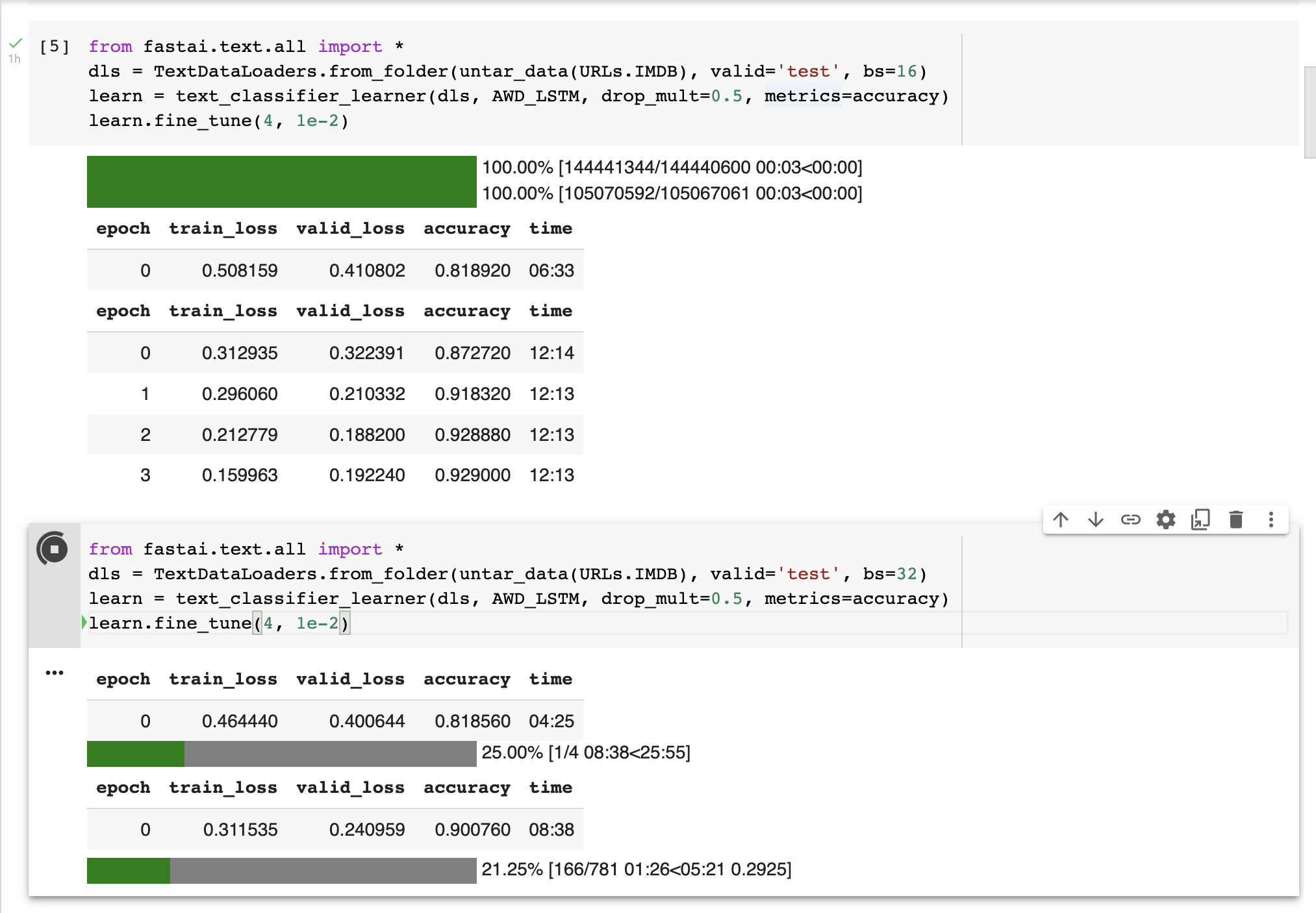
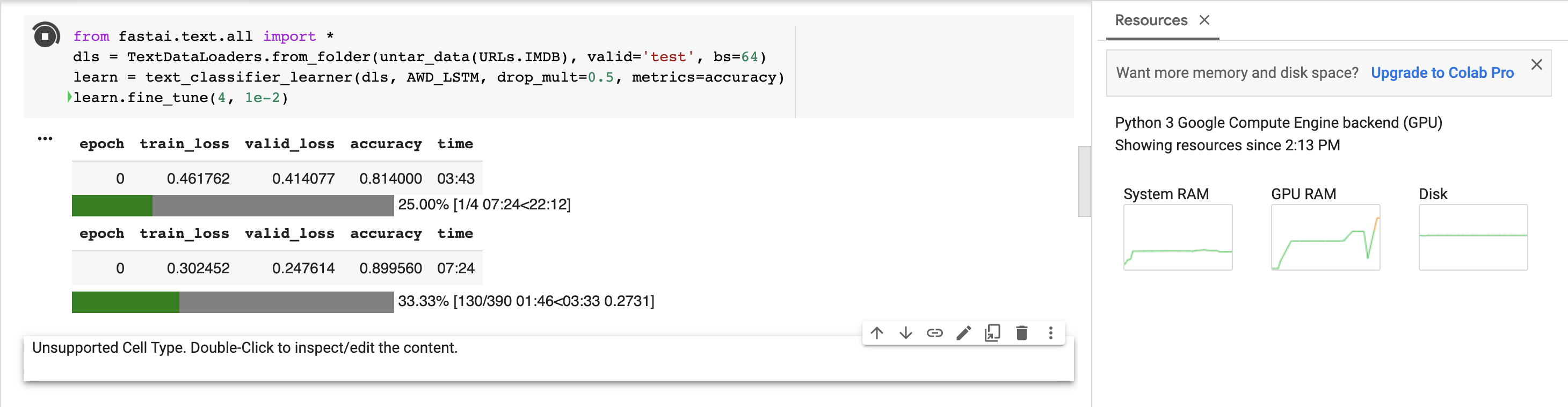
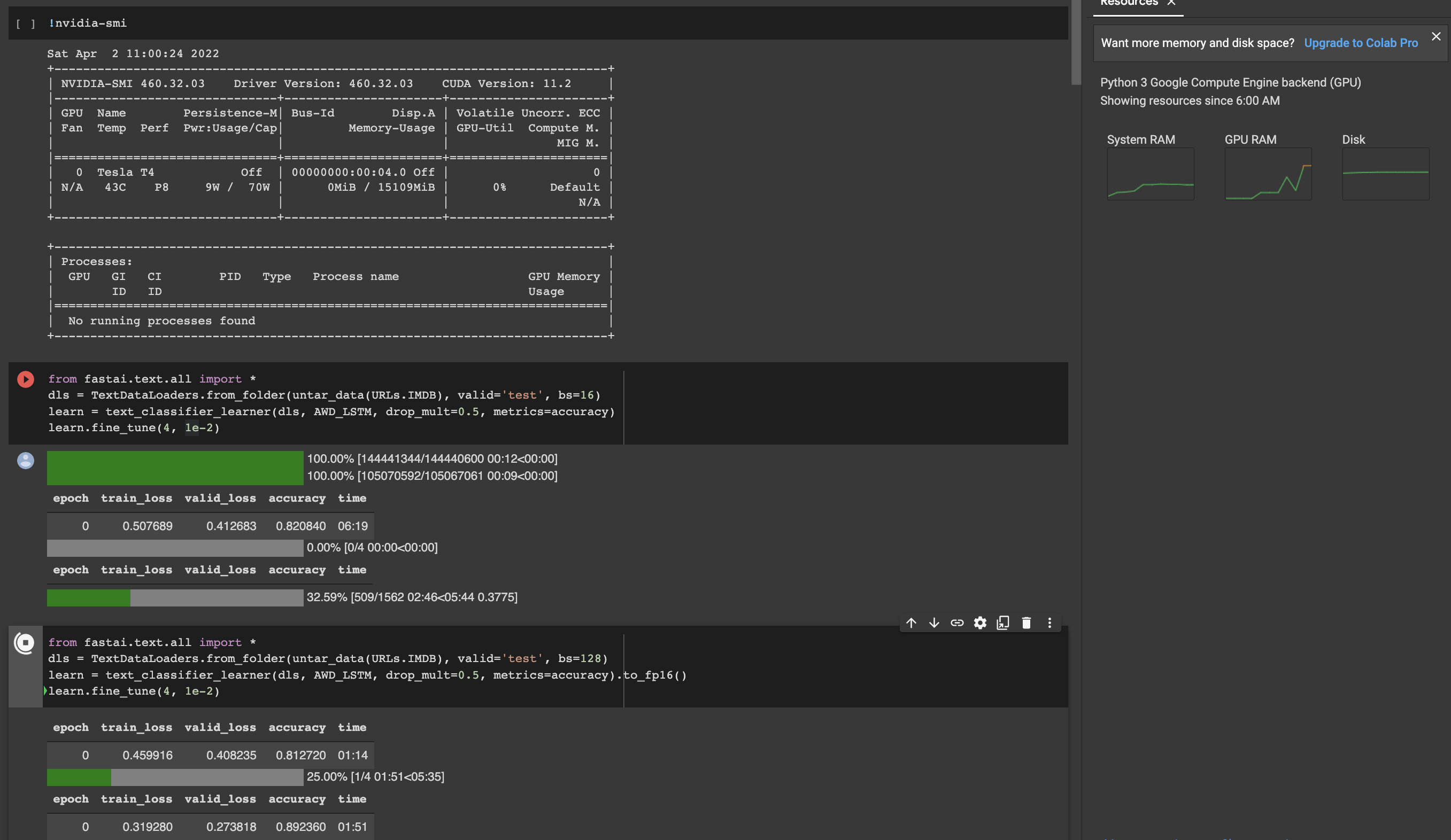
I’ve found re-running the following code in a free instance of Colab to take c.50% longer today than what it originally did some time ago. In addition, batch size is set to 16 (bs=16) in the slow recent run vs. original run where bs=32.
A larger batch size is usually faster than a smaller one because the GPU utilization is higher, although that’s not always the case and depends on where the speed bottleneck is in your training pipeline. As a general rule of thumb you want your batch size to be as large as possible while still fitting on the GPU ram and divisible by 8 (if possible if you’re utilizing tensor cores). How long was your old vs new epoch time? I believe Colab will also sometimes give you a different GPU depending on what they have available so that can affect things significantly as well (K80 vs P100).
My bet is that your batch size is the culprit in this case. When I went from bs 16 to 32 it made a ~50% speed difference.
Also as a note - when you increase your batch size you usually want to increase your learning rate as well.
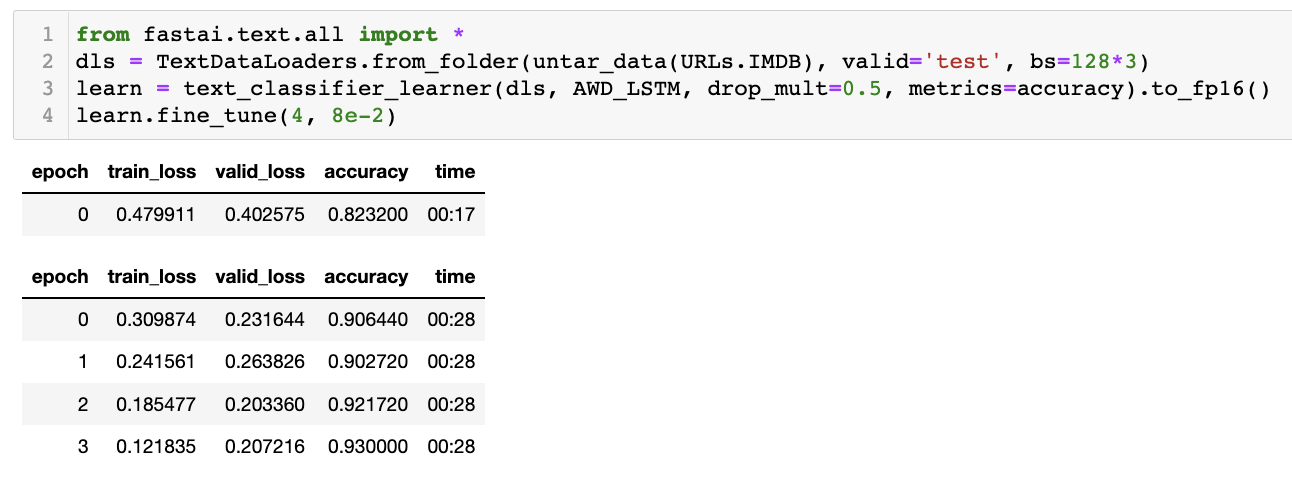
I ran some benchmarks myself as I was curious what the differences looked like. I tried 16 vs 32 batch size on Colab as well as on my local machine with a 3090 with varying batch sizes as well as fp16.
Thanks for your extensive reply Mat. Old (bs=32) times are shown in the blue background screenshot and new (bs=16) times are shown in the dark grey background screenshot. Would like to talk with you about learning rate later.
Why your free colab running the same code is 3x faster than mine seems to remain inconclusive, I’m wondering if free colab speed is impacted by user location.
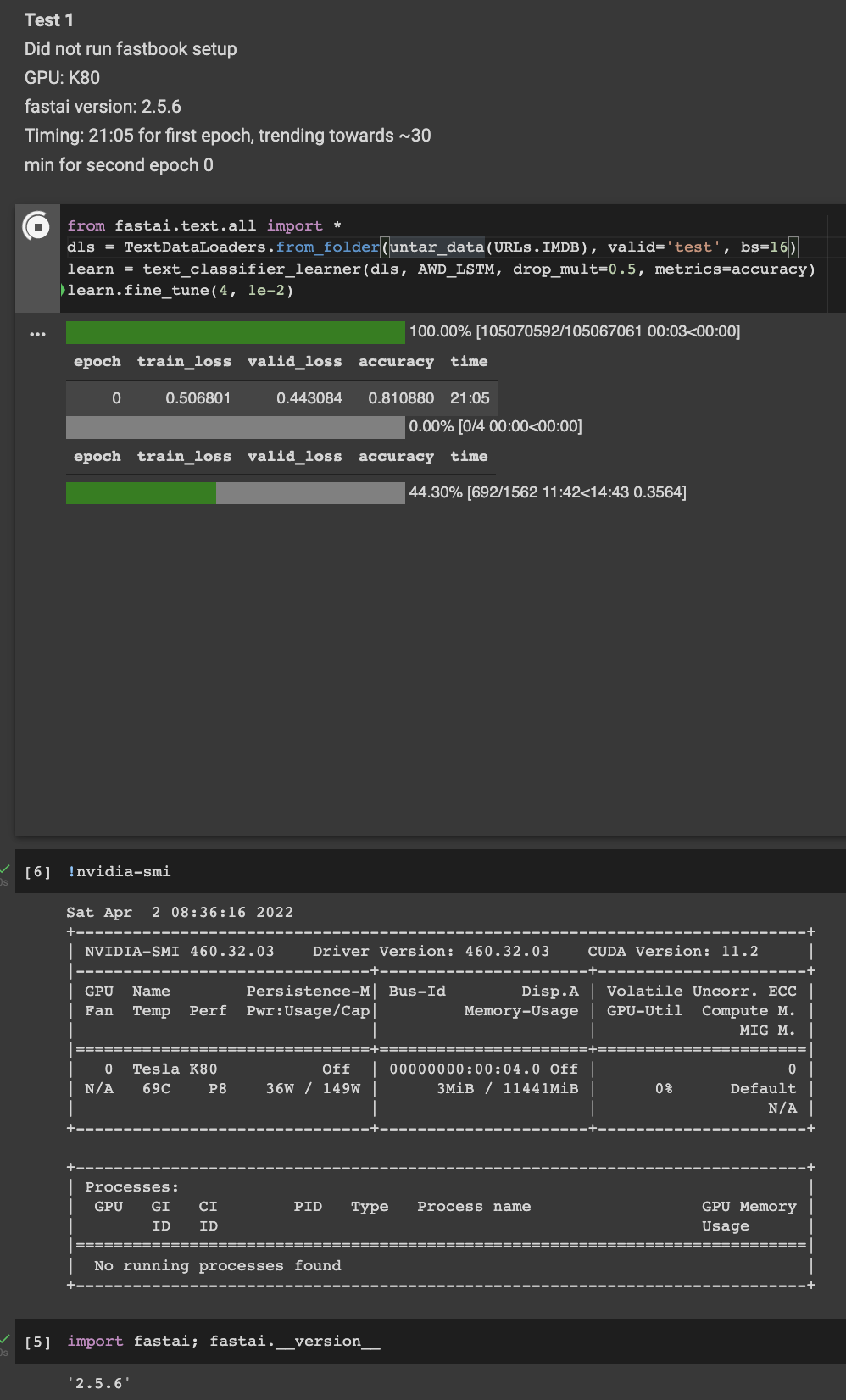
I ran another test. This time around I checked what GPU I was assigned and can confirm it was a K80. I did not check last time, but I suspect I might have been assigned a T4 last time as the runtime was much faster during my last benchmark. I suspect this may be what you’re experiencing. You can check which gpu you’re getting by running !nvidia-smi. The epoch time I got this time was pretty close to what you were observing in your latest run. Google randomly assigns GPU’s based on what they have available so you won’t know what you’re going to get each time you use Colab. They do mention if you use the paid Colab version you get priority access to better GPU’s, but I still don’t think it’s guaranteed what you’ll get.
I tried with/without running fastbook.setup_book() and that didn’t seem to make much of a difference. Note I am not allowing the connection to my gdrive when i run the setup_book function. It’s possible that may make a difference too if the dataset is loaded to gdrive vs it being downloaded to your colab machine directly. I have not confirmed whether or not this actually happens, just speculating, but I would expect gdrive to be slower than the disk attached to the colab VM instance. There are also some additional torch cudnn settings that are configured when running setup_book so that may make a difference too but I didn’t notice them making a difference in this case.
I noticed that you had a comment that you lowered the batch size because you ran out of GPU Ram. I would not expect this to be happening with either a K80 or T4 using the default batch sizes when you’re only running the block of code you specified by itself. If you were running some of the other code in the notebook ahead of time and it was holding onto GPU ram then that may have been why you were running out of GPU ram.
I tried to run a test again later and this time I was assigned a T4. It is much faster than the K80. That’s probably the time difference you’re noticing. If you do get a T4 you can use fp16 computation which allows for larger batch sizes due to a lower amount of memory consumed vs fp32 which is the default and faster computation. I think you may be able to get lower memory utilization on a K80 with fp16 , but it does not have tensor cores so you won’t see a speedup you observe with tensor cores.
I did a quick test of the text_classifier_learner step and with a K80 GPU it did 2 epochs at 14 min each. I tried it with a TPU backend and it’s projecting about 1:30:00 (1 hour and 30 min) per epoch.
At this rate I think an old 1070ti is still better than the free option on google colab because it definitely affords more room to maneuver and the machine I have can be rigged up for about 1000-1500 dollars with bumped up memory, an SSD and a 1070 or even a 3060 card for a much better, on demand performance.