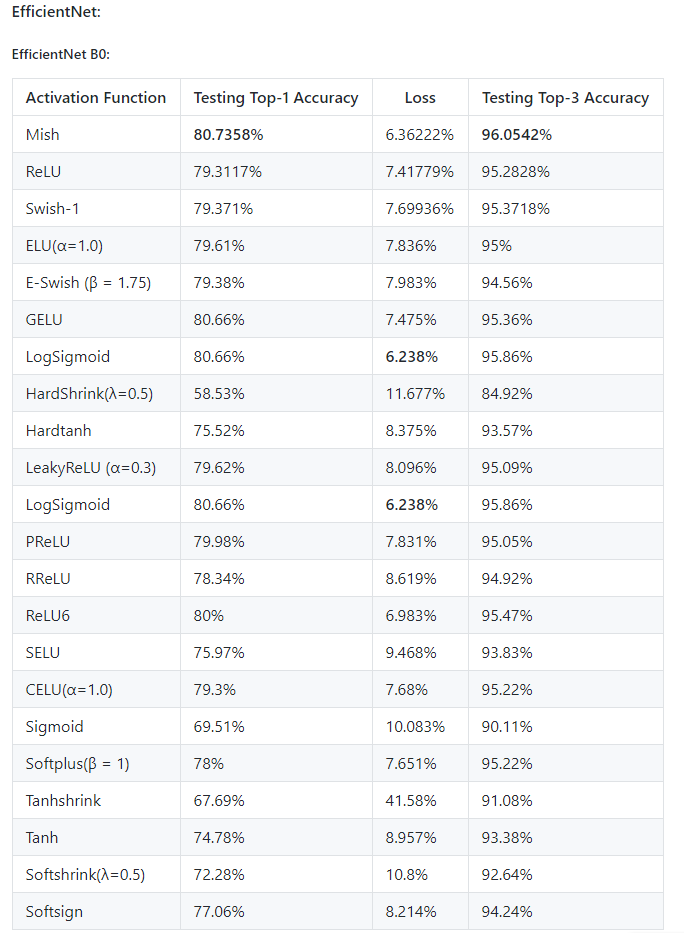
5 Likes
It’s very nice you are doing all those benchmarks and also including statistical significance.
I have two suggestions you could explore:
-
Does Mish beat ReLU when constrained by run time? For example, if 50 epochs with Mish take as long as 80 epochs with ReLU (I just made up numbers here), you could compare those results.
-
Does Mish increase the capacity of a network when replacing ReLU? I’m not sure exactly how you would test that, but I assume that there’s a certain number of epochs after which networks won’t improve their accuracy by much. I assume it’s higher than 50 epochs.
Thanks for all your work!
1 Like
Thanks @Seb. I hadn’t thought about the statistical significance aspect before you posted your results on the earlier run where you stated Mish beats ReLU at a higher statistical significance of P < 0.0001.
Coming to your suggestion, I think the first point is more viable to explore into and I’ll run some tests in the weekend on the same. Regarding the 2nd point which is based on Saturation of Learning/ Peak Threshold of Learning, I think that can be explored but not strictly in terms of scores because I believe there init has a huge role along with the non-linearity. But anyway, I will first run some tests on the first point and observe how Mish performs. Thanks again!
1 Like
EfficientNet-Pytorch Library. Did you mean this one here - GitHub - lukemelas/EfficientNet-PyTorch: A PyTorch implementation of EfficientNet ?
1 Like
Could you sort this by accuracy?
Sure. That won’t be a problem. Will do that by tomorrow. Though essentially, the numbers in bold depict the best value. Thanks for the suggestion!
1 Like
Completed:
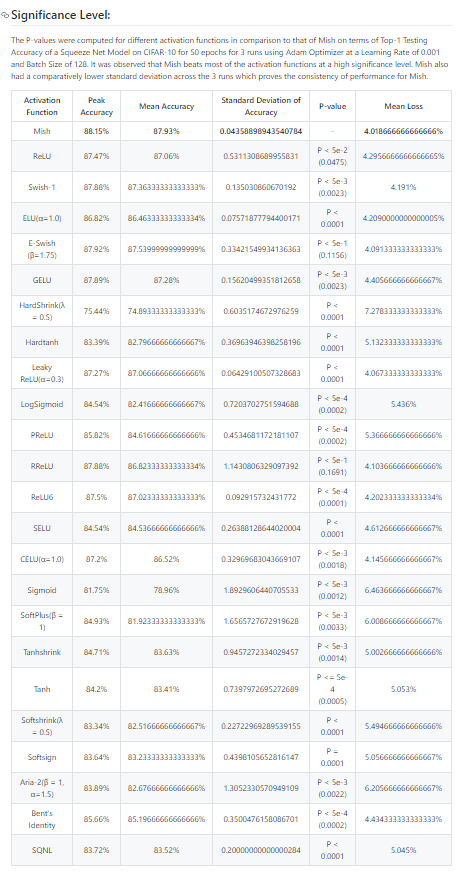
(Please Zoom in to view). Results can also be viewed here - https://github.com/digantamisra98/Mish#significance-level
Mish beats all of the activations in Peak Accuracy, mean accuracy, mean loss and standard deviation of accuracy. Mish beats other activation functions at mostly a significant high level. (The P values are shown in the table)
Also if someone is familiar with keras and LSTMs, please help me in solving this issue - https://github.com/digantamisra98/Mish/issues/13
@Seb I think your second suggestion of whether Mish increases network learning capacity is somewhat demonstrated in this table where Mish was the only one to cross the 88% mark on the Top-1 Accuracy.
@ilovescience do you only want the Efficient Net B0 table to be sorted or all the 70+ benchmark tables in the repository to be sorted? (If it is the latter, then that is gonna take some significant time)
5 Likes
I think just sorting the table in your post (significance level table) is probably fine. That way it will be easier for people compare all the activation functions by looking at your table.
@ilovescience sure will do that.
Can someone put some light/clarity on this. How can I find the domain significance as pointed out by a very experienced professional who provided me feedback on my recent statistical tests.

Updated follow up comment:

I am not exactly getting what he is conveying here, If someone could explain that would be awesome. I guess I need to revisit stats Soon.
@Seb
So far, yes, but you’d have to check if ReLU doesn’t cross 88% with more epochs for example. I think it’s not the easiest query to answer!
Maybe he is talking about practical significance?
Pratical significance depends on your domain, so maybe that’s why he is calling it “domain significance”?
For ML, I’d say a 0.1% difference is practically significant for us, while 0.01% maybe not.
The link above suggests using confidence intervals instead of hypothesis testing. Then everyone can make their own decision on whether the difference is practically significant for their own purpose.
1 Like
I have some additional feedback on your table.
I was a bit surprised that you would get such good p-values after only 3 runs. But I attributed that at first to the possibility that your dataset has less variance than high variance datasets I’ve been working with (Imagenette/woof).
But now that I think about it, I wonder if Mish got lucky; not in terms of Mean accuracy, but in terms of variance. Low variance implies ability to get good p values. But with 3 runs, maybe you got more consistent than normal? Worth running a couple more for Mish to check.
1 Like