Lesson 20 Homework.
First Approach
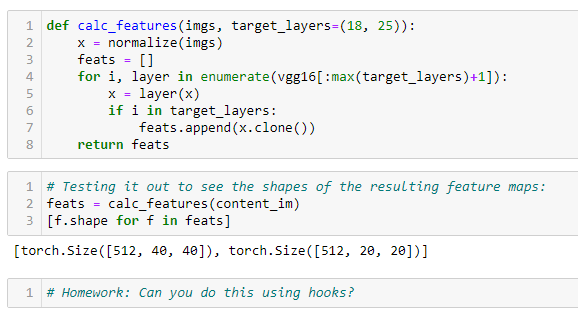
A content loss class with a method for feature calculation using hooks.
def register_feature(hook, mod, inp, outp):
hook.feature = outp
class ContentLossToTargetWithHooks():
def __init__(self, feat_model, target_im, target_layers=(18, 25)):
fc.store_attr()
self.feat_modules = [feat_model[layer] for layer in target_layers]
self.target_features = self.get_features(target_im)
def get_features(self, image, init=True):
with Hooks(self.feat_modules, register_feature) as hooks:
f = torch.no_grad() if init else fc.noop
f(self.feat_model)(normalize(image))
return [h.feature for h in hooks]
def __call__(self, input_im):
self.input_features = self.get_features(input_im, init=False)
loss = sum((f1-f2).pow(2).mean() for f1, f2 in
zip(self.input_features, self.target_features))
return loss
loss_function_perceptual = ContentLossToTargetWithHooks(
vgg16, content_im, target_layers=(1, 6, 18))
Second Approach
A class that can be used for content and style loss, and the functions for calculating features or grams defined outside.
def register_feature(hook, mod, inp, outp):
hook.feature = outp
def get_features(feat_modules, image, init=True):
with Hooks(feat_modules, register_feature) as hooks:
f = torch.no_grad() if init else fc.noop
f(feat_model)(normalize(image))
return [h.feature for h in hooks]
def get_grams(feat_modules, image, init=True):
return L(torch.einsum('chw, dhw -> cd', x, x) / (x.shape[-2]*x.shape[-1])
# 'bchw, bdhw -> bcd' if batched
for x in get_features(feat_modules, image, init=init))
class LossToTargetWithHooks:
def __init__(self, feat_model, image, calc_func=get_features,
target_layers=(18, 25)):
fc.store_attr()
self.feat_modules = [feat_model[layer] for layer in target_layers]
self.target_values = self.calc_func(self.feat_modules, image)
def __call__(self, input_im):
self.input_values = self.calc_func(
self.feat_modules, input_im, init=False)
loss = sum((f1-f2).pow(2).mean() for f1, f2 in
zip(self.input_values, self.target_values))
return loss
style_loss = LossToTargetWithHooks(
vgg16, style_im, calc_func=get_grams, target_layers=(1, 6, 11, 18, 25))
content_loss = LossToTargetWithHooks(
vgg16, content_im, target_layers=(1, 6, 25))

 ,
,