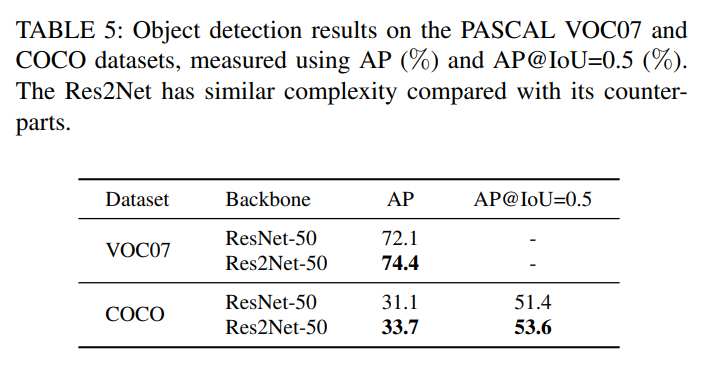
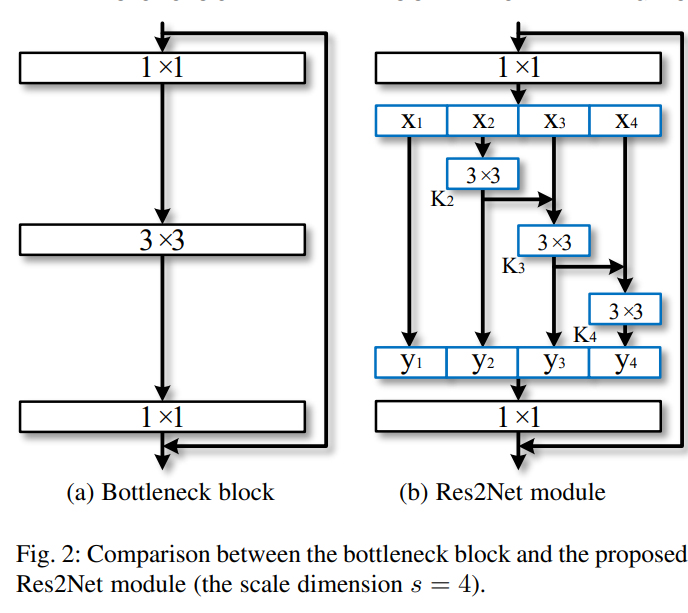
There was a recent paper that discussed the role of scale / multi-scale in image processing and they modified ResNet to make Res2Net and showed improved accuracy:
I have taken @fgfm 's implementation of it and modified the stem to be the same as our XResNet and added in Mish activation function.
I wanted to post it out in hopes others will test it out and figure out how to improve on it. It is currently doing amazingly well on training loss…but just so so on accuracy.
So something is still not quite there with it, but it holds promise.
Here’s some quick data from the paper:
I’m going to continue rewriting it to make it closer in spirit to how XResNet is written (very compact) but adding in multi-scale handling intrinsically seems to be a promising avenue for improving various vision architectures.
My latest article - Res2Net! I used Res2NetPlus for a recent consulting project on solar panel detection with great success. I compared it vs ResNet (pretrained) and Res2NetPlus was the clear winner (and what is now live in production):
Thanks for the great blog post and implementation. when I try to use your code on my own dataset I keep getting errors about invalid argument 0. can you please share a running example of your code?