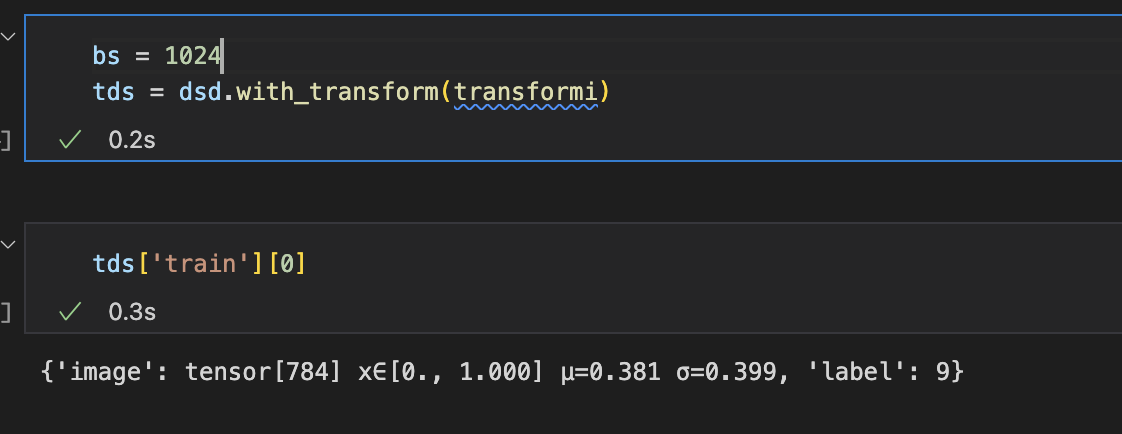
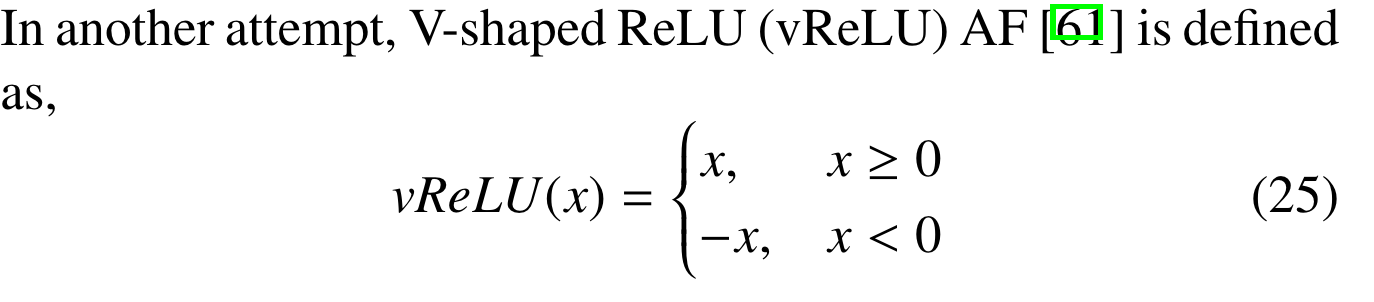So, after seeing the GeneralReLU today, I had a brilliant idea that I’m sure many other people had before me.
If we have this leak hyper-parameter, why don’t we make it part of the training and let the optimizer find the proper value?
class PGeneralRelu(nn.Module):
def __init__(self, leak=0., sub=0., maxv=None):
super().__init__()
self.leak = nn.Parameter(torch.tensor(leak))
self.sub = sub
self.maxv = maxv
def forward(self, x):
# x = F.leaky_relu(x,self.leak) if self.leak is not None else F.relu(x)
x = torch.max(x * self.leak, x)
x.sub_(self.sub)
if self.maxv is not None: x.clamp_max_(self.maxv)
return x
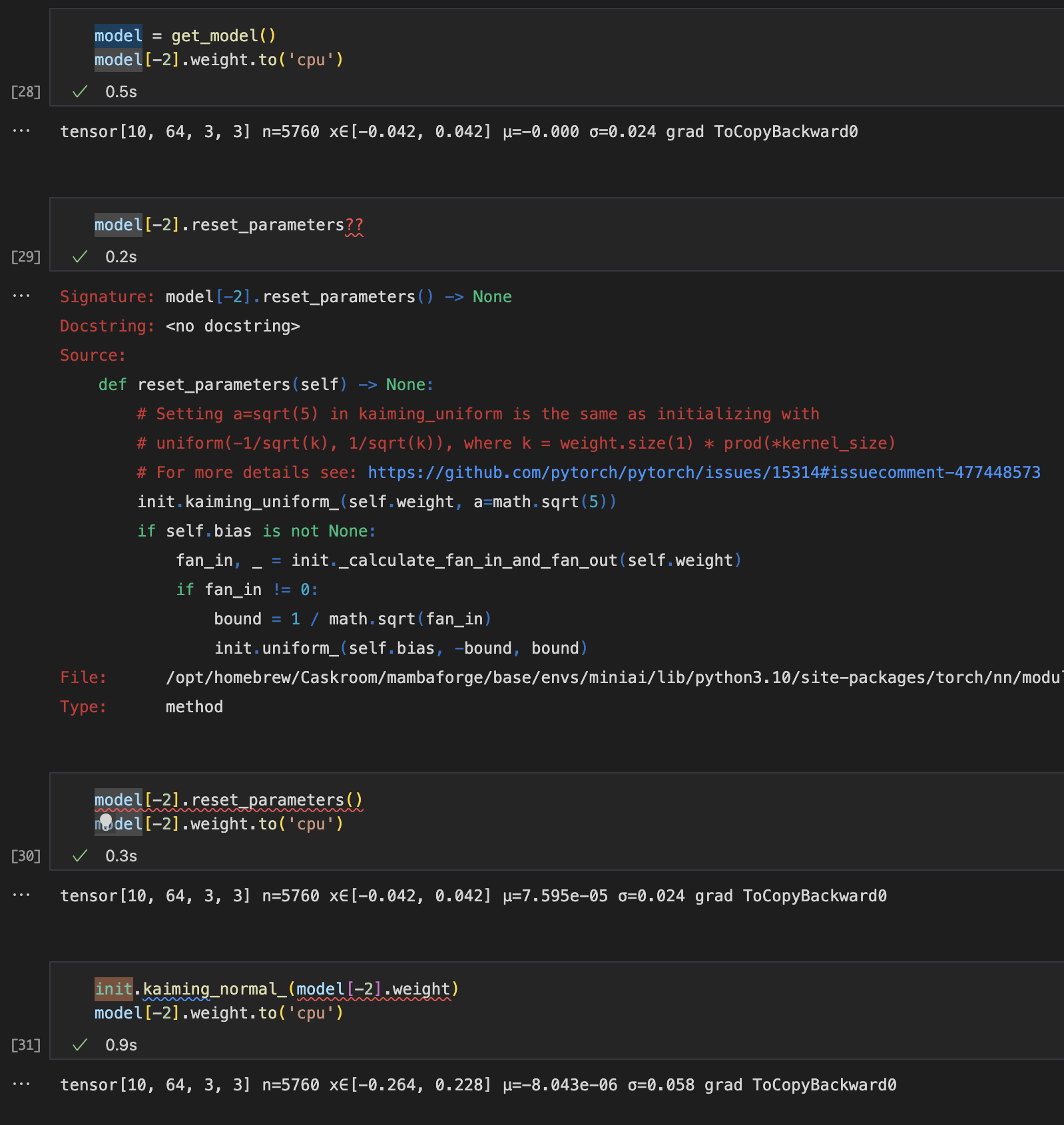
And it indeed does work and finds some values for leak:
for m in model.modules():
if isinstance(m, PGeneralRelu): print(m.leak.item())
0.04131656885147095
0.13582824170589447
-0.10154463350772858
-0.16783204674720764
What’s interesting, for the last 2 layers, the leak is actually negative, so the function looks like this:
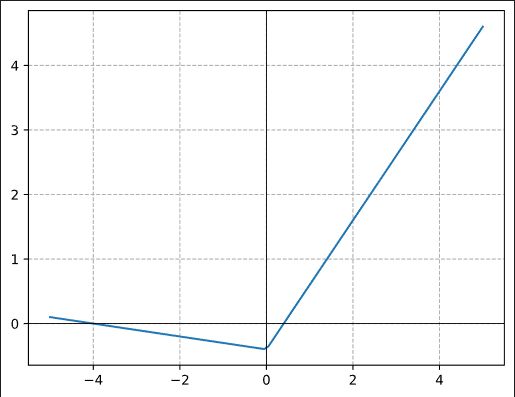
But of course, the reason we never hear about this idea is that it does not seem to work. The results are close to the normal GeneralReLU(0.1, 0.4), but never quite reach it.
I’ve tried a variant with learnable sub too, but it’s very unstable if the layer before the non-linearity has a bias term, as the sub and the bias end up fighting and growing opposite ways until numeric instability kicks in.
Any idea why it does not seem to improve the results, and also, why the last 2 layers learn a non-monotonic activation?