I want to stress that Jeremy recommends that students of the course, especially new students, to use one of the cloud options for running the notebooks. Again, the main reason for this is that they should work out of the box with minimal troubleshooting. By following his advice, you will spend more time obtaining knowledge of deep learning. However, if you are up to more troubleshooting and have a GPU on hand you may want to try a local server.
I have done a local server for several years in doing this course. 5 years ago, I built a server with an Nvidia 1080ti. At that time, it took a lot of configuring to get things working correctly. Software has evolved and the setup is pretty straightforward nowadays if you plan on using Ubuntu. Install the OS, install the nvidia drivers, install fastai, clone the repo, and you are up and running.
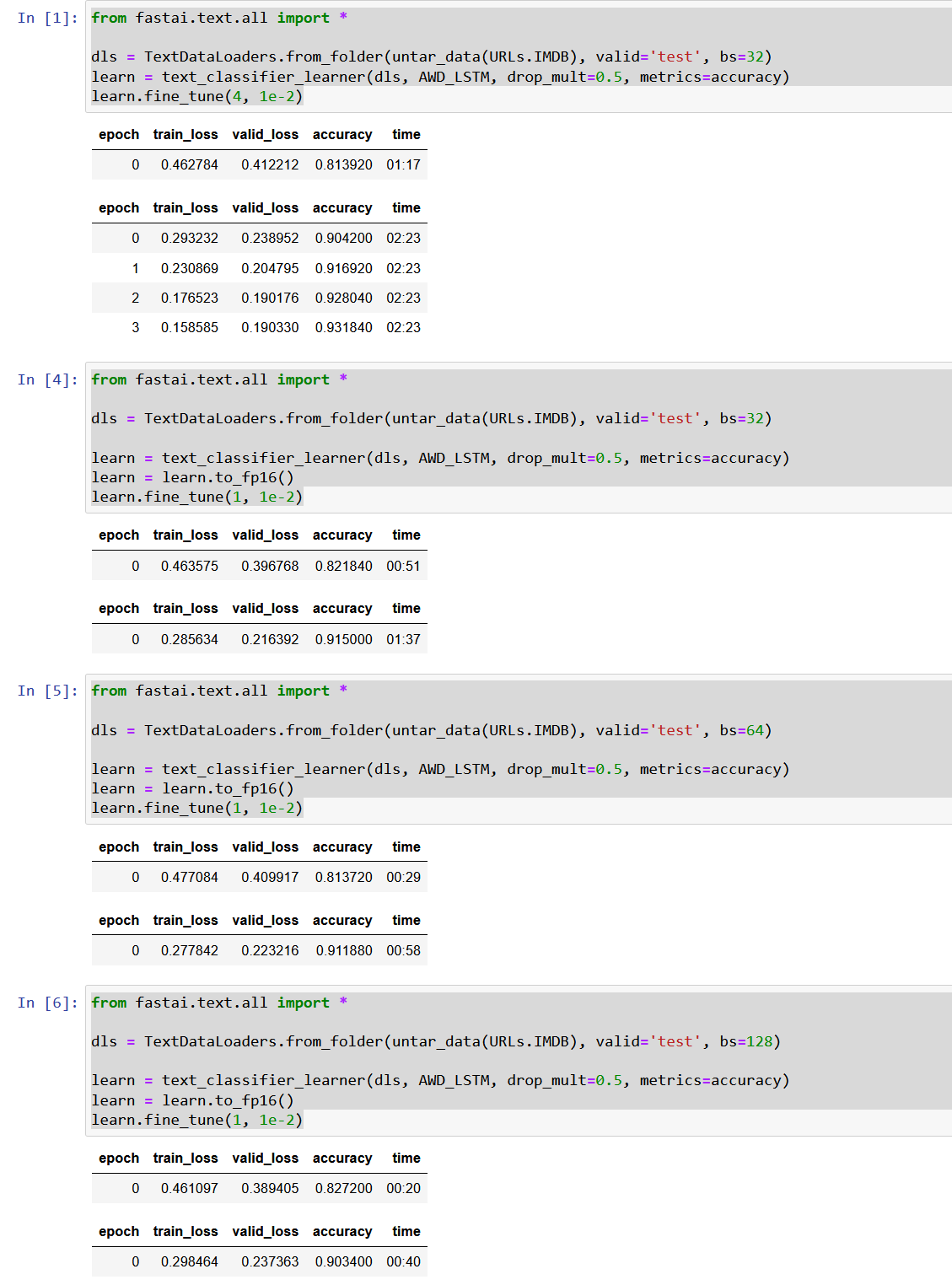
So how does a 5 year old 1080ti card perform? It can hold its own. For instance in the first lesson’s notebook, it will spend about 25 secs an epoch doing image classification on PETS. Once you get to text processing on IMDB, it will take almost 5 minutes an epoch (4:52) fine tuning once you reduce the batch size. Not too shabby if you ask me.
Earlier this year, I built a new machine with a 3080ti. So how does the recent generation stack up? Well first, let me say that I tried running this in native windows. With the problems Jupyter/ipython has with multi processing, this test was over before it started. I would NOT recommend trying to run fastai in a native windows environment. So what could you try on the “windows” front? WSL2!!!
I setup WSL2 similar to my post on the subject, but the link contents have been updated to make it a bit more straightforward. Basically if your windows is pretty recent, you can just follow nvidia’s steps. Once setup, I ran the same notebooks and found that the 3080ti would run the tests listed above in about half the time. PETS would take 11-12 secs per epoch, and IMDB in 2:23 per epoch.
Now, I do not know how long it takes the various cloud options to run the same tests. I only make this post so you can approximate the performance/time of GPUs for those tempted to create/run a local server. With GPU prices coming down in price from their mining peak, some may want to go down this route. You can then find your breakeven point for services that may charge after a certain usage time.
I hope this helps and I can’t wait to get back into DL!