A larger batch size is usually faster than a smaller one because the GPU utilization is higher, although that’s not always the case and depends on where the speed bottleneck is in your training pipeline. As a general rule of thumb you want your batch size to be as large as possible while still fitting on the GPU ram and divisible by 8 (if possible if you’re utilizing tensor cores). How long was your old vs new epoch time? I believe Colab will also sometimes give you a different GPU depending on what they have available so that can affect things significantly as well (K80 vs P100).
My bet is that your batch size is the culprit in this case. When I went from bs 16 to 32 it made a ~50% speed difference.
Also as a note - when you increase your batch size you usually want to increase your learning rate as well.
I ran some benchmarks myself as I was curious what the differences looked like. I tried 16 vs 32 batch size on Colab as well as on my local machine with a 3090 with varying batch sizes as well as fp16.
COLAB
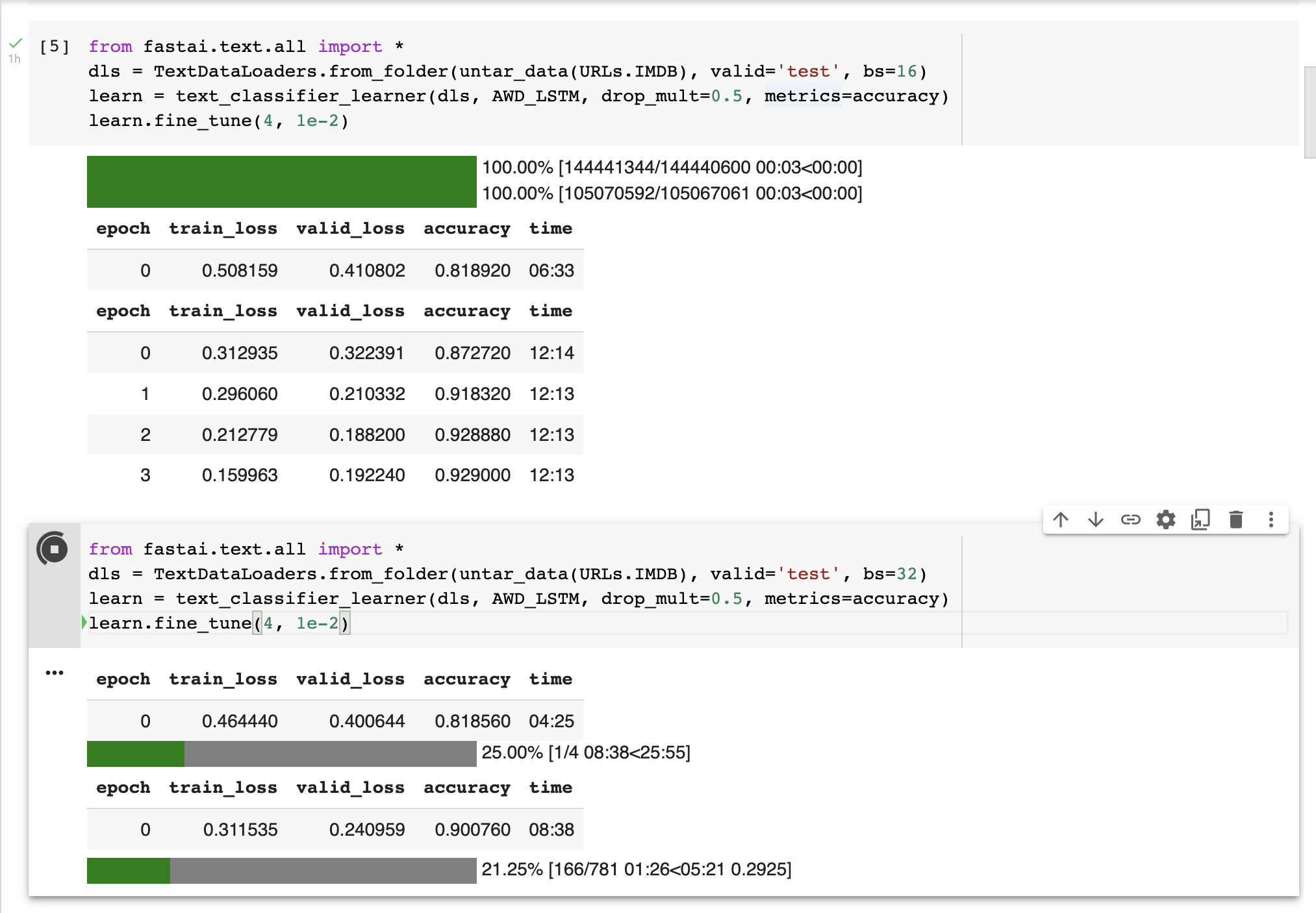
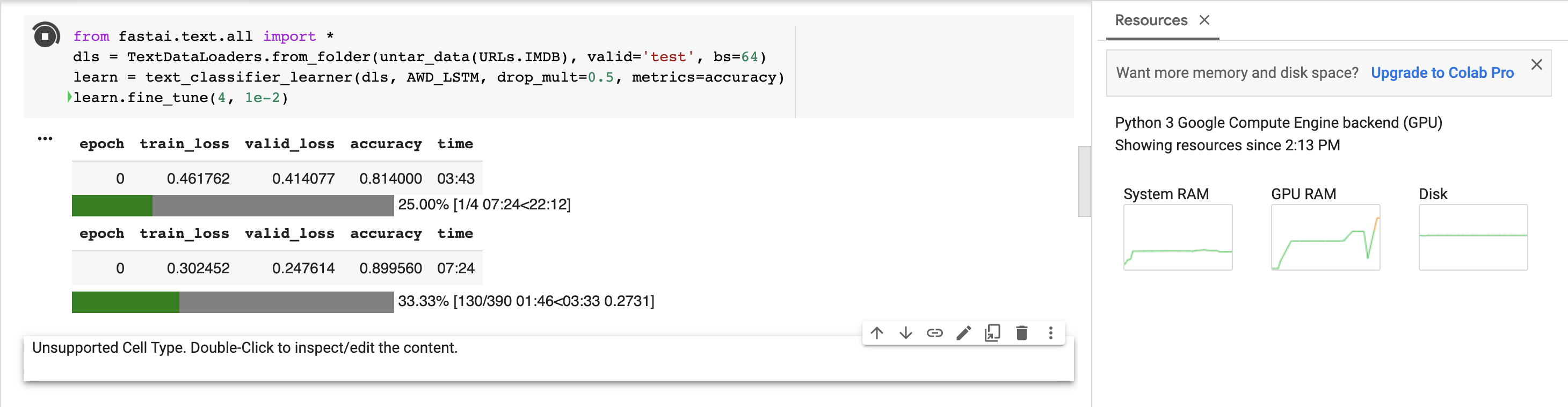
Local 3090

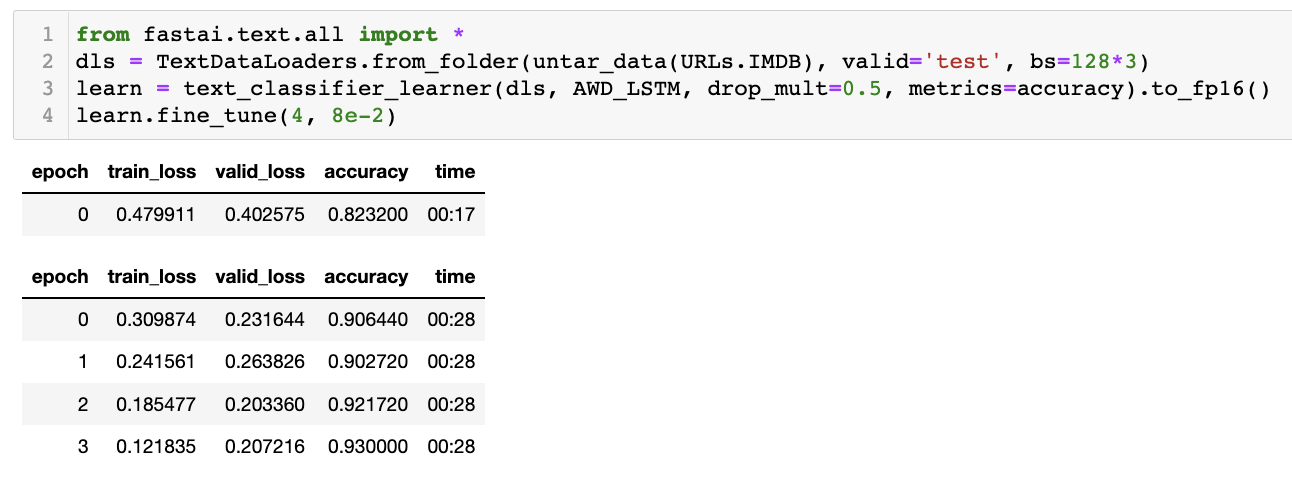
All Local 3090 Benchmark Tests
NLP Benchmark Test 1.pdf (504.4 KB)