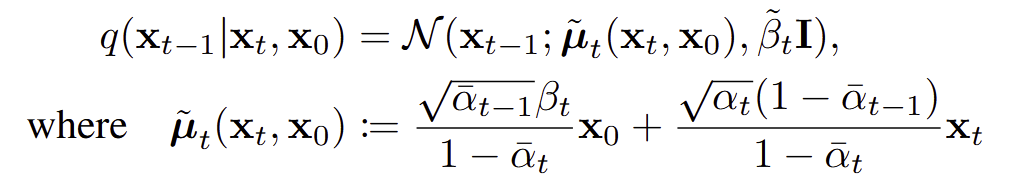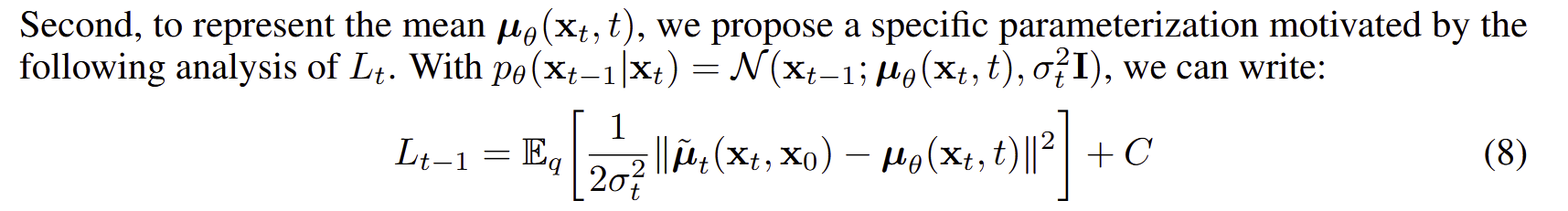This is a wiki post - feel free to edit to add links from the lesson or other useful info.
Lesson resources
- Lesson Videos
This is a wiki post - feel free to edit to add links from the lesson or other useful info.
On TTD_CB I would restore the original layer m state in after_epoch (ie: usually back to eval() for inference).
class TTD_CB(Callback):
def before_epoch(self, learn):
learn.model.apply(lambda m: m.train() if isinstance(m, (nn.Dropout,nn.Dropout2d)) else None)
@jeremy Thanks for the tip about updating the epsilon value for the optimizer! That actually resolved an issue I encountered where the gradients would go to nan in the second half of a training session in one of my personal projects.
Great lesson, thanks as always. Trivial question but is there a reason to change from AdamW to Adam between the last lesson and this one?
No. Since we’re not using weight decay, they’re identical.
Hey Folks,
Is it just me or did someone try to run notebook 15_DDPM and face an error? when you run learn.fit() using DDPMCB callback? Here is the stack trace -
`---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [9], in <cell line: 1>()
----> 1 learn.fit(epochs)File /mnt/c/users/aayus/Desktop/git/course22p2/nbs/…/miniai/learner.py:177, in Learner.fit(self, n_epochs, train, valid, cbs, lr)
175 with self.cb_ctx(‘fit’):
176 for self.epoch in self.epochs:
→ 177 if train: self.one_epoch(True)
178 if valid: torch.no_grad()(self.one_epoch)(False)
179 finally:File /mnt/c/users/aayus/Desktop/git/course22p2/nbs/…/miniai/learner.py:157, in Learner.one_epoch(self, train)
155 self.predict()
156 self.callback(‘after_predict’)
→ 157 self.get_loss()
158 self.callback(‘after_loss’)
159 if self.training:File /mnt/c/users/aayus/Desktop/git/course22p2/nbs/…/miniai/learner.py:186, in Learner.callback(self, method_nm)
→ 186 def callback(self, method_nm): run_cbs(self.cbs, method_nm, self)File /mnt/c/users/aayus/Desktop/git/course22p2/nbs/…/miniai/learner.py:50, in run_cbs(cbs, method_nm, learn)
48 for cb in sorted(cbs, key=attrgetter(‘order’)):
49 method = getattr(cb, method_nm, None)
—> 50 if method is not None: method(learn)File /mnt/c/users/aayus/Desktop/git/course22p2/nbs/…/miniai/learner.py:101, in TrainCB.get_loss(self, learn)
→ 101 def get_loss(self, learn): learn.loss = learn.loss_func(learn.preds, *learn.batch[self.n_inp:])AttributeError: ‘DDPMCB’ object has no attribute ‘n_inp’`
I have the most updated pull from course22p2 repo. Let me know if you spot something wrong.
Regards,
Aayush
n_inp was added to miniai recently. Make sure you’ve got the latest version.
When is lesson 20?
Today ![]()
oops, missed it. No problem, I will watch the recorded video.
Regarding last lesson, in Jupyter Notebook if you use latex math like \alpha and hit TAB, it will transform it to the corresponding UTF char.
This issue persists in the latest version. The problem seems to be that the __init__ method for the DDPMCB class isn’t running super().__init__(). Adding this line fixes the issue.
Many thanks - will fix now.
Training the UNet fails on an M1 Mac, as group normalisation seems to not yet be implemented for the MPS device. Falling back to CPU (using PYTORCH_ENABLE_MPS_FALLBACK=1) causes the Python process to crash.
I may have to run the notebooks on Colab rather than locally.
Trying to follow the original paper for the sampling process I am struggling to see how the xo and xt coefficients are derived. I can see that x_0_hat corresponds to equation 15 in the paper and is a way to get to x0 in one step. I was expecting that the x0 and xt coefficients would follow the equation in step 4 of the sampling (Algorithm 2) in the same way that the training stage follows Algorithm 1, however, it doesn’t seem to. As mentioned in the lesson, instead it takes a weighted average of the predicted x0 and the current xt. I understand this but can’t see where the calculation of the coefficients comes from.
Probably me not understanding the paper well enough but if anybody can help explain it would be great
The coefficients come from the equation for q(\mathbf{x}_{t-1} | \mathbf{x}_{t}, \mathbf{x}_{0}):
The loss function math demonstrates that the mean of our reverse process distribution should match the mean of q(\mathbf{x}_{t-1} | \mathbf{x}_{t}, \mathbf{x}_{0}) :
Therefore, our model must learn to predict \tilde{\mathbf{\mu}}_t, which it does by predicting the noise to remove from \mathbf{x}_t to get an estimate of \mathbf{x}_0 which we plug into that equation for to finally get our mean \tilde{\mathbf{\mu}}_t for q(\mathbf{x}_{t-1} | \mathbf{x}_{t}, \mathbf{x}_{0}).
Hope this is clear! Let me know if you have any other questions!
Thanks Tanishq, I can see where the coefficients come from now but I am still struggling with the interpretation. I can see from equation 7 in the paper that what you are generating as x_t in the code is equivalent to the calculated \tilde{\mu}_t(x_t,x_0) plus the standard deviation at that time step multiplied by the generated random noise. I am not sure why this can then be interpreted as x_{t-1}?
Great lesson again thanks everyone. Is it just me or is the audio for the great explanation by @ilovescience (Inheriting from miniai TrainCB onwards) a bit dodgy?
It’s not just you. I’ve been nagging Tanishq about upgrading his mic setup so this feedback is most helpful! ![]()
The n_inp issue is still presented in course22p2/15_DDPM.ipynb at master · fastai/course22p2 · GitHub
class DDPMCB should have super().__init__()