This is a wiki post - feel free to edit to add links from the lesson or other useful info.
Lesson resources
- Lesson Videos
Links from the lesson
- The course’s fashion mnist challenge topic
- Excel optimisers spreadsheet
- Papers
- Papers with Code
This is a wiki post - feel free to edit to add links from the lesson or other useful info.
When we do self.schedo = self.sched , isn’t there is a risk that modifying self.schedo would change self.sched. Or is that intended to happen?
We don’t do that - we do self.schedo = self.sched(learn.opt), which calls the sched callable to create the object.
oh ok. Yeah, that makes sense now. Thanks.
Going through the lesson again, I’ve noticed that we don’t pass the norm to the _conv_block in the ResBlock, so this awesome result is without batchnorm.
class ResBlock(nn.Module):
def __init__(self, ni, nf, stride=1, ks=3, act=act_gr, norm=None):
super().__init__()
self.convs = _conv_block(ni, nf, stride, act=act, ks=ks) # This line is missing norm=norm
Fixing the issue gives lower result of 0.918 (without norm it was 0.922), but I haven’t played with lr yet.
Oops! Well spotted.
I still get 0.922 after fixing it FYI.
Fixing the batchnorm problem, and then removing the line that inits conv2 bn weights to zero, results in all the models I’ve tried so far getting better results.
I’ve updated the “leaderboard” topic with the latest results now:
Regarding calculating flops for models, I discovered that the fvcore library includes a flop counter for PyTorch models.
What blows my mind watching this : the weights are all initialised from random parameters and they all converge in a few epochs to such a high level of accuracy, not to mention the fully handrolled training loop and model architecture. ![]()
I’m currently in lesson 17 and it’s just excellent! After seeing your comment, I can’t stop myself from watching lesson 18 ![]()
As Jeremy mentioned, the proposed homework for this lesson was indeed a great learning exercise. I had to review Part 2 to practice what we have been taught about Python, PyTorch and miniai. And it ended being inspired on fastai’s scheduler.
It implements for SchedCos, SchedExp, SchedExpFastai, SchedLin, SchedNo, SchedPoly.
It is also possible to combine schedulers with CombineScheds and has OneCycleSched and FlatCosSched.
Here the notebook:
Update: I like using the module summary tools included with TorchEval more than the fvcore library. You can convert the markdown table to a Pandas DataFrame to make it easily filterable.
def markdown_to_pandas(table_string):
rows = table_string.strip().split("\n")
header = rows[0].split("|")[1:-1]
header = [x.strip() for x in header]
data = [row.split("|")[1:-1] for row in rows[2:]]
data = [[x.strip() for x in row] for row in data]
return pd.DataFrame(data, columns=header)
test_inp = torch.randn(1, 3, *[train_dataset.size]*2).to(device)
summary_df = markdown_to_pandas(f"{get_module_summary(style_transfer_model, [test_inp])}")
summary_df[(summary_df.index == 0) | (summary_df['Type'] == 'Conv2d')]
Generates to the following table:
| Type | # Parameters | # Trainable Parameters | Size (bytes) | Contains Uninitialized Parameters? | Forward FLOPs | Backward FLOPs | In size | |
|---|---|---|---|---|---|---|---|---|
| 0 | TransformerNet | 393 K | 393 K | 1.6 M | No | 6.9 G | 13.6 G | [1, 3, 512, 512] |
| 3 | Conv2d | 448 | 448 | 1.8 K | No | 113 M | 113 M | [1, 3, 514, 514] |
| 6 | Conv2d | 136 | 136 | 544 | No | 33.6 M | 67.1 M | [1, 16, 512, 512] |
| 11 | Conv2d | 528 | 528 | 2.1 K | No | 33.6 M | 67.1 M | [1, 32, 256, 256] |
| 18 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 22 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 28 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 32 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 38 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 42 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 48 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 52 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 58 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 62 | Conv2d | 36.9 K | 36.9 K | 147 K | No | 603 M | 1.2 G | [1, 64, 130, 130] |
| 66 | Conv2d | 16.5 K | 16.5 K | 66.0 K | No | 268 M | 536 M | [1, 128, 128, 128] |
| 71 | Conv2d | 4.2 K | 4.2 K | 16.6 K | No | 268 M | 536 M | [1, 64, 256, 256] |
| 77 | Conv2d | 435 | 435 | 1.7 K | No | 113 M | 226 M | [1, 16, 514, 514] |
Two new optimisers were recently published Lion (Chen 2023) and dadaptation (Defazio 2023). Both need a bit more epoch to get good results but are very competitive with AdamW.
I had a deeper look at Lion, it is simpler, faster, smaller than Adam or DAdaptAdam.
It exposes a somehow hidden fact that Adam when things go well updates parameters with learning rate ignoring the gradient scale, and lion makes it explicit.
Have a look how easy it is (the code updates only one parameter for simplicity):
def sgd(lr): # for comparison with lion
def sgd_step(w, g):
return w - lr * g
return sgd_step
def lion(lr=0.1, b1=0.9, b2=0.99):
lion.exp_avg = 0 # shared state betwen multiple calls to lion_step
def lion_step(w, g):
sign = np.sign(lion.exp_avg * b1 + grad * (1 - b1)) # s is 1 or -1
lion.exp_avg = lion.exp_avg*b2 + (1-b2)*g
return w - lr * sign
return lion_step
@Mkardas made a nice notebook exploring how those optimisers work with one variable I will share it here once we get it polished.
‘fastai native and fused ForEach implementations’ are also available in Benjamin’s (@ bwarner) fastxtend fastxtend - Lion: EvoLved Sign Momentum Optimizer
Hi all,
Would someone be able to walk through how to calculate the number of parameters for the first layer of the resnet models at about 1h:20m in and 1h:30m in? I went back to the convolutions excel but wasn’t able to piece it together (think I’m having trouble conceptualizing how the resnet addition increases number of params).
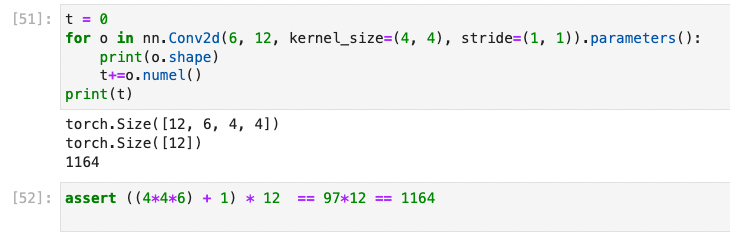
I.e. what’s the math to get to 680 params for the first layer of the first example and 6864 params for the first layer of the second example.
Thanks!
@pack765 A simple way to calculate the number of params is ((kernel * ni ) + 1 ) * nf . The demo below might help understand this .
I’ve written a blog post attempting to explain annealing and an implementation of Cosine Annealing using the LRFinder(). I would appreciate any feedback on how to improve it or the website. https://the-learning-mechanic.github.io ![]()