I think they’re actually reporting MSE, based on their SVD++ number.
1 Like
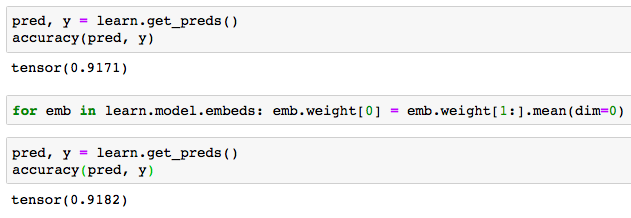
Following my previous post about the embedding vectors for unseen data, after training a tabular model, I manually set the weights of the embedding vectors of the unseen data equal to the mean of the others embedding vectors, achieving an increase in the accuracy (I don’t think it is just by chance).
I’d like to get some feedback, specially if any of you try it on your tabular model (specially with unseen categories in the valid set). It is just one line of code to update the weights of the embedding.
6 Likes
I think that’s a great idea! ![]()
5 Likes
What I’d like to try next is to apply a kind of mix between dropout and data augmentation for tabular data. Currently the embedding vector for unseen data seems not being trained… What if categorical variables are set randomly to 0 (unknown) during training? I guess this would help the model to learn to predict even with some unseen categories. I think this is different from regular dropout in three ways:
- Unlike embedding dropout that randomly drops the output of the embedding layer, the idea here is to randomly drop input values from categorical features, forcing the model to train using the embedding vector for unseen data instead.
- For each categorical variable, add a column to flag when the value of the category is unknown, either by “data augmentation/dropout” during training or actual unknown categories during validation/inference. The idea is that the model receives information when a value for the category is unknown, on top of the embedding vector for unseen data (similarly to “_na” fields when filling missing values).
- The “p” value (probability) of dropping out a categorical variable, would be eventually link to the probability of that variable being unknown in the validation set (it’d probably worth to train the model better to deal with categorical variables that are often missed in the validation set). Like Jeremy did when training language model, I hope this is not cheating using information from the features of the validation set for training.
I will try to implement it and will share the results.
4 Likes
Hi José,
I think this is a very interesting idea, and look forward to seeing your results.
I have a question though: how different would this be to applying dropout to the input layer?
If I understand correctly what you are proposing is to kind of apply dropout to inputs to the embedding layer, to make those embeddings more robust. You might be interested in comparing 3 approaches: 1) no dropout applied, 2) apply dropout to all inputs to the NN, or 3) apply dropout to categorical data only. Just a thought.
1 Like
Thank you Ignacio for your feedback.
As you mentioned it is a kind of dropout to inputs, however some tweaks were required to make it work with categorical variables, including:
- Applying regular dropout to a categorical variable, I think it’s kind of too aggressive, since it is not just making zero some inputs, but changing the category itself, and so using completely different values from the embedding layer. In order to mitigate it, I include a flag for each category indicating whether the category is unknown or not, so the model is receiving extra information to deal with it.
- Dropout was applied discriminatively by variable, based on the % of unknown values in the validation set, to put more effort on variables that are often unknown.
- Regular pythorch dropout seems not to work with integer values, so a custom dropout function was required to make it work with embeddings.
The final result seems slightly better than training the regular model. However, it is not clear if it is just due to the training stochasticity. My toy dataset is quite simple and doesn’t have significant unknown values. Once Jeremy introduces Rossmann dataset in class, I will benchmark on it, anyway I am not aiming to invent anything, but taking these experiments as a way to learn and practice. 
1 Like
Thanks a lot for the detailed response, José!
I think it’s a very creative idea.
It’ll be interesting to see the results you get.
Un saludo!
1 Like
Very sensible. We already use category code 0 for #na, so you can actually do this right now! ![]()
1 Like
I’m making model where accuracy is top_3_accuracy. So i’m taking top 3 predictions as a result and if one of those is correct then it is same as predicting correct accuracy metric. Currently my predictions are like [0.02,0.04,0.93,0.01] because of cross entropy. How I can do this for three numbers. Like three bigger numbers and others less. I think that might make model better.
You can try:
pred_top3 = pred.topk(k=3, dim=1)[1]
acc = torch.stack([(p==y).any() for p,y in zip(pred_top3, y)]).float().mean()
Hope this helps.
3 Likes
Hello! I tried your code, but it fails with error:
TypeError: conv2d(): argument 'input' (position 1) must be Tensor, not bool
I have the latest fastai 1.0.28
1 Like
Sounds like a good research topic to me, especially since we seem to have established that tabular models could use more research. Thank you for sharing this meaningful contribution!
1 Like
Sorry to chime in late. Don’t you also lose what part of the feature set is lost. For instance if you reduce 10 features to 2 - you don’t know which of the 10 were dropped right ?
Actually @pbanavara you do know; PCA (principal components analysis) forms a set of new features that are independent linear combinations of the original input features, and keeps only those new features that have the strongest effect. The idea is, you gain a simpler model at the expense of some information loss. If you want to, you can find out exactly which new features have been dropped. However, in most cases it would be difficult to interpret these dropped features.
In this paper they use attention mechanism to outperform factorization machines.
Happy to discuss – https://arxiv.org/abs/1810.11921
2 Likes
Hi,
I am looking for resources to get started on processing 3D images. As a simple 3D image categorization task but I am not sure where to get started. I found 3D mnist data. Will the same principles that we have been using to identify the right learning rate work for 3D images as well.
I’m still stuck at how should I use fastai collaborative filtering learner to recommend in production. anyone have any end-to-end example ? I already trained it but I’m not sure how should I use it
Update: I could make it work. My next post will describe how.
=================================================
I am trying to import models from the Cadene Pytorch model libraries.
I am trying for 2 days to make create_cnn working, but seems only learn = Learner(data, model) works. create_cnn is much better, but there is something I am missing. I understand that create_cnn expects a callable function and tried the following examples.
Here are working examples:
# this works
def get_model(pretrained=True, model_name = 'resnet50', **kwargs ): # pretrained key should be the first
arch = models.resnet50(pretrained, **kwargs )
return arch
learn = Learner(data, get_model(), metrics=[accuracy])
# this works
def get_model(pretrained=True, model_name = 'resnet50', **kwargs ): # pretrained key should be the first
arch = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
return arch
learn = Learner(data, get_model(), metrics=[accuracy])
Here are not working examples:
# this does not work
def get_model(pretrained=True, model_name = 'resnet50', **kwargs ): # pretrained key should be the first
arch = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
return arch
learn = Learner(data, get_model, metrics=[accuracy])
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-45-814e6d5c8795> in <module>
4 return arch
5
----> 6 learn = Learner(data, get_model, metrics=[accuracy])
<string> in __init__(self, data, model, opt_func, loss_func, metrics, true_wd, bn_wd, wd, train_bn, path, model_dir, callback_fns, callbacks, layer_groups)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/basic_train.py in __post_init__(self)
145 self.path = Path(ifnone(self.path, self.data.path))
146 (self.path/self.model_dir).mkdir(parents=True, exist_ok=True)
--> 147 self.model = self.model.to(self.data.device)
148 self.loss_func = ifnone(self.loss_func, self.data.loss_func)
149 self.metrics=listify(self.metrics)
AttributeError: 'function' object has no attribute 'to'
# this does not work
def get_model(pretrained=True, model_name = 'resnet50', **kwargs ): # pretrained key should be the first
arch = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
return arch
learn = create_cnn(data, get_model(), metrics=[accuracy])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-43-74cb1e5cde9c> in <module>
4 return arch
5
----> 6 learn = create_cnn(data, get_model(), metrics=[accuracy])
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/vision/learner.py in create_cnn(data, arch, cut, pretrained, lin_ftrs, ps, custom_head, split_on, bn_final, **kwargs)
53 "Build convnet style learners."
54 meta = cnn_config(arch)
---> 55 body = create_body(arch, pretrained, cut)
56 nf = num_features_model(body) * 2
57 head = custom_head or create_head(nf, data.c, lin_ftrs, ps=ps, bn_final=bn_final)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/vision/learner.py in create_body(arch, pretrained, cut, body_fn)
30 def create_body(arch:Callable, pretrained:bool=True, cut:Optional[int]=None, body_fn:Callable[[nn.Module],nn.Module]=None):
31 "Cut off the body of a typically pretrained `model` at `cut` or as specified by `body_fn`."
---> 32 model = arch(pretrained)
33 if not cut and not body_fn: cut = cnn_config(arch)['cut']
34 return (nn.Sequential(*list(model.children())[:cut]) if cut
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/pretrainedmodels/models/torchvision_models.py in forward(self, input)
338
339 def forward(self, input):
--> 340 x = self.features(input)
341 x = self.logits(x)
342 return x
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/pretrainedmodels/models/torchvision_models.py in features(self, input)
320
321 def features(self, input):
--> 322 x = self.conv1(input)
323 x = self.bn1(x)
324 x = self.relu(x)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/conv.py in forward(self, input)
318 def forward(self, input):
319 return F.conv2d(input, self.weight, self.bias, self.stride,
--> 320 self.padding, self.dilation, self.groups)
321
322
TypeError: conv2d(): argument 'input' (position 1) must be Tensor, not bool
# this does not work
def get_model(pretrained=True, model_name = 'resnet50', **kwargs ): # pretrained key should be the first
arch = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
return arch
learn = create_cnn(data, get_model, metrics=[accuracy])
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-44-86a48fcf2401> in <module>
4 return arch
5
----> 6 learn = create_cnn(data, get_model, metrics=[accuracy])
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/vision/learner.py in create_cnn(data, arch, cut, pretrained, lin_ftrs, ps, custom_head, split_on, bn_final, **kwargs)
54 meta = cnn_config(arch)
55 body = create_body(arch, pretrained, cut)
---> 56 nf = num_features_model(body) * 2
57 head = custom_head or create_head(nf, data.c, lin_ftrs, ps=ps, bn_final=bn_final)
58 model = nn.Sequential(body, head)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/callbacks/hooks.py in num_features_model(m)
115 def num_features_model(m:nn.Module)->int:
116 "Return the number of output features for `model`."
--> 117 return model_sizes(m)[-1][1]
118
119 def total_params(m:nn.Module)->int:
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/callbacks/hooks.py in model_sizes(m, size)
110 "Pass a dummy input through the model `m` to get the various sizes of activations."
111 with hook_outputs(m) as hooks:
--> 112 x = dummy_eval(m, size)
113 return [o.stored.shape for o in hooks]
114
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/fastai/callbacks/hooks.py in dummy_eval(m, size)
105 def dummy_eval(m:nn.Module, size:tuple=(64,64)):
106 "Pass a `dummy_batch` in evaluation mode in `m` with `size`."
--> 107 return m.eval()(dummy_batch(m, size))
108
109 def model_sizes(m:nn.Module, size:tuple=(64,64))->Tuple[Sizes,Tensor,Hooks]:
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
---> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai-v1/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
563 def forward(self, input):
564 return F.avg_pool2d(input, self.kernel_size, self.stride,
--> 565 self.padding, self.ceil_mode, self.count_include_pad)
566
567
RuntimeError: Given input size: (2048x2x2). Calculated output size: (2048x-4x-4). Output size is too small at /opt/conda/conda-bld/pytorch_1544202130060/work/aten/src/THNN/generic/SpatialAveragePooling.c:48
A working example shared here to import any Cadene model is very helpful. It will expand the usable models in fastai for everybody. I heard in Kaggle competitions that there are people could make it work with fastai v1, but could not do it myself. Here is an 8th Kaggle winner in Human Protein Atlas comp. that just did that!
2 Likes
Here is my code importing resnet50 from Cadene Pytorch pretrained models repo. I used resnet50 to make sure that I did not make any mistake which can be validated by comparing it with a normal fastai resnet50 method. The below code can give you access to ~45 models most of them still not available in fastai by simply changing the model’s name.
pretrainedmodels should be installed by:
pip install pretrainedmodels
Our lesson-1 example using pretrained models import:
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai import *
from fastai.vision import *
import pretrainedmodels
path = untar_data(URLs.PETS); path
path_anno = path/'annotations'
path_img = path/'images'
fnames = get_image_files(path_img)
np.random.seed(2)
pat = re.compile(r'/([^/]+)_\d+.jpg$')
bs = 64
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(),
size=299, bs=bs//2).normalize(imagenet_stats)
def get_model(pretrained=True, model_name = 'resnet50', **kwargs ):
if pretrained:
arch = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')
else:
arch = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained=None)
return arch
custom_head = create_head(nf=2048*2, nc=37, ps=0.5, bn_final=False)
# Below you can change the imported model into any of the models available in the `pretrainedmodels`
# which can be shown by: pretrainedmodels.model_names
fastai_resnet50=nn.Sequential(*list(children(get_model(model_name = 'resnet50'))[:-2]),custom_head)
def get_fastai_model(pretrained=True, **kwargs ):
return fastai_resnet50
learn = create_cnn(data, get_fastai_model, metrics=error_rate)
learn.fit_one_cycle(5)
learn.unfreeze()
learn.fit_one_cycle(1, max_lr=slice(1e-6,1e-4))
Update-1:
Maybe it is safer to create the custom_head as the following:
custom_head = create_head(nf=num_features_model(self.cnn)*2, nc=data.c, ps=0.5, bn_final=False)
Just in case the output features of the body of a model that you will use is not 2048
Update-2:
Jeremy tweeted an even better implementation for importing architectures from cadene. What I missed in the above code, the points of split for the discriminative learning.
16 Likes
Looking for an answer to your point 2. That makes me wonder, the weights would not change much if a level in a variable doesn’t appear many times in the dataset.