I think what I was trying to say was that I was surprised that a 1070ti was only 4-5x slower.
I guess I had some (rather naïve) notion in my head that a 3090 with “so many cores” would be ‘exponentially’ better … and so the thing that surprised me a bit was that the relationship is almost linear (~5x perf for ~5x cores … for not ~5x power draw actually)
But you are absolutely right, 4-5x is quite dramatic especially for the bigger jobs, and I think that’s where cards like 3090 (and soon 4090) shine with their faster, larger VRAM stores and the ability to transfer more data in less time off main RAM and disk storage.
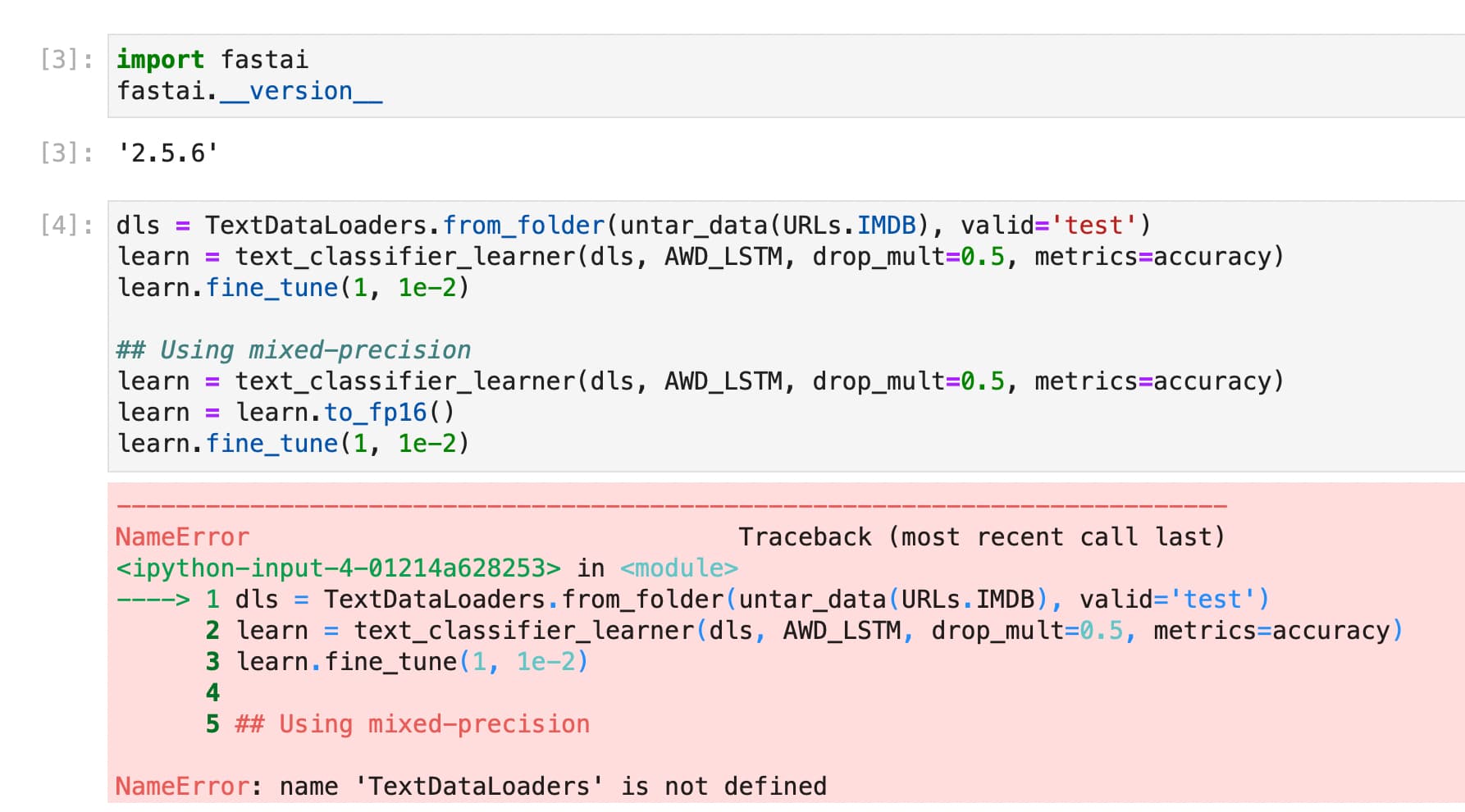
I’m getting the following error running the text classifier code from above. I have updated to the latest version of Fastai locally(2.5.6) so I’m not sure what the issue is…Any thoughts on what this could be?
It works for me when I do “from fastai.text.all import *” before creating the dataloader. Just importing the fastai doesn’t seem to do it for me either.
Hey folks,
would you please run the Jeremy’s NLP starter notebook (kaggle) on your local server?
The training cell takes 57 seconds to complete on the a6000 (250W, linux) and 7:44 minutes to complete on the 2060 Super (WSL2).
I’m curious about your results.
I’m trying to run it locally and I set my creds and installed kaggle but I get an error . I noticed the notebook doesn’t import anything from the kaggle package. Do I need to import api or something?
4 if not iskaggle and not path.exists():
----> 5 api.competition_download_cli(str(path))
6 ZipFile(f'{path}.zip').extractall(path)
NameError: name 'api' is not defined
EDIT:
OK so I got it to work. The code in the notebook wasn’t creating the kaggle.json file properly (it was empty) and then I had to import kaggle in the cell where it downloads the data (where I got the error previously)
BUT
Now I’m getting tokz.tokenize("A platypus is an ornithorhynchus anatinus.")
AttributeError: 'SentencePieceProcessor' object has no attribute 'encode'
Well it is going through the container virtualization ‘layer’ as it were, but still, I would’ve expected it to be faster as the onboard RAM is faster though it has about 400 less cuda cores than 1070ti. Plus the 1070ti system has DDR3 system RAM.
sentencepiece 0.1.96 worked for me too. I’d do a lookup and see if your system is picking up a legacy installed version of the lib? other than that I’m out of ideas.