btw - just one thing to think about.
I have seen several papers where they got even better results by using multiple activations, with different layer groups using one activation, other layer groups using another and the combination outperformed the network with only one or the other. (i.e. heterogenous activation networks).
Thus, it will be interesting to keep that in mind as we learn more about Mish, and Balaji’s new function etc. as we may be able to customize an XResNet to leverage them together, respectively if we find where their strengths and weaknesses are.
So there was a paper by lastminutepapers where they showcased combination of activations in a single NN. The recent project I’m working on called XTAN is basically that. It’s a gridsearch for getting the best activation for each layer for any model defined. Link to the paper - https://arxiv.org/pdf/1801.09403.pdf
Here’s two more related to that concept of HAN (heterogeneous activation networks). I think this is a space that might yield new innovation and results, along with leveraging scale inside the networks (ala res2net).
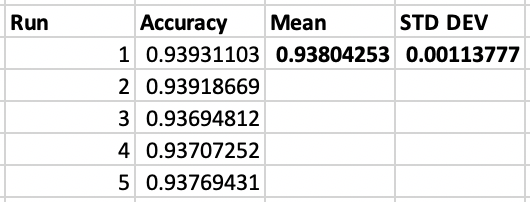
Not to drag the conversation too far backwards, but I think I got a nice result with EfficientNet-b3 + Mish + Ranger on Stanford Cars:
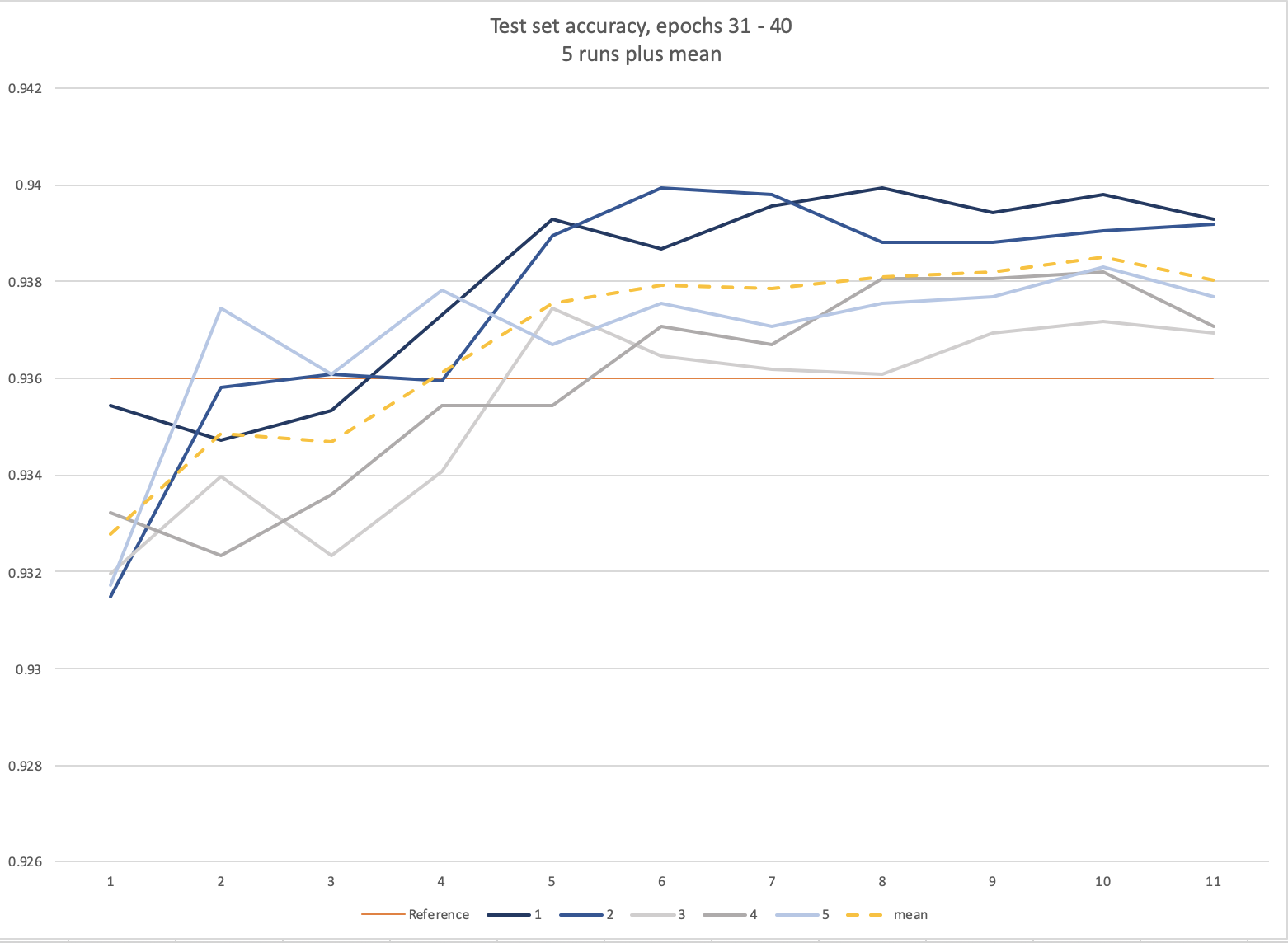
93.8% 5-run, 40epoch, mean test set accuracy on Stanford Cars using EfficientNet-b3 + Mish + Ranger Beat the EfficientNet paper EfficientNet-b3 result by 0.2%. The EfficientNet author’s best result using b3 was 93.6% (their best EfficientNet result was with b7, 94.7%)
I found that with Ranger alone, EfficientNet was much more stable to train but I couldn’t match the accuracy from the paper, adding Mish then pushed it over the line
At least for me, EfficientNet + Ranger (with and without Mish) preferred a shorter flat period that the XResNet Imagewoof work here (10% start_pct worked well for me) before the cosine anneal
Great work @morgan! Thanks for sharing and definitely interesting to note how you had better results with the modified start point for cosine annealing.
(*also I’ll take a look at the step bug you mentioned regarding Ranger…but will update in the Ranger thread to keep this thread focused).
Anyway, great to see and excellent job with your results!
This is awesome. I couldn’t have been more proud and happy. I’m planning to see if we could beat ImageNet benchmarks, it would be massive because we will essentially have the best pre-trained model.
If we can make a pretrained imagenet MXResNet50, that would be very exciting…a number of people have asked about this on some of the article comments.
And yes if we also beat the IM benchmarks out there now that would be even more exciting
Answering this question, nothing noticeably worked. I may try some different 2D-embedding methods and running that comparison on our new techniques. Something more sophisticated than the “text on an image” method that came out a few months back.
I’ve got one positive imagenet result on a smaller network. A bit too early for me to throw it out there without more runs and more comparison. One issue is that I had to bring the batch size down significantly for the run with Mish, so I need to re-run the ReLU baseline to be fair, and then get repeat runs of all. On ResNet networks I have to bring the batch size down 2.5-3x from ReLU. If I come up with a definitive set of comparable results I’ll share. I was hoping to have an optimized ver of Swish and Mish before I did that.
I’ve been running some training sessions on imagewoof with more interesting networks to prep hparams for some longer runs with full imagenet on the bigger networks. Even these are slow going with the extra overhead Mish adds + the 300-400 epochs. I’m hoping to compare Swish as well. On the smaller runs, I’m trying to keep the focus the same as with ImageNet, on max end result and generalization to another test set. I’m usually hitting 92-93% top-1 for these tests. I have noted however that the augmentation used has a more consistent impact on the end result than the specific activation.
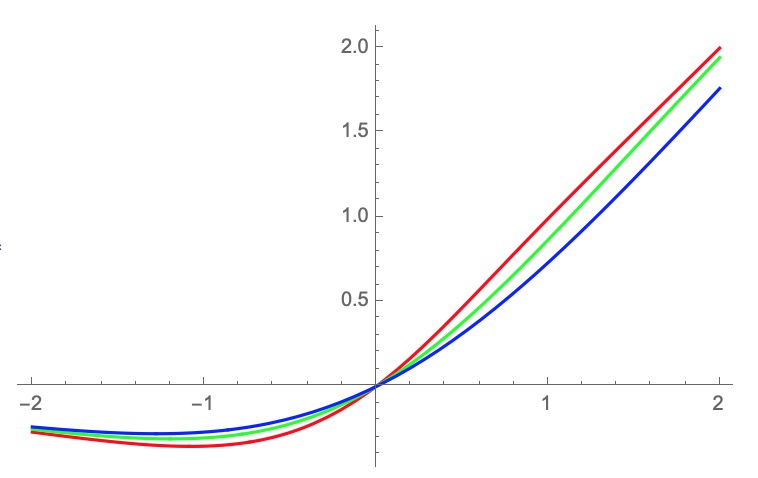
One interesing mistake I made. I was playing around with Mish eqn in Mathematica to look at possible backward pass of a custom CUDA impl. I entered the eqn wrong at one point … used y=x * tanh(exp(x)). It’s actually not far off Mish and Swish. Out of curiousity I gave it a shot in my experiments and it actually hit the highest validation accuracy of the current runs up to this point. Keeping in mind, not clearly out of the variance of results for repeat runs, but it certainly worked.
Thanks for the initial comparisons @rwightman . I’m actually very intrigued with your ‘mistake’ esp if you think it allows faster computation at equal or better accuracy, or possibly just improved results due to the sharper curve.
I’m recalling things like Dove soap, etc that became huge products due to initial mistakes
In fact I’m goiing to just crank out a few Imagewooof test right now with it just for kicks.
But you should give it a name besides mistake…maybe MishR (Mish + RWightman) lol.
I’m actually very intrigued with your ‘mistake’ esp if you think it allows faster computation at equal or better accuracy, or possibly just improved results due to the sharper curve.
Heh, it is only a very slight improvement from Mish in terms of throughput and GPU memory usage. Closer to Mish than Swish in that regard, with Swish being better, and all quite a bit worse than ReLU. Although the derivative is far less daunting so maybe easier to plug into a custom CUDA impl.
oh well - I tested it with and without attention layer and MishR was always 2-3% lower on 5 epoch results (did multiple runs). I didn’t see much change in per epoch
Anyway, still great b/c this is how we make progress - test and see what delivers, so thanks again @rwightman for sharing the mistake!
I guess that means that the exact slope of the activation is important?
Here’s how I wrote it up in case I made a mistake in impl:
class MishR(nn.Module):
def init(self):
super().init()
print(“Mish-R loaded…”)
def forward(self, x):
return x * torch.tanh(torch.exp(x))
On other news, I’m making progress with a self tuning optimizer (autoRanger? lol) and may have a beta release later this week for that. it’s a combo of novograd + alig optimizers to try and combine both of their strengths. I want to see if it is competitive on the 20 or longer (80) epoch scores (it won’t win on the 5 epoch), b/c it does a good job of adapting deeper into the runs where most other things get a bit erratic…I haven’t gotten an update for a bug fix from the AutoOpt team so that’s still stuck at this point.