Per the paper, Mish outperformed ReLU by 1.67% in their testing (final accuracy) and was tested in 70 different architectures.
I tested against ImageWoof using XResNet50 and a variety of optimizers to try and put Mish through it’s paces and saw improved training curves and accuracy jumps of 1-3.6% merely by dropping in Mish instead of ReLU.
The overhead vs ReLU is minimal (+1 second per epoch) and so far well worth it for the accuracy gains.
I wrote a full article on Mish here:
and have a PyTorch/FastAI drop in (mish.py) and Mish XResNet here:
and here’s the paper link:
Please give Mish a try and see how it performs for you versus ReLU as I think you’ll see a nice win from it.
I was following this paper of Digant for some days and eagerly waiting for someone to implement it. Thanks.
It is changing internal layers of model. You trained whole XResNet50 and MXResNet50 again to compare accuracy?
Hi @dmangla3,
Yes, that’s exactly what I did - swapped out the internal activation function of XResNet from ReLU to Mish.
That thus becomes MXResNet.
You can also just change the internals of it via act_fn, but I found it was easier for testing to have two seperate networks, with different names, to avoid any confusion.
Thanks @muellerzr! I’ve fixed it and lesson learned - cut and paste from my test code instead of writing it up by hand “b/c it’s so simple” lol.
Please post once you get a chance to use it…I’m very curious how it performs on a variety of datasets.
@LessW2020 no problem! I’ve felt that pain many times. I will take a look at it in a little bit! I plan on trying it with the Adults dataset and Rossmann, and possibly pets.
I will say, I’m trying to prepare my material for my study group this semester. You keep showing up with new state-of-the-art implementations is frustrating
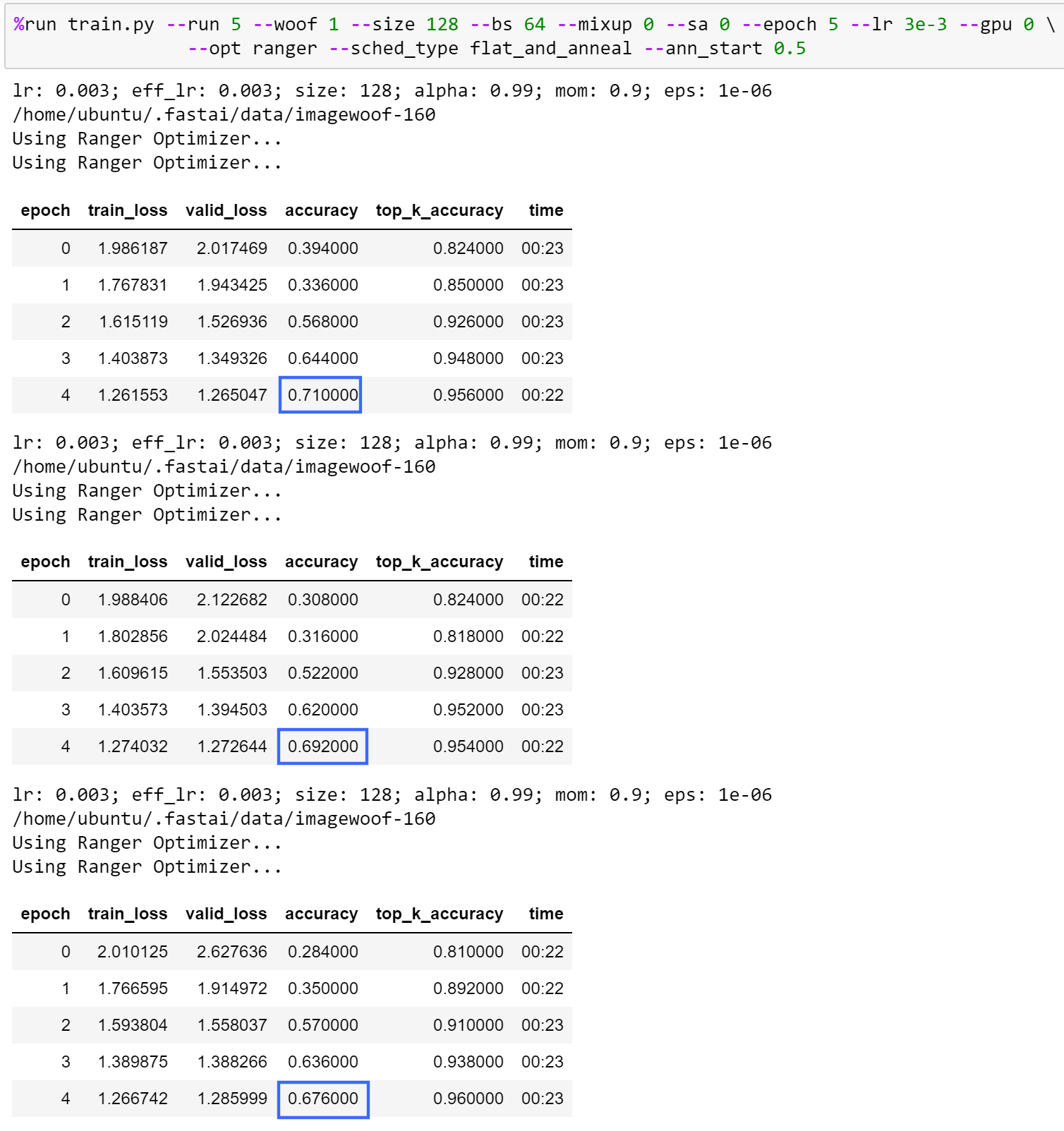
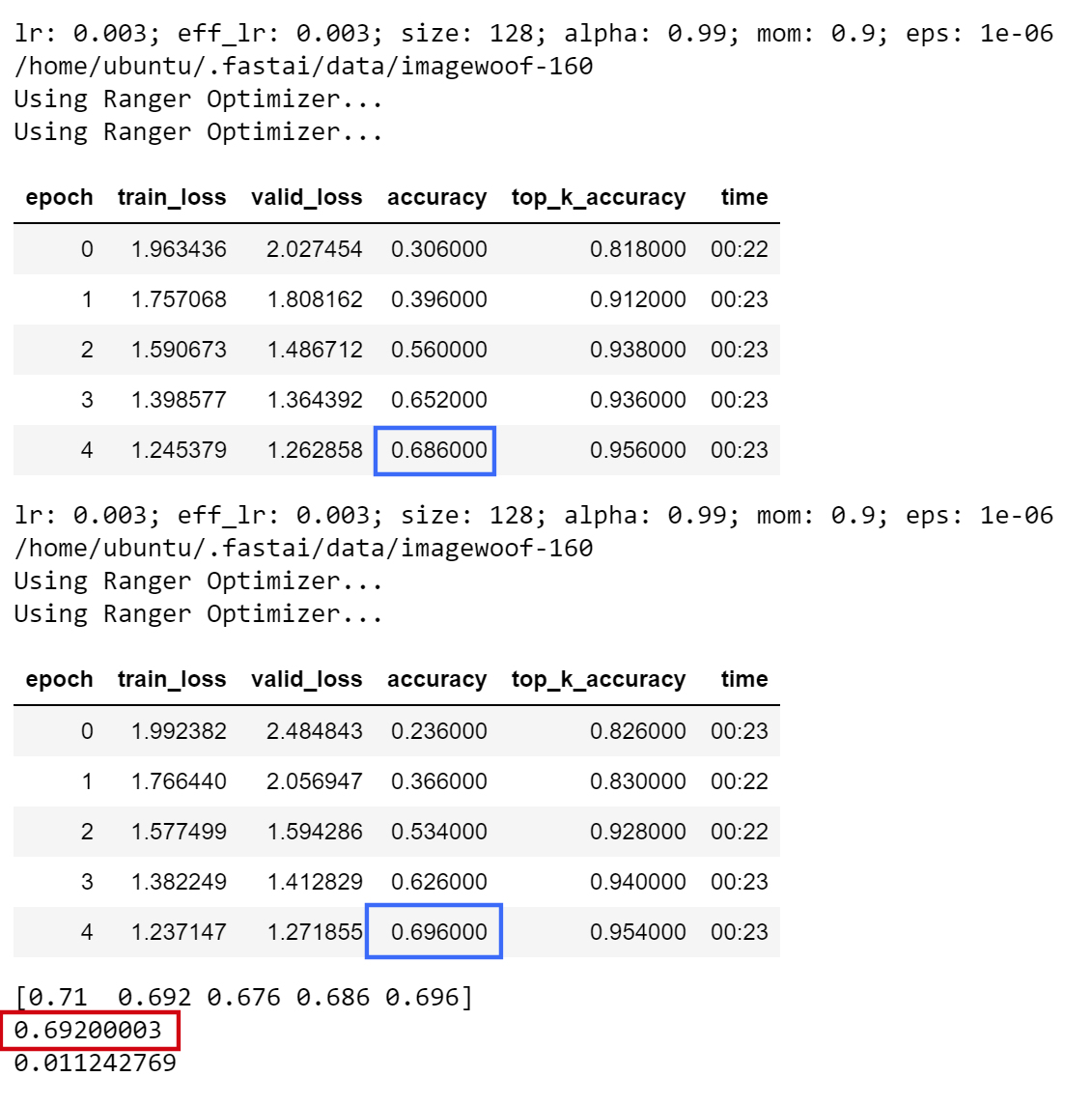
As a reminder, @grankin reran the baseline for Imagewoof, 5 epochs, (https://github.com/mgrankin/over9000) and got 61.25% averaged over 20 runs, which is higher than what you got with mish.
The true baseline for 20 epochs is most likely higher than on the leaderboard as well.
There is also an issue of high variance in accuracy from run to run on Imagewoof/nette, so I wouldn’t rush to making a conclusion with a single run that is furthermore compared to a wrongly measured baseline.
I’ve made those points in the past in the other SOTA threads, but I still see the same method being used of running things once and comparing to underestimated baselines…
Hi @Seb,
I always value your input - Let me clarify some incorrect assumptions you are making:
Agree about variance - but in this case, the fact is - you don’t know what I got for Imagewoof 5 epochs only testing b/c I didn’t show it in the article
I showed a visual in my article of a single run, which was one run of many I tested, b/c I wanted to show the results of a sample 20 epoch run with details of the epoch to epoch flow to show the improved training stability from Mish as well as the final 20 testing. That run also just happened to exceed the posted leaderboard results at 5 epochs, so I highlighted that,but was not representative of running for a 5 run setup.
Here’s what I got with Ranger + Mish, 5 epochs only runs @ 5 runs… 69.20%, that readily beats the 61.25% you are referring to, as well as the posted leaderboard of 55.25%:
Re: leaderboards - the leaderboards really need to be updated, but they haven’t been… I can’t show a visual in an article of someone posting about a score… as readers will generally consider the github leaderboards as the ‘official’ score.
In this case, it seems Mish + Ranger handily beat the leaderboard and @grankins baseline results, so I’ll have to see about getting these submitted for the leaderboard.
But ultimately, if the leaderboards aren’t updated with your results or others, then it’s not clear if there was an issue regarding reproducibility or what…so all we can really go by is what is posted on github.
Hope that help clarify and let’s see about getting the leaderboards updated!
Thanks for running those. I did think that you 5 epochs result in the article was likely to be underestimated because it is within a bigger 20 epoch run.
Now, you are changing 3 variables at a time compared to the baseline (optimizer, activation, and lr scheduler), but this is ok because we have result for Ranger + Relu + flat_and_anneal: 59.46%.
Thanks for the extra data, you got me curious enough to take a look at this!
Hi @Seb,
Thanks for the feedback!
I have ReLU results for all the same variables from earlier testing (optimizer, anneal, lr), so even though 3 are changing against the leaderboard, I was really testing only one change for myself and the article - namely, replacing Mish vs ReLU.
I haven’t really dug into testing the optimal lr with Mish - I suspect there’s a lot more gains to be had with that.
I just wanted to verify it could outperform ReLU and wrote the article based on that. I spent a lot of time before on activations that ultimately couldn’t beat ReLU even though it did great in the papers
Mish looks like a winner though and happy to hear you are going to do some testing with it!
@Seb@LessW2020 I am wanting to test drive Less’ activation along with the Over9000 (Or is it Ralamb at this point? It’s getting a little confusing for me) optimizer. I’m running it now but I want to be sure it’s up to ‘par’:
5 runs (I have class later but I want to experiment) for five epochs (20 later on). Along with the anneal scheduler. How best should I report my results so they are ‘up to par’? (As @LessW2020 's intuition is right, results do seem… interesting… so far)
Current one is as of 12 hrs ago for my small test, I need to use the newest version
Re: over9000 / RangerLars - RangerKnight just posted 2 fixes to his core code, so that should be integrated into an update for RangerLars.
Give me about 20 minutes and I’ll integrate his fixes and give you a new drop if you’d like to test with that. That would be great actually so we can see what effect the fixes have as they untested!
@muellerzr
I’d like to see the accuracy for each run, from which we can compute average and standard deviation.
Might have to rerun the same thing with Adam if there are some fixes to LARS. Otherwise, we have a baseline here: https://github.com/mgrankin/over9000
5 runs might be enough. More could be needed if results are close.