I hope so ![]() one thought I had is perhaps it’s too simple. We just have linear layers and activations. Not much can change there and there’s a limit. Just my thought
one thought I had is perhaps it’s too simple. We just have linear layers and activations. Not much can change there and there’s a limit. Just my thought
1 Like
Thanks to @fgfm implementation of Res2Net, I was able to quickly modify it to be similar to XResNet (same stem vs old style stem) and up and testing now with it.
First feedback - it absolutely crushes on training loss, posting numbers way below what we were getting.
But - the accuracy is worse at least for the 5 epoch…I’m a bit baffled how it can do so well on training loss but be behind on accuracy.
I turned of label smoothing and running a 20 epoch now to try and figure it out.
Bit negative is while they said it was same gflops as regular ResNet50…it’s clearly way slower. (almost 2x).
Anyway, it looks promising based on the training loss, but I suspect it may need different learning rates or possibly different presizing.
1 Like
well I spent about two hours with it and got it somewhat competitive but never really likely to be an improvement for 5 epoch.
I moved to 20 epoch but it kept stopping at epoch 14 or so (would finiish with and a linear drop so something was misfiring) but it also was still pretty far from where we usually were at that point.
The two positives were very strong training loss and as far as where I got on 20 epochs it was a steady machine with nearly improvements every epoch.
I think I’ll put it aside for now.
Slightly off topic ish but I want to try implementing this paper this weekend. Allegedly it’s close to GBT’s on many cases and may help here with differentiating and mabye we can see an improvement with optimizers etc.main challenge is converting Keras to pytorch
1 Like
Hi all,
I think i was able to beat the score in one of the leaderboard tasks.
`–woof 1 --size 128 --bs 64 --mixup 0 --epoch 5 --lr 4e-3 --gpu 0 --opt ranger --mom .95 --sched_type flat_and_anneal --ann_start 0.72 --sa 1’
I haven’t yet tested my pipeline for other tasks yet due to compute capability issue. I hope to do so within 2 days.
i ran both pipelines simultaneously. I would like to know whether my experiments are valid. I have taken the code from https://github.com/lessw2020/Ranger-Mish-ImageWoof-5
My Pipeline - Replaced Mish with my activation function and did modification to support my activation
Existing pipeline @ the link https://github.com/lessw2020/Ranger-Mish-ImageWoof-5
My Pipeline - Replaced Mish with my activation function
Scores for 10 runs:
Existing pipeline
[0.764 0.75 0.74 0.73 0.744 0.76 0.75 0.75 0.752 0.734]
0.7474
0.010121254
My pipeline
[0.772 0.776 0.77 0.77 0.766 0.756 0.758 0.768 0.768 0.738]
0.7642
0.010447974
Waiting for your reply so i can carry out the experiment for other leaderboard tasks.
U can find the results notebook @
4 Likes
That’s a pretty clear beat for the leaderboard, i.e. the results look statistically significant. Thanks for sharing the notebook as well. Nice work!
A couple things:
-
Your time per epoch is about 30% slower than the baseline. While there is currently no rule in the leaderboard to take into account time (that’s a flaw in optimizing per # of epochs), we have to see whether this is useful. Maybe it is, as it could converge to a better result. Or maybe there is a way you can still optimize the code for speed.
-
Is your new activation still unpublished? If so, feel free to discuss your results with us, but I believe we should wait until it is open source and reproducible to add it to the leaderboard.
2 Likes
I am actually working on ways to optimize the activation function. The mentioned activation function achieved good results in few other leaderboard comparisons as well.
Yes. My activation function is yet to be published. Thats why i haven’t updated the code in the git yet.
For now, i will experiment and share results in git. Once published i will do PR and update leaderboard.
Thanks a lot @Seb
5 Likes
How does Mish differ from GELU?
1 Like
HI @balajiselvaraj,
Great to see you here and glad to see your new activation function being tested here!
As Seb already noted, it looks like a clear beat on an absolute basis.
My one concern is that it looks like the time to do it with the new activation increased epoch time by 30% vs the current setup.
Thus, on an apples to apples comparison, if the current setup is run for an extra 30% then it likely isn’t a beat. (i.e. if I run for 7 epochs to equalize the time spent on 5 with the new activation, then my guess is the current setup would match or beat the score from 5 with new activation.)
That’s one aspect we haven’t really figured out how to handle as our setup vs the old one was nearly same time (added about 1-2 seconds per epoch).
I also agree with @Seb that the source really needs to be shown to verify things. Do you have an ETA on your publishing time? I"m very interested to see it.
Also, @Diganta is here on the boards and I think you guys might get a lot from talking with each other since you both have activation expertise.
Anyway, good job on the tentative high score improvement that’s exciting to see. I’ll run a 7 epoch experiment in just a minute to see how that matches up, but hope you are able to optimize the speed for it as well.
2 Likes
Please feel free to visit the repository of Mish to see comparison of Mish with GELU. Dan, who is the author of GELU had emailed me to benchmark Mish against GELU.
Mish repo - https://github.com/digantamisra98/Mish
1 Like
Absolutely. @balajiselvaraj, I would love to talk about your new activation function. At the current time complexity, it’s hard to put forth a direct recommendation for it as @LessW2020 suggested. But if we can optimize and scale down the computational expenses, it would be great. Let me know if I can help in any way.
Hi Less,
For now, I am just analyzing the performance of the activation with respect to accuracy.
I already have plans for optimization. As i am having lot of commitments, I aint finding much time for it.
Hope to start working on it within two weeks.
For now, I am planning to submit around December.
Hi @Diganta, it would be great to discuss with you. Hoping to learn from you.
1 Like
Hi @Diganta,
I compared GELU as well on these datasets. GELU performs nearly equal to Mish. There were instances where the accuracy was higher than Mish.
During first attempt
results across 10 runs {Mish < GELU}
|gelu | 0.748 |
|msh | 0.7476 |
During second attempt {Mish > GELU}
|gelu | 0.7546 |
|msh | 0.7594 |
for following settings
`–woof 1 --size 128 --bs 64 --mixup 0 --epoch 5 --lr 4e-3 --gpu 0 --opt ranger --mom .95 --sched_type flat_and_anneal --ann_start 0.72 --sa 1
I tried multiple attempts and as GELU was performing nearly close and didnt beat Mish clearly, I didnt consider GELU.
3 Likes
Hi @mdp777 - here’s a screenshot from @Diganta Mish github with some basic comparison testing with GELU.
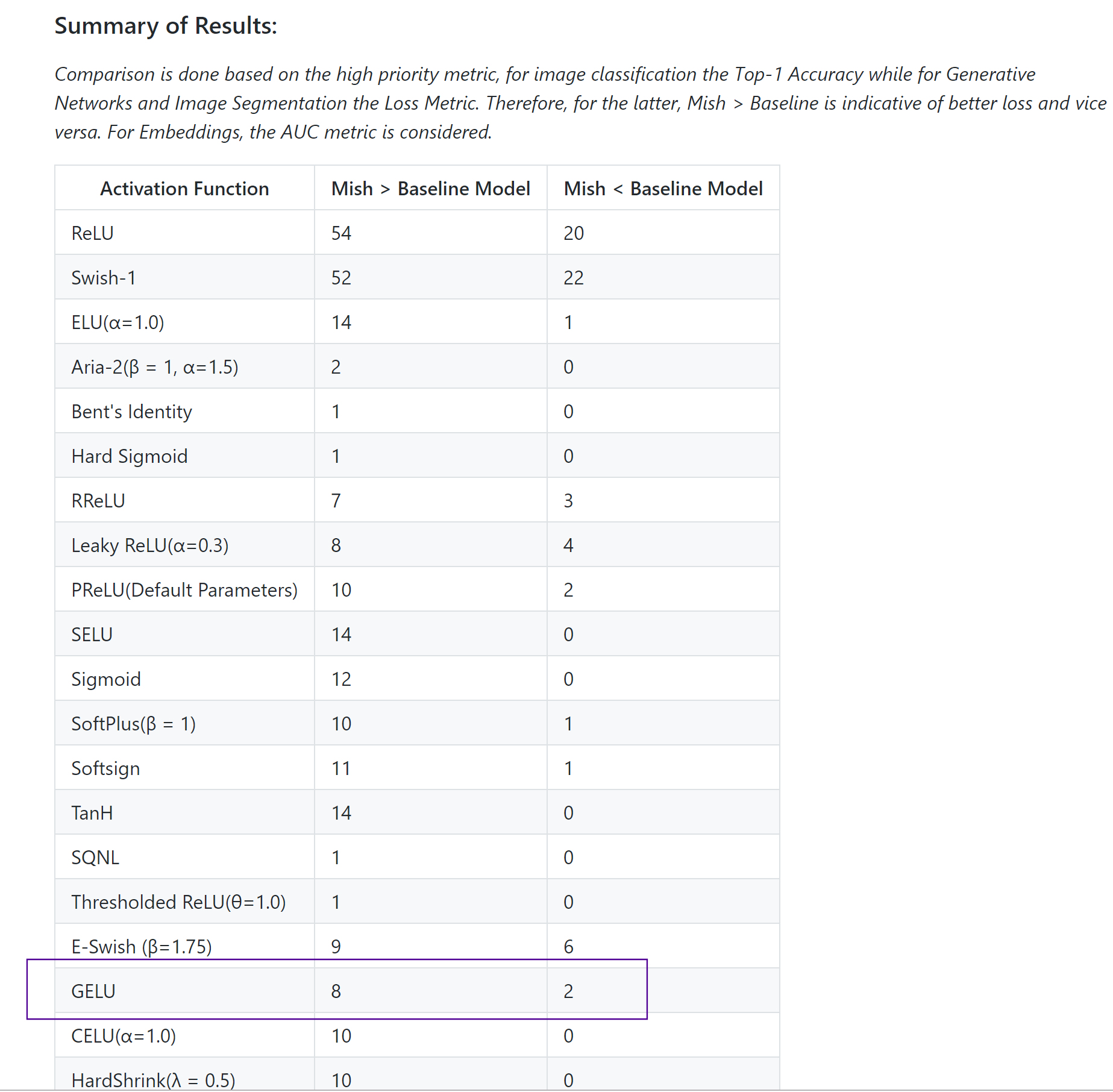
2 Likes
Interesting - thanks for sharing these results @balajiselvaraj.
1 Like
Yes. In my 10 tests, Mish beats GELU 8 times while looses twice but the variation/ difference has been extremely less. And also the output landscapes for GELU is similar to Mish and Swish alike. So, it’s debatable but then 8:2 ratio proves Mish has an advantage. Again, it depends from different problem set to the other. And again accuracy might not be the only significant metric to compare the robustness/ efficiency of an activation function.
2 Likes
Also as shown, it’s just a .02 difference which is extremely marginal.
1 Like
Check the updated msg
Well said. Thats y I didnt consider GELU. I tried my activation too multiple attempts and it beat Mish all the time with nearly same difference as i have shown here in my initial msgs.
1 Like
So again that proves, we will only know in the long run, who is the winner, as far as the tests I have done, Mish comes out on top but I’ll keep benchmarking more and provide the results.
2 Likes