Use this thread to discuss anything you like regarding lesson 5, including more advanced topics or diversions.
1 Like
What might be some interesting papers discussing neural net architectures for dealing with tabular data?
6 Likes
How to use other pretrained model that is not available in torchvision.models or fastai models. for example MobileNet?
4 Likes
You can pass any Pytorch model directly to Learner
1 Like
thank you! is there any tutorial on how this should be done? thanks again!
To take an example of another pytorch library, I’ll use pretrained-models.pytorch (https://github.com/Cadene/pretrained-models.pytorch).You should be able to do:
data = ...create your databunch...
# create model according to pretrained-models docs
model_name = 'nasnetalarge' # could be fbresnet152 or inceptionresnetv2
model = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
learn = Learner(data, model)
... do training
That should work in any case where model is a pytorch model. If it doesn’t you should report it here.
11 Likes
I haven’t tested this codebase, but would that RMSE of 0.836 (MSE of 0.7) be possible to get with fastai on the movielens 100K dataset?
Or is that low RMSE in that repo simply a bug in the code? It seems that most papers list a floor for the movielens 100k that’s close to the 0.9 RMSE of librec.
I see a larger variation for published results of the movielens 1M and 10M datasets. One of the lowest RMSE for that dataset is here:
Are there times when we’d want to use PCA on the input dataset before training the model, assuming there’s sufficient memory and computational power available?
I don’t think you’d want to do that–PCA is used for dimensionality reduction, and the point of training the neural net is that it can learn a way to reduce the dimensions of your input dataset based on the data itself, rather than more general methods like PCA.
3 Likes
@sgugger, can you please explain this briefly, or point me to explanation? Thanks
Referring to why Batchnom replaces bias after convolutions in resnet I guess.
Batchnorm is computing a running mean and a running std of the weights and normalize the activations with it. If you had some bias, it will get nullified in the running mean. BatchNorm basically does more than a bias (since it normalizes with the std on top of the mean thing).
6 Likes
By reducing dimensionality of the features, PCA could potentially reduce compute power required in the downstream phases of model development. The tradeoff is you lose some information that is in the full feature set.
1 Like
This paper also lists a believable 0.89 RMSE (MSE of 0.794) for the movielens 100k dataset.
Weight decay
Hello,
Andrew NG, in his course of Machine learning, mentioned that we do not do weight decay to biases, so loss function should only include weight matrices not the bias.
Is what model.parameters returns, does it return the bias as well, so we are doing weight decay with all parameters including bias?
Also, why we would need to decay the bias?
Regards
Ibrahim
7 Likes
I will like to know more about the 1/3 multiplier by default on the differential learning rates please  .
.
1 Like
Wondering how embeddings for unseen data was computed, I dig into fastai library. For each column, fastai adds an extra category for unknown values, with its corresponding embedding vector. However, it is not clear to me how the weights of the embedding vector for the unknown category are computed. I would expect it to be the mean or the median of the others embeddings vectors, but it is not. Visualizing the weights of the embedding vector before and after training, weights slightly changes, but basically remain close to the random initialized weights.
Since it doesn’t seem to be computed as the mean/median of the other vectors after the training, I wonder:
- Does it make sense to leave it with the (close to) random initialized values?
- Why the weights slightly changes if there is no unknown data in the training set? How can something backprop (and update) to an unseen category?
This is the code than I run based on lesson4-tabular:
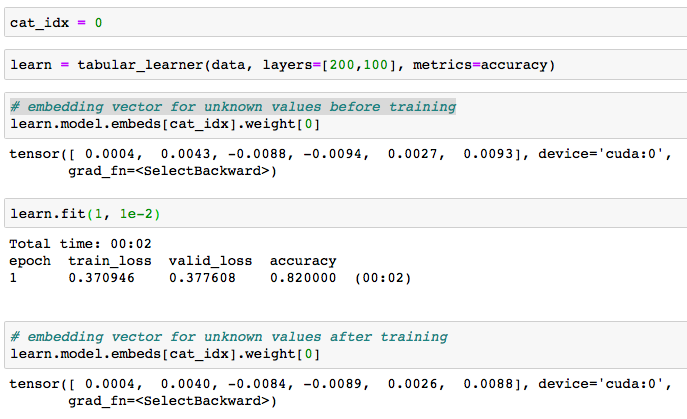
I’ll appreciate some clarification to better understand it. Thanks!
3 Likes
I’m not really aware of anything much beyond fully connected nets. Let me know if anyone here has come across anything interesting!
1 Like
It’s better to use create_cnn, so that fastai will create a version you can use for transfer learning for your problem.
4 Likes