Thanks for this excellent contribution, Haider @hwasiti I plan to try some of these as I progress further into modeling.
1 Like
@sgugger Some of my friends asked me to make pull request to include those pretrained models into fastai.
There are a lot of models claimed to be better on the imageNet benchmark than ResNet which I could import them into fastai using this simple code.
Any chance that you will add them to fastai in the future? or can I make a pull request but then where exactly in the library should I make the changes to add them?
2 Likes
i have learnt that if we pass lin_ftrs=[1024] then soon after adaptive create cnn will create Linear layers with no of Inputs as we put in the list… so we dont need toput our own custom head ,if our requirement is just to change the last Fc layer features with output as no of classses for various trained models…
2 Likes
@jeremy I had some trouble with your macro in the basic worksheet, with the last line in your onestep subroutine. It kept giving me a 400 error. I fixed it with the following changes. First, I changed the subroutine to accept an integer as an argument:
Sub onestep(ByVal i as Integer)
Then, I changed the last line to
Range("msestart").Offset(i, 0).PasteSpecial Paste:=xlPasteValues
And calling the subroutine is then simply
For i = 1 To 5: onestep (i): NextThanks for the post! The link you provided in the second update is a really nice reference. I was able to get everything working on my end, though I had a one thing not working as expected:
Are arch_summary() and get_groups() Fastai methods? If so I think they’ve been replaced by something else or just removed completely. I can’t find anything on the docs. There’s other stuff in the github repo that isn’t updated with the most recent Fastai version, but those two seemed really nice to learn how these models are structured/setting layer groups.
Thanks again for the post!
@jeremy @sgugger How to use Collaborative filtering for the non-rating dataset.e.g. product recommendation based on transaction history. I used TuriCreate API.But, how to implement product recommendation problem based on the transaction in fastai?
Secondly, do fastai support various type of recommendations as present in TuriCreate API?
That’s pretty cool. Do you know of anyone using this in practice?
Thank you @jeremy for the excellent lecture. I have been thinking much about collaborative filtering and I have a few questions to ask.
-
In the example given, the item list in the collaborative filtering dataset does not necessarily need to be movies. It can be anything with a rating to it. Potentially one can put demographic or other user data in there (e.g. if the person is male, then the entry male can be made in the movie column with a rating of 5 to capture this) and the model can learn how these data can influence the user embedding. This may avoid requiring a separate tabular model to use demographic data for the cold start problem. I wonder if anyone has tried this approach?
-
The more interesting idea is to use collaborative filtering in medical diagnostics. Most patients only have a few diseases, and most diseases only affect a small proportion of patients, so this is not dissimilar to the movie recommendation problem. Potentially, if there is a dataset of a large number of patients with their diagnostic coding, then a collaborative filtering system can figure out if what diseases a patient may be most susceptible to given their previous diagnoses.
-
Collaborative filtering can also be used to impute missing values. This is again of importance in medicine as most patients will not have had all the tests / investigations that is available. Potentially as more information is known about a patient, a system can impute and predict test results that have not been performed.
Does anyone know if a collaborative filtering approach has been used in medical research / diagnostics?
Hi! I’m trying to implement a net as discussed in this lesson, but I’m getting the following error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-30-36d1490bd9f3> in <module>()
----> 1 losses = [update(x,y,lr) for x,y in data.train_dl]
/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in linear(input, weight, bias)
1404 if input.dim() == 2 and bias is not None:
1405 # fused op is marginally faster
-> 1406 ret = torch.addmm(bias, input, weight.t())
1407 else:
1408 output = input.matmul(weight.t())
RuntimeError: Expected object of scalar type Float but got scalar type Double for argument #4 'mat1'
I have checked out my datatypes and everything that I can find is a float, there are no doubles, so I’m confused as to what could be causing this error. Thoughts?
If it helps, I’ve figured out (via source diving), that mat1 here is the bias.
I’ve figured out my problem, when I run:
torch.tensor(some_array)
I get back a DoubleTensor when what I want is a FloatTensor. What is also strange is that if you print that tensor you will see its dtype is float64. Anyways, I’ve gotten around this by calling torch.tensor(some_array).float().
Sorry for the late reply.
Those should be imported from the utils.py (check out this file in the same repo):
from utils import *
BTW. the post for that notebook that I have referred with the link in the 2nd update:
I am uploading link to my hand-written notes on things you can do to improve your neural networks. I wrote these notes while doing deeplearning.ai specialization taught by Andrew Ng. Hope you find these useful. These notes cover in detail topics such as regularization, weight decay, adam optimization , momentum etc. These notes go well with the lesson 5 where Jeremy teaches about Adam optimizing algo ,weight decays,RMSprop etc.
https://drive.google.com/open?id=1dXjZ2boL5pqvxSB7J-zLEdCbTo7XL8MO
2 Likes
THIS.
Jeremy skims through most concepts direct to the objective truths accepted by today’s standards. Although Adam was substantially RMSprop and momentum, It was difficult trying to grasp and mental picture/intuition on how each one specifically works. Thus, although supplementary, I recommend everyone to read through(ie: googling) anything remotely blurry because there are underlying concepts best explored in texts and publications rather than classrooms. 
In lesson 5 Jeremy advises us to write our own adam optimizer. Here is how I implemented the adam
#Intialising matrices for momentum and rms
mom = {}
rms = {}
i = 0
for p in model.parameters():
mom[i] = torch.zeros(p.shape)
rms[i] = torch.zeros(p.shape)
i+=1
def update(x,y,lr,wd = 0.03, beta1 = 0.9,beta2 = 0.999,epsilon = 1e-08):
y_hat = model(x)
w2 = 0.
for p in model.parameters(): w2 += (p**2).sum()
loss = loss_func(y_hat,y) + wdw2
loss.backward()
i = 0
with torch.no_grad():
for p in model.parameters():
mom[i] = beta1mom[i] + (1-beta1) * p.grad
rms[i] = beta2*rms[i] + (1-beta2) * (p.grad **2)
p.sub_(lr * (mom[i]/((rms[i] + epsilon)**0.5)))
p.grad.zero_()
i += 1
return loss.item()
Hi @a_bhimany_u, I could not get your solution to work, please see below. As far as I understood, the problem is that mom[i] is a CPU variable while the model has been loaded to CUDA.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-37-36d1490bd9f3> in <module>
----> 1 losses = [update(x,y,lr) for x,y in data.train_dl]
<ipython-input-37-36d1490bd9f3> in <listcomp>(.0)
----> 1 losses = [update(x,y,lr) for x,y in data.train_dl]
<ipython-input-36-5e0bf8c84769> in update(x, y, lr, wd, beta1, beta2, epsilon)
18 with torch.no_grad():
19 for p in model.parameters():
---> 20 mom[i] = beta1*mom[i] + (1-beta1)*p.grad
21 rms[i] = beta2*rms[i] + (1-beta2)*(p.grad2)
22 p.sub_(lr * (mom[i]/((rms[i] + epsilon)**0.5)))
RuntimeError: expected type torch.FloatTensor but got torch.cuda.FloatTensor
Could you please share your working solution?
Thanks
hi @gabrielfior, I also got the same type of error while running the code. To troubleshoot this, I changed my runtime type from GPU to CPU in colab and initialised my model object as model = MyModel() instead of model = MyModel().cuda()
Hi @hwasiti,
Any update on how to do it?
I’ve downloaded the weights of a resnet50 pretrained on places365 (http://places2.csail.mit.edu/models_places365/resnet50_places365.pth.tar) and tried to follow Jeremy’s advice and i get this: t
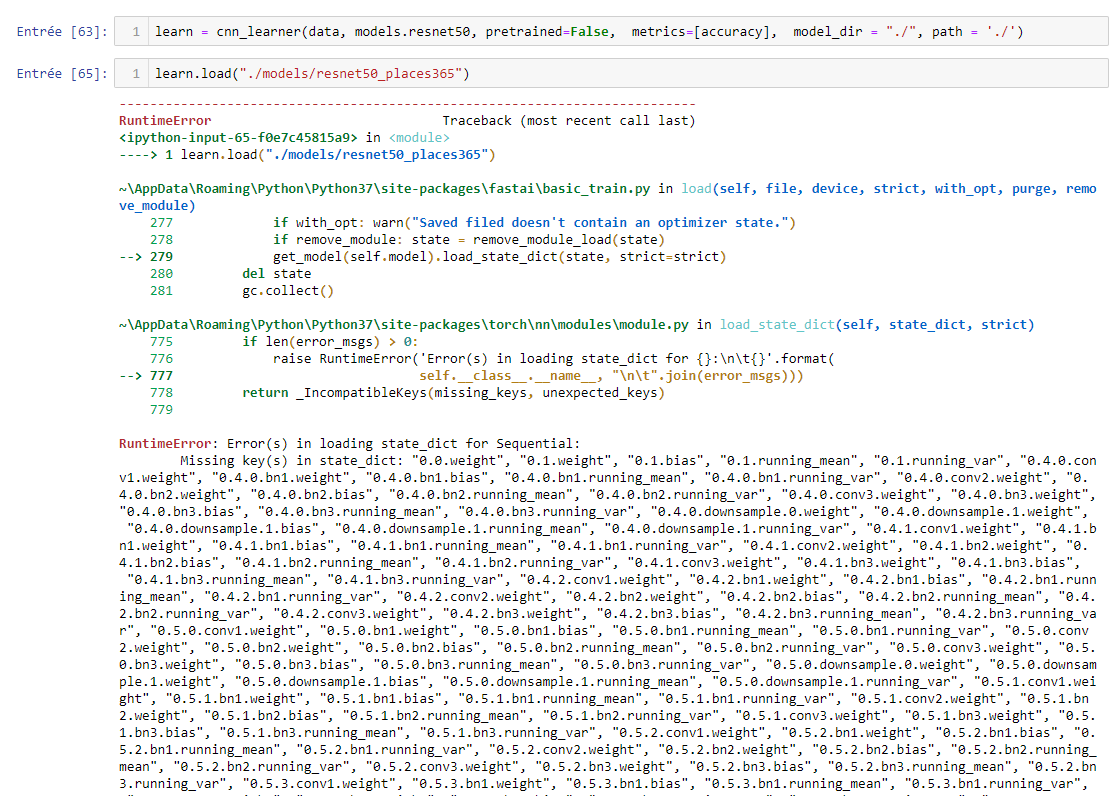
Thanks in advance
This really helped! Literally just made an account to thank you 
hi all,
thanks for excellent lecture. I’m a Swift developer and as a practice and to understand it better I try to implement things presented during the lecture in Swift for TensorFlow. This time I implemented MNIST SGD with weight decay. However, when I plot the loss alongside with the implementation without weight decay they look almost the same. Here is my implementation: https://gist.github.com/jkrukowski/1b40ef7fd3c12cd9c70fa44477644f48
I’d be grateful if anyone can verify if my implementation is correct, thanks!