if these functions like Mish are too slow, maybe you can find a faster approximation? There’s a software called eureqa that can find approximations for a given function, as mentioned here: https://stackoverflow.com/questions/10732027/fast-sigmoid-algorithm
1 Like
From the discussion there, I found that Eureqa mostly does a series expansion of some sort. So in the formula of Mish we will have 0.36787…^x in the inner term rather than e^x which still doesn’t solve for any computational cost issues. We still are having a pow operation which is slow. Again, another question would be, how close the approximation will be and will that affect performance. What Mish does is, it justifies for it’s relatively high computational cost by getting much better results. So, I’m not sure, how much more we can optimize Mish, but it’s indeed a topic of discussion. I haven’t used Eureqa yet to validate my above statement but this is just my initial thought.
2 Likes
I think eureqa doesn’t always give you a series expansion. Rather i it tries out lots of functions and shows you some it found to be similar.
Maybe even a piecewise linear function as an approximation would work. I have no idea how important the smoothness of the function really is. That relu worked so well suggests it’s maybe not so important.
@Diganta and others!
I posted my results here: How we beat the 5 epoch ImageWoof leaderboard score - some new techniques to consider
I tested again activations and find bug in xresnet implementation!
My result - Mish vs Rely vs LeakeRelu is:
0.7412, std 0.011, 0.7572 std 0.0100, 0.7576 std 0.0058.
Point is, what default argument in kaiming_normal_ is: nonlinearity=‘leaky_relu’.
If you implement right numbers for Mish, i believe, results will be much better!
2 Likes
Excellent finding @a_yasyrev!
Since Mish is not in PyTorch right now, we should probably see if the LSUV init may setup things better as well. Esp for 5 epochs the init may have a large effect.
1 Like
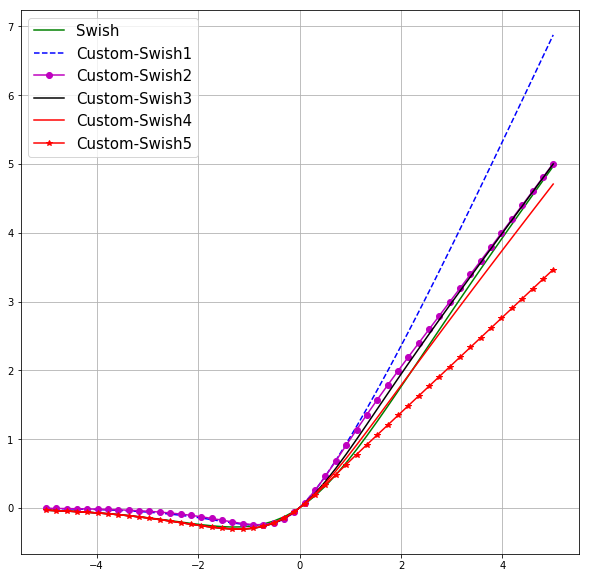
Mish wasn’t a hunch, I mathematically constructed several functions whose graphs might closely emulate the graph of Swish and these are those 5 functions. But only 1 out of these, which ultimately became Mish worked. The reason I’m saying this that if Eureqa gives a close approximation, as you can see how similar these graphs are yet most don’t work, will the approximation work?
5 Likes
I’ve tested multiple lsuv initialization schemes, including the one you mention, but they didn’t work for me.
However, I came up with a simple idea that uses lsuv that improved the Woof (size:128, epochs:5)) outcomefrom my baseline, which was BL = 0.75160 +/- 0.00950 [0.7519999742507935, 0.7639999985694885, 0.7480000257492065, 0.7360000014305115, 0.7580000162124634] to 0.76680 +/- 0.00676 [0.777999997138977, 0.7680000066757202, 0.7620000243186951, 0.7680000066757202, 0.7580000162124634].
The idea is the following:
- Initialize all Conv2d layers with lsuv (with orthogonal weights). In this was the initial activations mean=0 and std=1.
- Change the order of the layers in conv_layer. Instead of doing Conv-BN-Mish —> Conv-Mish-BN.
I need to run a few more analysis to fully understand why this happens.
Note: in case you want to try it, just changing the order of the layers (even without lsuv init) increases performance by 1.2%.
I will share a repo when I finalize the tests (probably tomorrow).
3 Likes
Nice job @oguiza! I can tell you what you have done - basically you have replicated a paper by TenCent that argued that the default order of BN vs activation was wrong…that it should be reversed.
For example, we should not place Batch Normalization before ReLU since the non-negative responses of ReLU will make the weight layer updated in a suboptimal way,
They showed that having activation after BN forced the NN to deal with very jagged paths, vs reversing it allowed things to flow much better.
They also added in dropout…but I think the bigger factor is the order reversal. I’ll try and test the reversal as well. I thought I had tested it when I read the paper but with ReLU and didn’t see much difference then.
Anyway, thanks for the post and look forward to your workbook as well!
5 Likes
I ran a quick first test of 10 runs of 5 epochs using the order reversed MXResNet that @oguiza invented:
[0.778 0.738 0.782 0.776 0.764 0.756 0.768 0.738 0.754 0.75 ]
0.76040006
0.015041287
Thats 1.07% over our current record, so basically @oguiza has helped us set a new record! 
I’m going to try and run a quick 20 epoch test as well and see if the improvements holds there as well.
6 Likes
On that paper, Jeremy mentioned it (the paper) in an old Part 2 and tried it out  (the reversing) (forget which version it was, but it was a question in the audience) otherwise awesome work guys! I haven’t been able to do much work thanks to school but I’m keeping pace with the updates
(the reversing) (forget which version it was, but it was a question in the audience) otherwise awesome work guys! I haven’t been able to do much work thanks to school but I’m keeping pace with the updates
1 Like
Was that 5 epochs and not 10?
oops, yes sorry I typoed it…I said 10 epochs but meant “10 runs of 5 epochs”. Updated original post
2 Likes
So no improvement with the new BN/Mish order reversal on Woof 128px 20 epoch, nor for imageNette 5 epoch 128px, nor Woof 5 epoch, 192px.
so it just seems to work for Woof 5, 128 at this point.
I’d really like to test with the LSUV + BN/Reversal for Woof5 128px though.
@oguiza, if possible, can you please post/share your LSUV init code?
I started modifying LSUV from dl2 but ran out of time…plus it seems to be fair, since it seems we have to process a batch to init, then we have to reduce a batch from the full test run?
2 Likes
Why does ReLU work so well by killing negative activations in the first place? If we are making modifications on it, we should know how this behavior helps it
I have been using that result with great success… I no longer put BN before the activation.That’s my default.
3 Likes
In my small tests in various applications I’ve found it helps in some cases but not in others so it’s certainly one option to atleast try ![]()
Same here, but as it haven’t hurt me this is my default now.
2 Likes
Sure! I was planning to do it.
I’m not working today, but will hopefully be able to clean up the code and share it tomorrow.
It’s a bit dissapointing to see that the tests you have run have not worked. I’m not sure what’s the importance of lsuv incombination with the bn/mish order reversal, but will continue investigating. I think that if we find a way to normalize data throughout the network with as little additional computation as possible performance would be increased. I have a few ideas to test this. I’ll keep posting my results and sharing any code I use.
3 Likes
def mish(tensor: torch.Tensor) -> torch.Tensor:
return tensor * tensor.exp().add(1).log().tanh()
Is this a better implementation?
1 Like
Hi @Diganta,
I just tried the above but could not get it to work. I was getting bizarre errors in the optimizer when it tried to run the gradients from it after trying to force the computations into a tensor. If I just ran it as is I got other errors about tensor doesn’t have that function…I didn’t have long to dig into it but can’t provide feedback yet as I couldn’t get it to run as expected.
Were you able to get it to run? If so can you show your code for it?
Here’s what I had:
class Mish(nn.Module):
def init(self):
super().init()
print(“Mish activation loaded…”)
def forward(self, x):
#save 1 second per epoch with no x= x*() and then return x...just inline it.
return tensor(x * x.exp().add(1).log().tanh() ) #x *( torch.tanh(F.softplus(x)))
1 Like