In case this helps anyone, here’s the code I wrote while figuring out how resnet works. It’s more verbose but hopefully there’s a bit more info in case anyone is stuck.
I recommend reading the forward pass method first then go back and check init.
def noop(x, *args, **kwargs):
return x
class ResBlock(nn.Module):
def __init__(self, ni, nf, ks=3, stride=2, act=nn.ReLU, norm=None, bias=None):
super().__init__()
# Residual path
self.convs = _conv_block(ni, nf, ks=ks, stride=stride, act=act, norm=norm, bias=bias)
# Skip path/ shortcut path
# Here we just decide what functions need to apply to the input
# to allow the shapes to work out so that it can be to be added to the
# output of self.convs / the residual path
if ni == nf:
#if the number of input channels = number of output channels, no need to conv the input to math the output from residual path
self.idconv = noop
else:
# if not then make the simplest conv that can math input shape to output of residual path
self.idconv = conv(ni, nf, ks=1, stride=1, act=None)
if stride == 1:
# If the residual path does not change the height and width of the image then no need to change height
# and width of input to allow it to be added at the end
self.pool = noop
else:
self.pool = nn.AvgPool2d(2, ceil_mode=True) # not sure why ceil_mode
self.act = act()
def forward(self, inp):
# Calculate residual path
res = self.convs(inp)
# Fix shape of skip path
skip = self.idconv(self.pool(inp)) # no change if ni==nf and stride=1. I wonder - does the order matter i.e. pool first then idconv? Need to check shapes
# Apply activation function
out = self.act(res+skip)# This is the step that needs the idconv and pool ops in case of shape mismatch
return out
I wrote a blog about optimizers (SGD, RMSprop, and Adam).
I wanted to graph gradients like how we did with weights, so I used backward hooks. I wanted to implement classes like we did in the course, but they did not work very well for me.
Adam does have more stable gradients than SGD and RMSprop, so it was interesting to look at that. I originally wanted to track other parameters like beta1 and beta2 as well, but I could not figure out how to do that easily. I will probably do it later.
I don’t understand why the last layer of the resnet model is a nn.BatchNorm1d(10) (in the 13_resnet.ipynb notebook). Why did it change ? Why are we not using softmax here as we used to do ?
Thank you for your answer . My bad I’m following the lecture using another language and got confused. My understanding is that the softmax activation (or similar) is required for the cross entropy loss function and I guess the pytorch one performs the softmax before computing the loss so no need to have this activation in the network.
Hi, I wrote about Resnet in my blog. I went over the paper and wrote the code version.
In the second part, I trained the model using different kinds of convolutional blocks. I also tried using nn.ReLU instead of GeneralReLU we’ve been using. I found out that they both have the same accuracy, but nn.ReLU trained faster. I guess they have the same accuracy because of the batch norm.
I made a pixel swap data augmentation. it uses the exact same pixels as the original, so the pixel statistics of the images should be preserved (mean and stdev). It is pretty slow since, there is an inner loop in python, so I made it swap blocks of 3x3 to speed it up a bit.
def pixel_swap(xb, nswaps=4):
nrows = xb[0].shape[-2] - 4
ncols = xb[0].shape[-1] - 4
idxs = [(int(random.random()*nrows), int(random.random()*ncols), int(random.random()*nrows), int(random.random()*ncols))
for _ in range(nswaps)]
for x in xb:
for (dtx, dty, stx, sty) in idxs:
tmp = x[:,dtx:dtx+4, dty:dty+4]
x[:, dtx:dtx+4, dty:dty+4] = x[:, stx:stx+4, sty:sty+4]
x[:, stx:stx+4, sty:sty+4] = tmp
return xb
Not sure if its only me but my google colab keeps crashing as System RAM gets full, although GPU RAM stays well below threshold, I have tried lowering batch size and clearing cuda memory often, yet still crashes.
Up to this lesson in the fastAI Part2 course, I’ve been running the lessons’ jupyter notebooks on my 5-year old, intel-based Macbook Pro (pytorch does not run on the old gpus on this laptop) with acceptable performance when running training/fitting in the lesson notebooks.
However, each of the the learn.fit() steps in 14_augment.ipynb is now taking over 30 minutes on my MBP - too slow for my taste.
After considering and performing some quick hands-on with Google Colab (it’s hard to get the environment right to work with fastAI P2 notebooks) and MS Azure (I think I can get it to work - however, even though Azure ML Workspace is free, you need to provision a VM (with GPU) to support the workspace and VM is NOT free (well, at least my free trial period for Azure ran out a long time ago while using Azure for some other things unrelated to ML/AI), I am happy to report that I was able to get a freemium access to Lightning.ai and start running 14_augment.ipynb successfully. learn.fit() in that notebook each takes about 3 minutes to run on 1 A10G GPU (free).
There is a monthly $15 free credit for the ‘freemium’ tier. It might be enough to do the fastai P2 course at the pace I’m going through the lessons – we shall see. I’m pretty happy with what I see so far - so if I have to splurge for a paid subscription on lightning.ai, I might be happy to do it.
2nd day of using lightnin.ai freemium account for running 14_augment.ipynb:
One disadvantage of the freemium account is that if your session is idle for more than 10 minutes, the session ‘goes to sleep’. It means that all runtime RAM (ie, values stored in the variables in the already executed notebook cells are lost) is lost after waking up from the sleep. Things like files and install python packages in your ‘studio’ persist, though.
In my case, I was half way through running the cells in my copy of 14_augment.ipynb yesterday. Today when I want to continue with following 14_augment.ipynb, I had to restart the kernel on GPU and rerun the cells from the beginning. I’m getting to the part of the notebook where different models are being fitted and each fit runs 10 to 50 epochs. I burned through about $7 of free credits so far today. $15 of free credits are not going to last long…
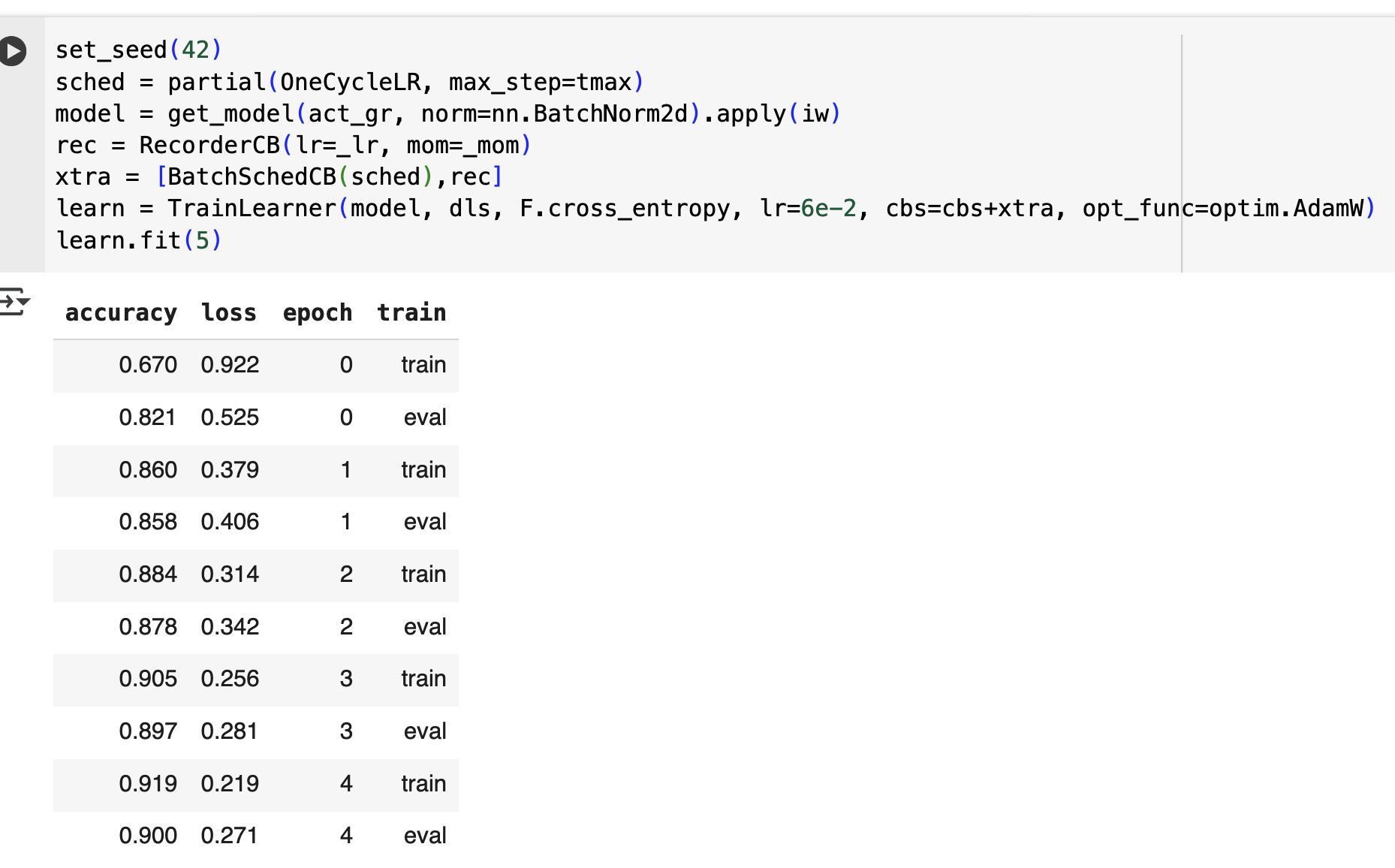
Just Completed the homework given for this lesson, I believe it is the simplest implementation while still satisfying the rules for it being correct (works with BaseSchedCB).